

Pandasで大量のデータを扱う中で、次のような課題を感じたことはありませんか。
・Pandasの処理速度やメモリ消費に不満がある
・より高速で省メモリなデータフレーム処理ツールを探している
そこで注目したいのが、高速・省メモリを特徴とする次世代データ処理ライブラリ「Polars」です。
Polarsは、Pandasの処理速度やメモリ使用量に課題を感じている方にとって、有力な代替手段となります。そこでこの記事では、
・Polarsの基本的な特徴と概要
・Pandasとの性能比較や違い
・Polarsの導入方法と基本操作
・PolarsとPandasの実際の処理速度の違い
についてわかりやすく解説します。
公開日: 2025年8月4日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >INDEX
Polarsとは?
Polarsは、Rustで開発された次世代のデータフレームライブラリで、並列処理と列指向メモリ構造により、高速かつ省メモリな処理を実現しています。PandasがPythonやNumPyの上に構築されているのに対し、Polarsは完全にRustで実装されており、基盤としてApache Arrowを採用しています。

出典:Polars — DataFrames for the new era
メモリ効率が高く、文字列や複雑なデータ型の処理も効率的に行うことができます。また、Polarsはマルチスレッド(並列処理)によって、大規模データでの高速処理が可能です。実際のベンチマークでも、Pandasと比較して「5~10倍の高速化」や「2~4倍の低メモリ使用量」といった結果が報告されています。
エンジニアが抱えるパフォーマンスやリソースの課題を解決する選択肢として、Polarsが注目されています。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >Polarsの特徴
ここでは、Polarsがもつ主要な特徴について、簡単にまとめて紹介します。
高速で大規模データを扱える
Polarsは、Pandasよりも大規模データの高速処理が可能です。Polarsが公開しているベンチマーク(5億件のeコマースデータを処理したベンチマーク)では、Pandasが4.5時間かかったのに対し、Polarsは1.2時間と、処理時間が大幅に短縮されています。
さらに、メモリやエネルギー消費も、最大で8倍の効率化や63%の消費削減といった実績が報告されています。
Pandasについて詳しくは以下の記事をご覧ください。
▶【Pandas入門】Pythonのデータ分析ライブラリ「Pandas」を解説!
複数言語で利用可能
PolarsはPythonだけでなく、複数の言語向けにAPIを提供しています。Rustで実装されたコア部分により、一貫したパフォーマンスが得られる点が特徴です。
PythonやRustについては以下の記事をご覧ください。
▶Python(パイソン)とは?人気プログラミング言語の特徴・活用事例を解説!
▶【Rust入門】概要や環境構築、プログラムの作成方法を詳しく解説!
他ツールとの連携が豊富
PolarsはArrowフォーマットに対応しているため、ParquetやCSV、IPCなどと互換性があります。また、dbtやDuckDB、データ基盤など他ツールとの統合も進んでおり、ETLパイプラインへの組み込みも容易です。
Lazy evaluation(遅延評価)で無駄な処理を省く
Polarsは、遅延評価をサポートしており「.scan_csv」などのLazy APIを使うことで、処理が必要なタイミングまで遅延させられます。最終的に.collect()を呼び出すことで一括実行され、次のような最適化が自動的に適用されます。
・predicate pushdown:必要な行だけ読み込み
・projection pushdown:必要な列だけ処理する
遅延評価により、大規模データやストリーミング処理でも無駄なリソース消費を抑えつつ、効率的なデータ処理が実現できます。
PandasとPolarsとの違い・性能比較
PandasとPolarsの最大の違いは、Polarsが圧倒的な高速性を発揮する点です。実際のベンチマークでは、PolarsはPandasに比べて処理速度が大幅に向上するケースが報告されています(データ量・処理内容・環境に依存)。特に、大規模データの集計やログ処理、CSVファイルの連結といった場面で処理速度の差が顕著に現れています。
HPCログの処理では、Pandasで30分かかった作業がPolarsでは約3分で完了し、CSVの連結もPandasの40秒に対しPolarsは10秒と大幅に短縮されました。
また、メモリ使用量も優れており、PolarsはPandasに比べてメモリ使用量を削減できる場合があります(条件により変動)。処理速度については、この記事でも後ほど検証しているため、ご参考ください。
ただし、小規模データの場合は処理速度の差が小さく、既存のワークフローではPandasのほうが使いやすいという意見もあります。
▼【応用編】PolarsとPandasの処理方法や処理速度の違いを実践
この高速性を支える中核技術の一つが「遅延評価(Lazy API)」です。実行前にクエリ全体を最適化し、無駄なデータ読み込みや計算を自動的に排除するため、手動での調整なしに常に最短ルートで処理が実行されます。この自律最適化により、処理速度だけでなく、データ処理基盤の品質向上にもつながるでしょう。
ただし、小規模データの場合は処理速度の差が小さく、既存のワークフローではPandasのほうが使いやすいという意見もあります。
Kaggle Master が教える Polars データ分析入門〜実践的なハンズオンで大規模なデータ処理を加速!〜

Kaggler Master の称号を持ち Polars 本の著者でもある講師が Python の超高速・軽量ライブラリ『Polars』の基礎から実践まで徹底解説!&ハンズオンによるコード解説!
\無料でプレビューをチェック!/
講座を見てみる【基本編】Polarsの導入と基本操作
ここからは、実際にPolarsに触れ、インストール方法から基本操作、Pandasからの書き換え方法について解説します。
一つずつ見ていきましょう。
Python環境でのインストール方法
はじめに仮想環境を作成し、pipでPolarsをインストールします。

pipで簡単にインストールすることが可能です。
|
1 |
pip install polars |

Conda環境であれば、次のコマンドでインストールできます。
|
1 |
conda install -c conda-forge polars |
PolarsはRustで実装され、Pythonへ統合されているため、ネイティブに近いパフォーマンスが得られます。
基本の操作方法
基本操作として、データフレームの生成、ファイルの書き出し・読み込み、フィルタ・集計を試してみましょう。
ここからは、Pythonの対話モードで進めていきます。
今回は次のデータを準備しました。「data.csv」として作成しておき、読み込んでデータフレームとして進めていきます。
| 年齢 | 名前 | 職業 | 年収 | 都市 |
|---|---|---|---|---|
| 25 | 佐藤 | エンジニア | 450 | 東京 |
| 32 | 鈴木 | デザイナー | 380 | 大阪 |
| 45 | 高橋 | マネージャー | 700 | 名古屋 |
| 28 | 田中 | エンジニア | 480 | 東京 |
| 37 | 伊藤 | 営業 | 520 | 大阪 |
| 41 | 渡辺 | マーケター | 460 | 名古屋 |
| 29 | 山本 | エンジニア | 470 | 福岡 |
| 34 | 中村 | デザイナー | 390 | 東京 |
| 50 | 小林 | マネージャー | 720 | 大阪 |
| 26 | 加藤 | 営業 | 510 | 福岡 |
| 38 | 吉田 | マーケター | 440 | 名古屋 |
| 43 | 佐々木 | エンジニア | 460 | 東京 |
| 31 | 松本 | デザイナー | 400 | 大阪 |
| 27 | 井上 | 営業 | 530 | 福岡 |
| 40 | 木村 | マネージャー | 710 | 名古屋 |
はじめにPolarsをインポートし、CSVのデータをデータフレームとして格納します。
|
1 2 |
import polars as pl df = pl.read_csv("data.csv") |

Pandasと同じように、フィルタや集計ができます。
まずは「年齢が30歳以上」の条件でフィルタし、年齢順にソートして出力してみましょう。
|
1 |
df.filter(pl.col("年齢")>=30).sort("年齢") |

ソートの対象を「年収」に変更し、降順に出力する場合は次のとおりです。
|
1 |
df.filter(pl.col("年齢")>=30).sort("年収", descending=True) |

続いて、職業別の平均年収を集計してみましょう。
以下を実行することで職業別にグループ分けされ、年収の平均が算出できました。
|
1 |
df.group_by("職業").agg(pl.col("年収").mean()) |

このようにPolarsでもPandasと大きく変わることなく操作することができます。
Polarsの2つの動作モード(Lazy/Eager)
PolarsはLazyとEagerの2つの動作モードを備えています。
・Lazyモード:クエリ(処理内容)が必要とされるまで評価されず、最後にまとめて実行する
・Eagerモード:各ステップが順次実行され、中間結果が返される
前述の基本操作では、Eagerモードで動作させていました。
Lazyモードは動作を最適化し、メモリとCPUの負荷を軽減するため、Lazyモードの利用が推奨されています。モードの切り換えは、ファイルを読み込む際に「scan_csv」を使用すればLazyモード、「read_csv」を使用すればEagerモードとなります。
「年齢が30歳以上の職業別の年収平均」をEager/Lazyモードそれぞれで集計してみましょう。
【Eagerモード】
|
1 2 |
df = pl.read_csv("data.csv") df.filter(pl.col("年齢")>=30).group_by("職業").agg(pl.col("年収").mean()).sort("職業") |

【Lazyモード】
|
1 2 3 4 5 6 7 8 |
query = ( pl.scan_csv("data.csv") .filter(pl.col("年齢")>=30) .group_by("職業") .agg(pl.col("年収").mean()) ) query.collect().sort("職業") |

どちらも得られる結果は同じですが、前述のとおりメモリとCPUの負荷が軽減されるため、Lazyモードの利用が推奨されます。そのほかの使い分けとしては、クエリが定まっている場合はLazyモード、クエリが定まっていない・中間結果を確認したい、という場合にはEagerモードが適しています。
Pandasからの移行・書き換え方法
基本的には、「import pandas as pd」を「import polars as pl」に変更し、エイリアスを適宜修正していくことで対応できます。「pd.read_csv」→「pl.read_csv」のようなイメージです。
Pandas-code.py
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd df = pd.read_csv("data.csv") filtered = df[df["年齢"] >= 30] result = filtered.groupby("職業")["年収"].mean().reset_index() print(result) |
Polars-code.py
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import polars as pl df = pl.read_csv("data.csv") result = ( df.filter(pl.col("年齢") >= 30) .group_by("職業") .agg(pl.col("年収").mean().alias("年収_平均")) ) print(result) |
比較しても大きな違いはないといえます。Polarsでは列名(column)に別名(alias)を付けられるため、より意味が伝わる名前に変更しました。

APIや書式がPandasと似ているため、移行自体は比較的スムーズです。ただし、groupbyはgroup_byに変わっているなど、文字列・日付処理の違いに注意が必要です。
そのため、移行時にはAPI差異を確認しながら進めることが重要です。
【応用編】PolarsとPandasの処理方法や処理速度の違いを実践
ここからは、PolarsとPandasで各処理を実施し、処理速度を計測した結果を紹介します。今回は3,000万行のデータを用意し、それらをフィルタリング・グループ化・ソートする際の違いについて、コードを交えながら解説します。
なお、3,000万行のCSVファイルは約2GB程度になります。ご自身で試す際は、容量にご注意ください。
CSVファイルを読み込んだ状態から始めていきます。
データのフィルタリング
まずはデータのフィルタリングです。
結論として、PandasはPolarsと比べて2倍~7倍ほどの処理速度となりました。特にフィルタリングの条件が複雑になるほど差が大きくなることがわかります。
| 処理内容 | 処理時間(Pandas) | 処理時間(Polars) | 速度比(Polars) |
|---|---|---|---|
| valueが50より大きい値をフィルタリング | 0.696秒 | 0.266秒 | 2.6倍 |
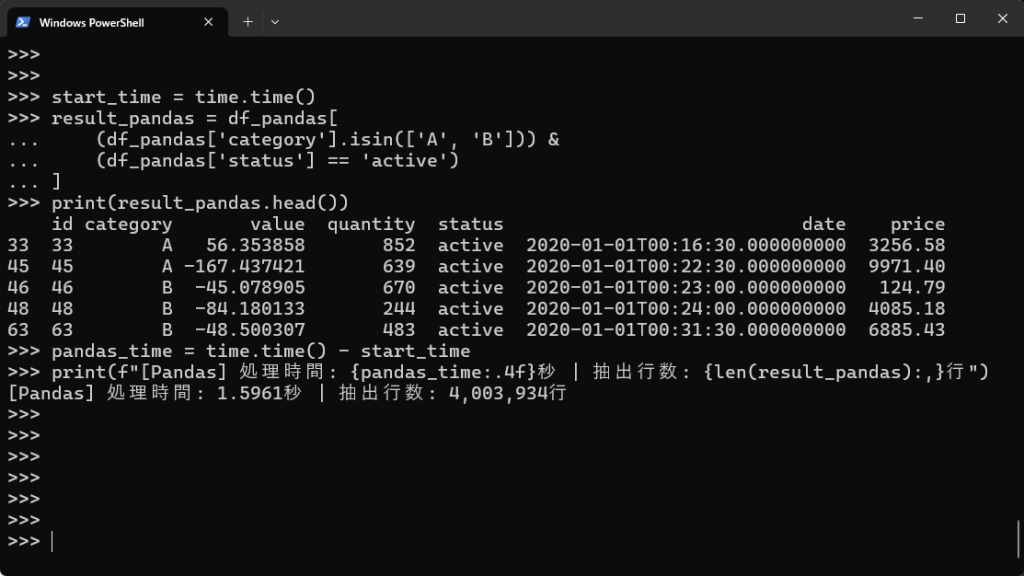
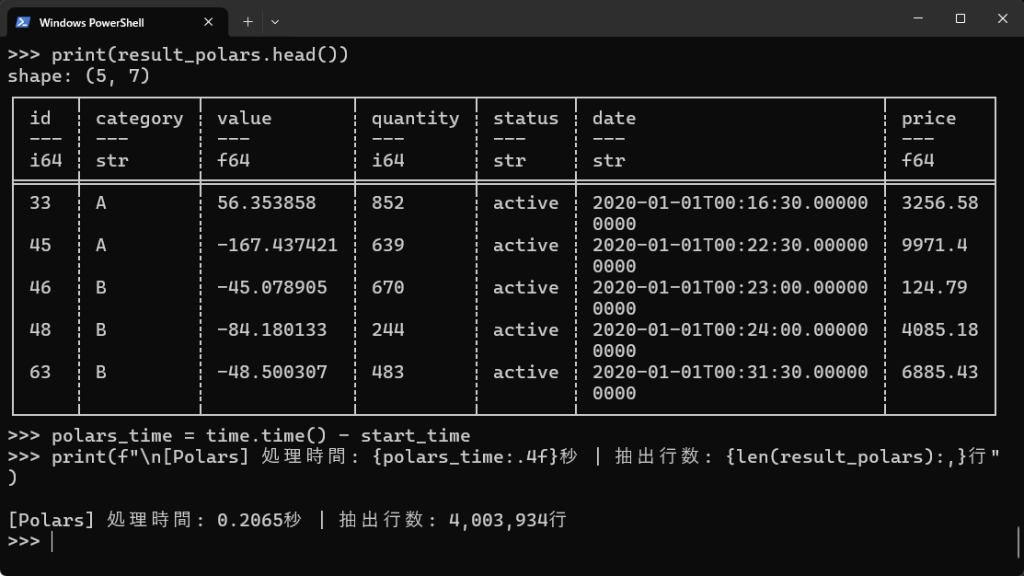
| categoryがAまたはB、かつstatusがactiveのものをフィルタリング | 1.5961秒 | 0.2065秒 | 7.7倍 |
以下は、実際のコードと実行結果です。
【コード】
|
1 2 3 4 5 6 7 |
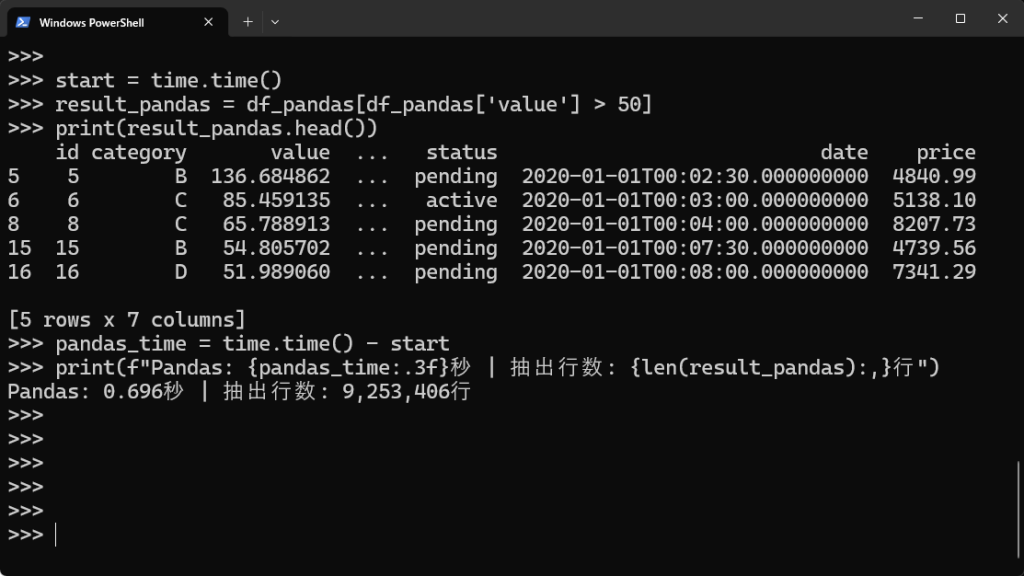
# Pandasでのデータフィルタリング(valueが50より大きいもの) start = time.time() result_pandas = df_pandas[df_pandas['value'] > 50] print(result_pandas.head()) pandas_time = time.time() - start print(f"Pandas: {pandas_time:.3f}秒 | 抽出行数: {len(result_pandas):,}行") |
【実行結果】
【コード】
|
1 2 3 4 5 6 7 |
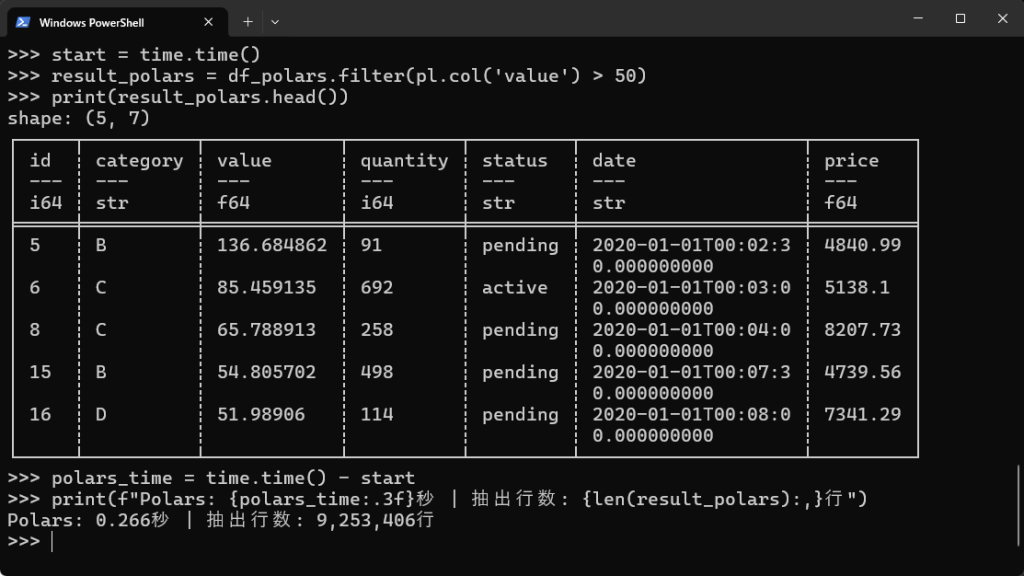
# Polarsでのデータフィルタリング(valueが50より大きいもの) start = time.time() result_polars = df_polars.filter(pl.col('value') > 50) print(result_polars.head()) polars_time = time.time() - start print(f"Polars: {polars_time:.3f}秒 | 抽出行数: {len(result_polars):,}行") |
【実行結果】
こちらは、より条件を複雑にしたコードと実行結果となります。
【コード】
|
1 2 3 4 5 6 7 8 9 10 |
# Pandasでのデータフィルタリング(categoryとstatus) start_time = time.time() result_pandas = df_pandas[ (df_pandas['category'].isin(['A', 'B'])) & (df_pandas['status'] == 'active') ] print(result_pandas.head()) pandas_time = time.time() - start_time print(f"[Pandas] 処理時間: {pandas_time:.4f}秒 | 抽出行数: {len(result_pandas):,}行") |
【実行結果】
【コード】
|
1 2 3 4 5 6 7 8 9 10 |
# Polarsでのデータフィルタリング(categoryとstatus) start_time = time.time() result_polars = df_polars.filter( (pl.col('category').is_in(['A', 'B'])) & (pl.col('status') == 'active') ) print(result_polars.head()) polars_time = time.time() - start_time print(f"\n[Polars] 処理時間: {polars_time:.4f}秒 | 抽出行数: {len(result_polars):,}行") |
【実行結果】
データのグループ化
続いて、データのグループ化処理の速度を見ていきましょう。
こちらもPandasよりもPolarsのほうが2~3倍程度処理が早いという結果になりました。
| 処理内容 | 処理時間(Pandas) | 処理時間(Polars) | 速度比(Polars) |
|---|---|---|---|
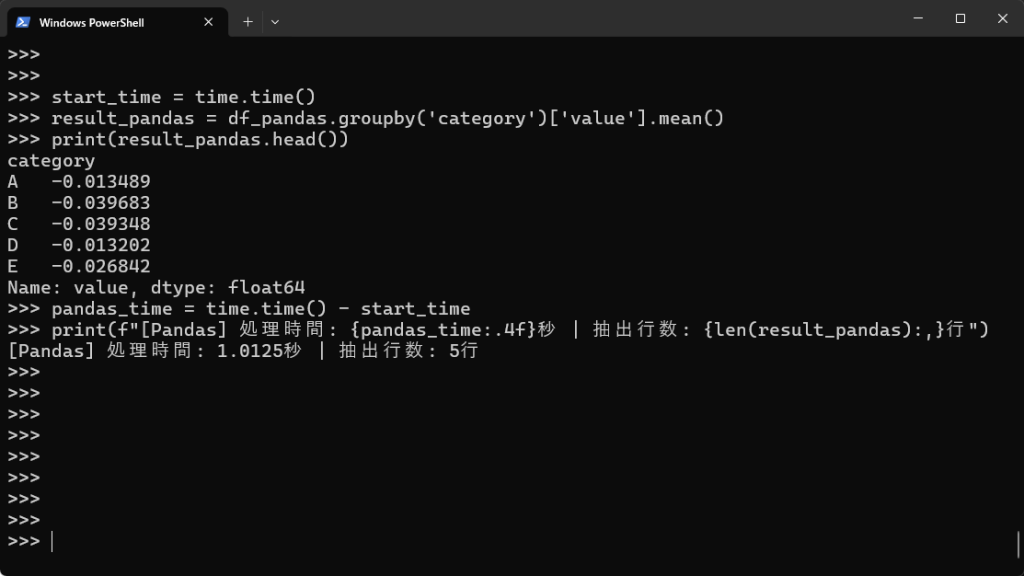
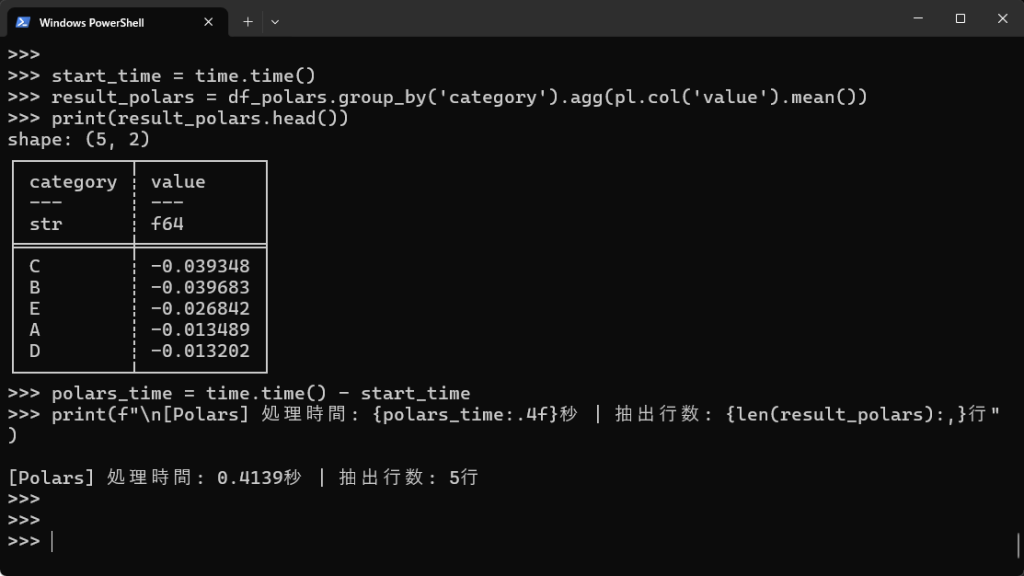
| categoryでグループ化してvalueの平均を出す | 1.0125秒 | 0.4139秒 | 2.4倍 |
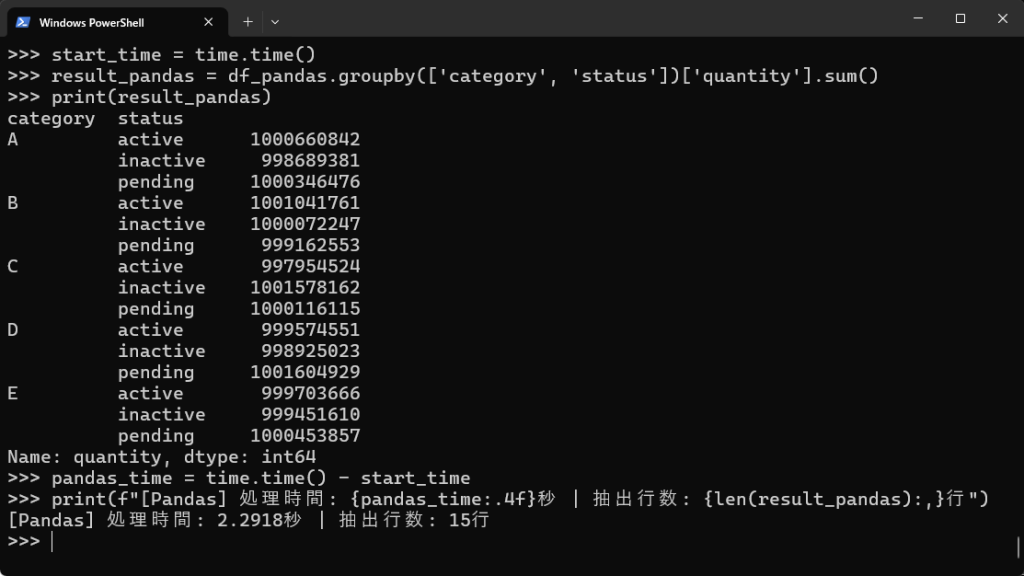
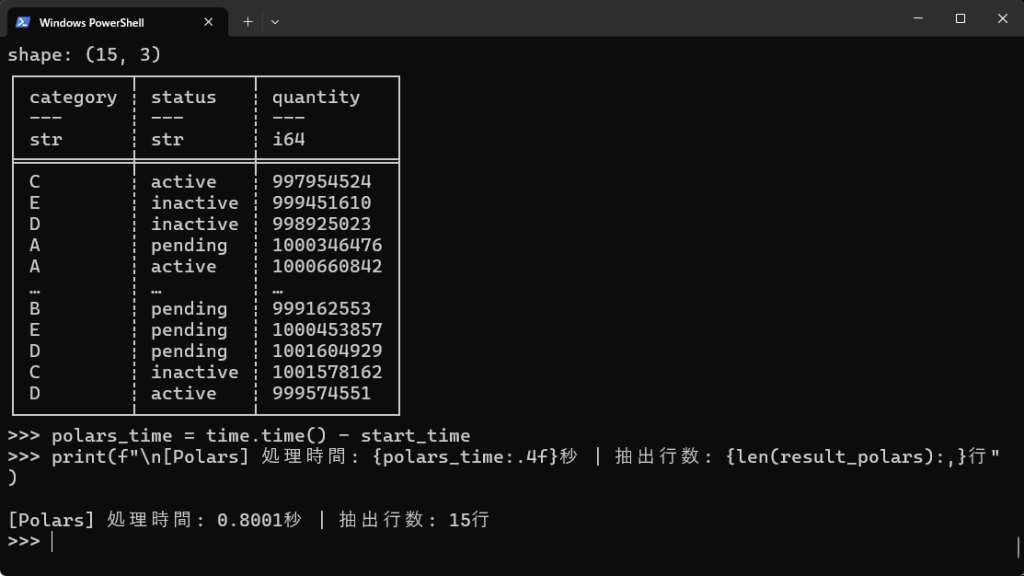
| categoryとstatusでグループ化してquantityの合計を出す | 2.2918秒 | 0.8001秒 | 2.8倍 |
以下は実際に実行したコードと実行結果です。
【コード】
|
1 2 3 4 5 6 7 |
# Pandasでのグループ化(categoryごとのvalueの平均) start_time = time.time() result_pandas = df_pandas.groupby('category')['value'].mean() print(result_pandas.head()) pandas_time = time.time() - start_time print(f"[Pandas] 処理時間: {pandas_time:.4f}秒 | 抽出行数: {len(result_pandas):,}行") |
【実行結果】
【コード】
|
1 2 3 4 5 6 7 |
# Polarsでのグループ化(categoryごとのvalueの平均) start_time = time.time() result_polars = df_polars.group_by('category').agg(pl.col('value').mean()) print(result_polars.head()) polars_time = time.time() - start_time print(f"\n[Polars] 処理時間: {polars_time:.4f}秒 | 抽出行数: {len(result_polars):,}行") |
【実行結果】
ここからは、グループ化の条件をより複雑にした場合のコードと実行結果です。
【コード】
|
1 2 3 4 5 6 7 |
# Pandasでのグループ化(categoryとstatusごとのquantityの合計) start_time = time.time() result_pandas = df_pandas.groupby(['category', 'status'])['quantity'].sum() print(result_pandas) pandas_time = time.time() - start_time print(f"[Pandas] 処理時間: {pandas_time:.4f}秒 | 抽出行数: {len(result_pandas):,}行") |
【実行結果】
【コード】
|
1 2 3 4 5 6 7 8 9 |
# Polarsでのグループ化(categoryとstatusごとのquantityの合計) start_time = time.time() result_polars = df_polars.group_by(['category', 'status']).agg( pl.col('quantity').sum() ) print(result_polars) polars_time = time.time() - start_time print(f"\n[Polars] 処理時間: {polars_time:.4f}秒 | 抽出行数: {len(result_polars):,}行") |
【実行結果】
並べ替え(ソート)処理
計測の最後に、ソート処理を実行します。
ソートは体感できるほど差が出ました。Pandasに比べてPolarsは4~6倍ほど処理が早いです。
| 処理内容 | 処理時間(Pandas) | 処理時間(Polars) | 速度比(Polars) |
|---|---|---|---|
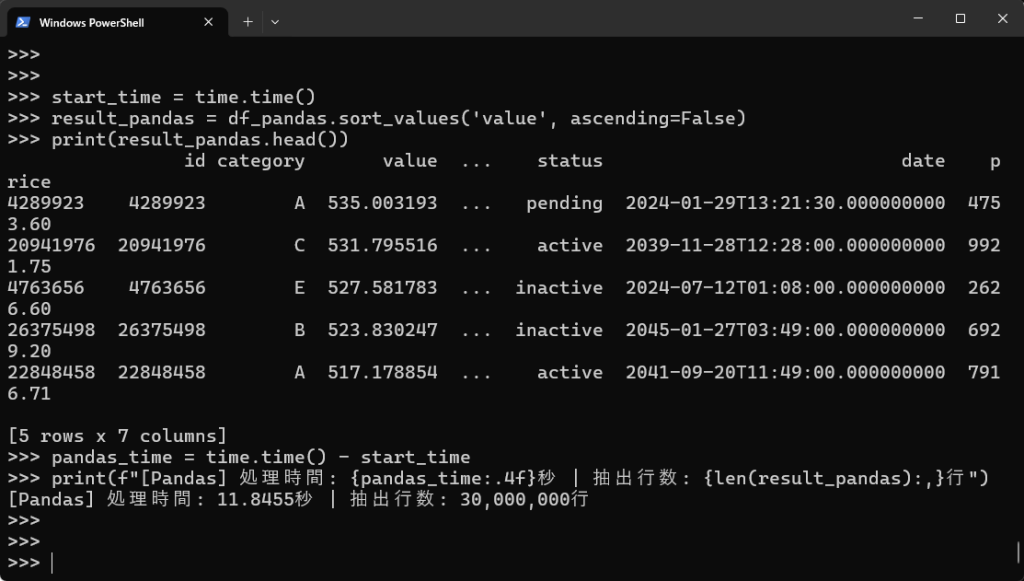
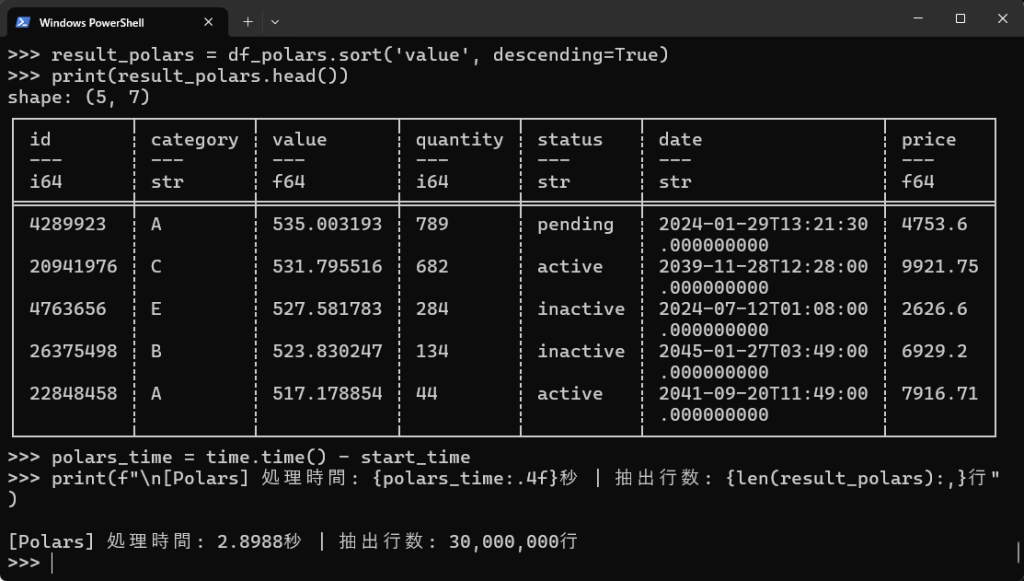
| valueの降順にソート | 11.8455秒 | 2.8988秒 | 4.0倍 |
| categoryの昇順ソート後、valueの降順にソート | 43.6667秒 | 6.4828秒 | 6.7倍 |
3,000万行をソートするコードと実行結果です。
【コード】
|
1 2 3 4 5 6 7 |
# Pandasでのソート(valueで降順ソート) start_time = time.time() result_pandas = df_pandas.sort_values('value', ascending=False) print(result_pandas.head()) pandas_time = time.time() - start_time print(f"[Pandas] 処理時間: {pandas_time:.4f}秒 | 抽出行数: {len(result_pandas):,}行") |
【実行結果】
【コード】
|
1 2 3 4 5 6 7 |
# Polarsでのソート(valueで降順ソート) start_time = time.time() result_polars = df_polars.sort('value', descending=True) print(result_polars.head()) polars_time = time.time() - start_time print(f"\n[Polars] 処理時間: {polars_time:.4f}秒 | 抽出行数: {len(result_polars):,}行") |
【実行結果】
2段階でソートした結果は、よりPolarsの処理速度の早さが際立つ結果となりました。
【コード】
|
1 2 3 4 5 6 7 |
# Pandasでのソート(categoryで昇順、その後valueで降順ソート) start_time = time.time() result_pandas = df_pandas.sort_values(['category', 'value'], ascending=[True, False]) print(result_pandas.head()) pandas_time = time.time() - start_time print(f"[Pandas] 処理時間: {pandas_time:.4f}秒 | 抽出行数: {len(result_pandas):,}行") |
【実行結果】
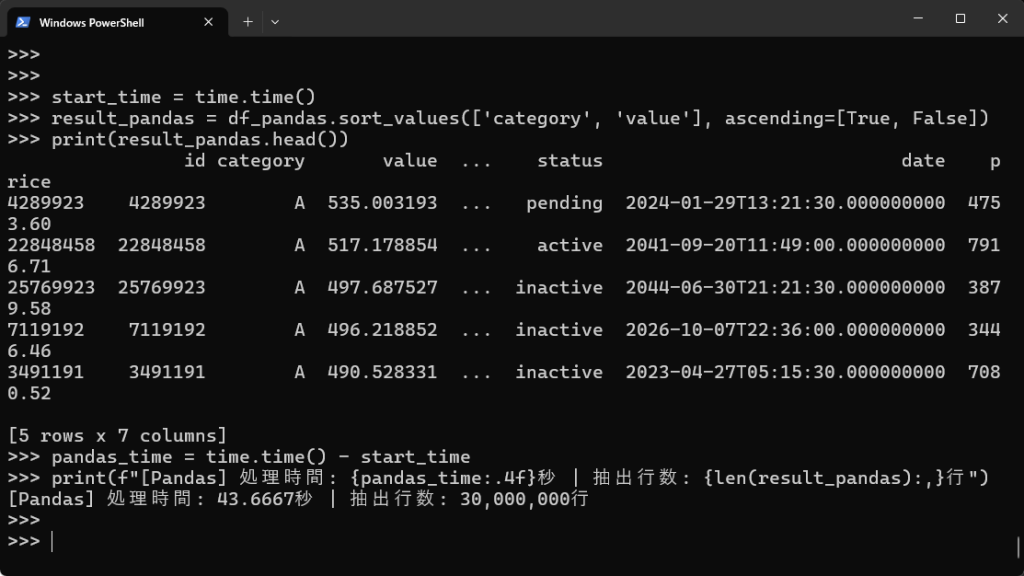
【コード】
|
1 2 3 4 5 6 7 |
# Polarsでのソート(categoryで昇順、その後valueで降順ソート) start_time = time.time() result_polars = df_polars.sort(['category', 'value'], descending=[False, True]) print(result_polars.head()) polars_time = time.time() - start_time print(f"\n[Polars] 処理時間: {polars_time:.4f}秒 | 抽出行数: {len(result_polars):,}行") |
【実行結果】
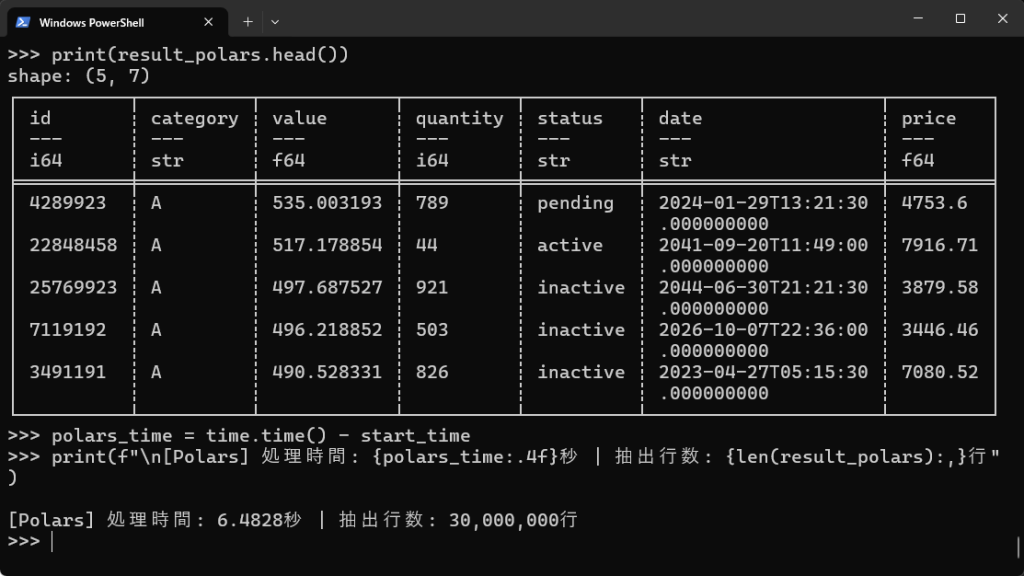
各種処理の結果のように、PandasよりもPolarsのほうが圧倒的に処理速度は早いことがわかります。
今回は3,000万行のデータで実施しましたが、より多くのデータを処理する場合には、さらにPolarsの処理速度の早さが際立つ結果になるでしょう。
Polars導入でデータ分析を加速させよう!
Polarsは、次世代データ処理に求められる高速性・省メモリ・マルチ言語対応を備えています。Pandasより大規模データに強く、複数言語や他ツールとの連携も充実しています。学習コストや一部ライブラリ未対応といった注意点はありますが、効率的なデータ分析を目指すエンジニアにとって有力な選択肢となります。
より詳しく実践的な内容を学びたい方には、Udemyの動画講座がおすすめです。
こちらの講座ではPolarsの基礎から、実践的なデータ分析までを体系的に解説しています。Polarsを迅速に習得し、実践的に学びたい方は、受講を検討してみてください。
◆Kaggle Master が教える Polars データ分析入門~実践的なハンズオンで大規模なデータ処理を加速!~
レビューの一部をご紹介
評価:★★★★★
コメント:データサイエンティストに転職したく活動をしています。その中で、いい刺激になりました。Polarsも使いこなせるように学習を進めます!
評価:★★★★★
コメント:気になっていたPolarsが基礎から学べました!(サンプルコードもあってスタートしやすかったです)実践できるデータ分析演習もあり非常に参考になります。
Polarsでデータ分析のスキルを高め、効率的にデータを処理する力を身につけましょう!

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中