PandasはPythonで利用できる、データ解析のためのライブラリです。
Pandasの特徴は、Series、DataFrame、Panelといった「ラベルを持った配列」を利用できることです。それぞれのラベルを用いてデータを操作できるほか、データ解析に利用できるさまざまな機能が用意されています。
この記事では、Pandasとは何かといった基本的な知識から、Pandasの特徴やメリット、インストールやデータ解析の方法までご紹介します。
公開日:2021年8月25日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >INDEX
Pythonで使える「Pandas」とは?何ができる?
PandasはPythonのライブラリのひとつです。Pandasには、Pythonによるプログラミングにおいて、
- データの読み込みや統計量の表示
- データのグラフ化
- データ分析
などを行う際に頻繁に使用するコードが集められています。Pandasを用いることで、これらのコーディングを効率的に行うことが可能です。
PandasはCSVやテキスト、エクセル、インターネットの株価情報等、さまざまな形式のデータを読み込むことができます。さらに、データの並べ替えや欠損値の補完などの機能も供えています。
Pythonで機械学習のプログラミングをする場合には、前処理として行う学習データの整形に、Pandasを用いることが多いです。

Pandasはオープンソース(BSDライセンス)で公開されており、無料で利用できます。BSDライセンスのもとでは、著作権表示と免責条項の明記をすれば、再利用や再配布も自由に行えます。
Pythonについて詳しく知りたい方は「Pythonとは?Pythonを使ってできること・特徴を詳しく解説!」を併せてご覧ください。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >Pandasを使うメリット
Pandasの最大のメリットは、データの読み込みや切り出し、並び替え、欠損値の補完など、データ処理に役立つさまざまな機能を利用できることです。
PandasにはDataFrameというオブジェクトが用意されています。DataFrameオブジェクトは数値だけでなくテキストにも対応しており、数値とテキストが混在しているデータにも対応しています。
また、DataFrameオブジェクトには、
- DataFrame.isnull().sum() :欠損値の確認
- DataFrame.fillna() :欠損値の補完
- DataFrame.dropna() :欠損値のある行を削除
など、欠損値を操作する関数も多数用意されています。
これらのデータは、
- read_csv() :CSV形式ファイルを読み込み
- read_excel() :Excelファイルを読み込み
- read_json() :JSON文字列を読み込み
などの関数で読み込むこともできますし、
- pandas.DataFrame() :DataFrameに引数のデータを格納
などの関数で、DataFrameに格納することができます。
統計処理に利用するデータは、CSVやExcelファイルになっていることも多いため、Pandasでデータを前処理する際に、上記のような関数がよく利用されます。
また、グラフ描画ライブラリであるMatplotlibを利用することで、DataFrameに格納したデータを
- DataFrame.hist() :ヒストグラム
- DataFrame.plot() :散布図、線グラフ
- DataFrame.bar() :棒グラフ
- DataFrame.boxplot() :箱ひげ図
などのグラフとして可視化することができます。
Matplotlibについて詳しく知りたい方は、「Pythonでグラフ描画する方法を解説。Matplotlibを使えば簡単!」も併せてご覧ください。
このようにPandasは、ほかのライブラリと連携することで、さらに便利に利用することができます。

Pandasで扱えるデータ構造をご紹介!
Pandasは、Pythonで行うデータ解析を支援するためのライブラリであり、さまざまなデータを扱います。それに伴い、PandasではSeries、DataFrame、Panelといったデータ形式が用意されています。
ここでは、各データ形式の概要について解説します。
Pandasで扱えるデータ構造①Series
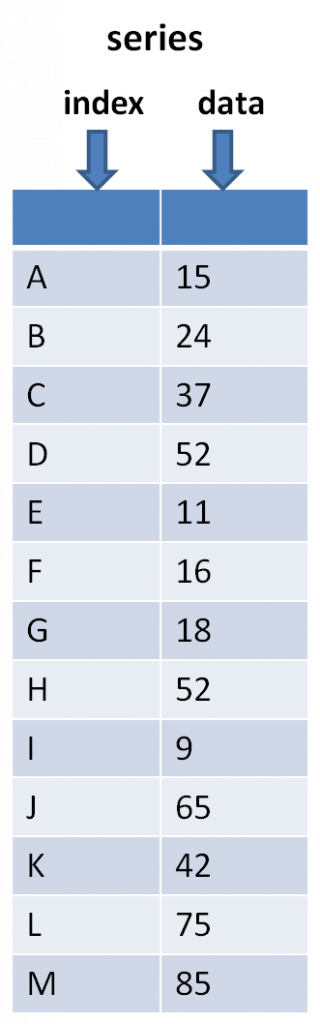
SeriesはPandasで扱うことができる1次元配列です。C言語やPythonで扱う、通常の1次元配列と違うのは、ラベルを付与できることです。
Seriesにつけられたラベルをindexと呼び、indexを用いてデータにアクセスすることができます。後述する2次元配列であるDataFrameから行(または列)データを抽出すると、Series型になります。
Pandasで扱えるデータ構造②DataFrame
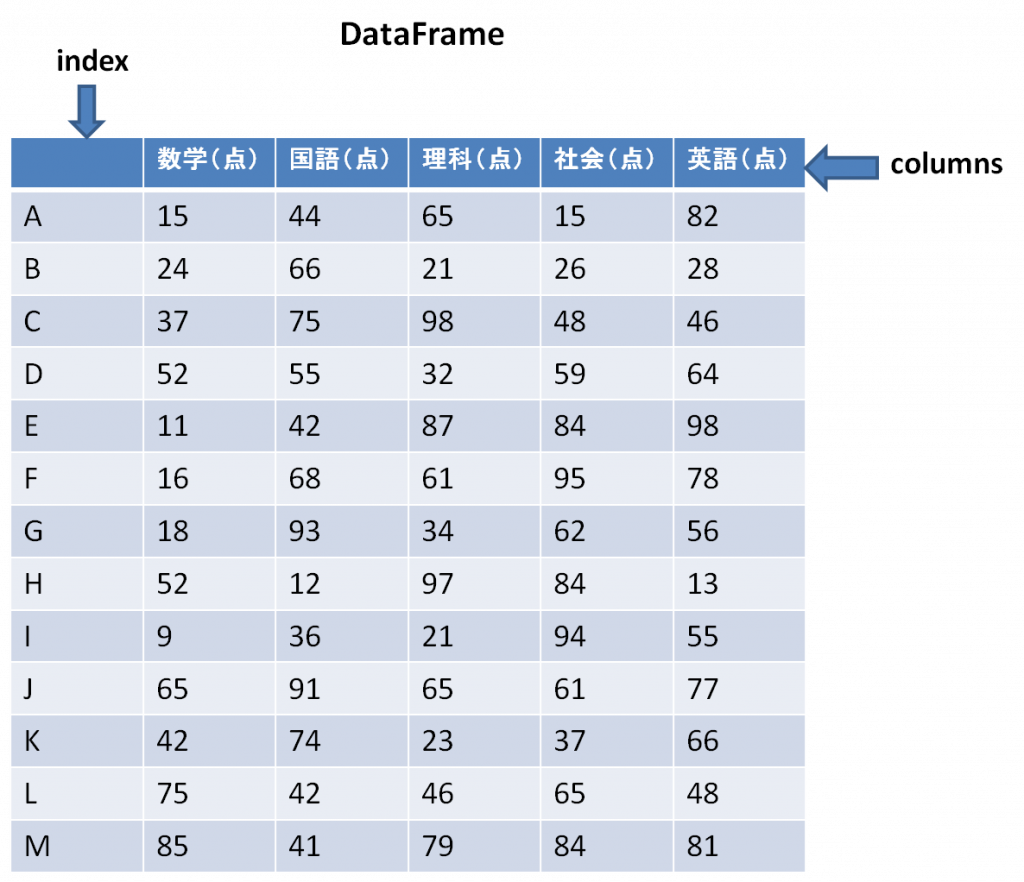
DataFrameはPandasで扱う2次元配列です。DataFrameから行や列を抽出すると、Series型の配列になります。DataFrameのデータにはindexラベルに加えて、columnsラベルを付与することができます。
indexは「行ラベル」、columnsは「列ラベル」と呼ぶこともあります。
Series型と同様に、DataFrame型ではindexやcolumnsを用いてデータにアクセスすることができます。
また、
- DataFrame.index.values()
- DataFrame.columns.values()
を用いて行数や列数を取得することができます。
- DataFrame.sort_index()
など、ラベルによりソートするような関数も用意されています。
Pandasで扱えるデータ構造③Panel
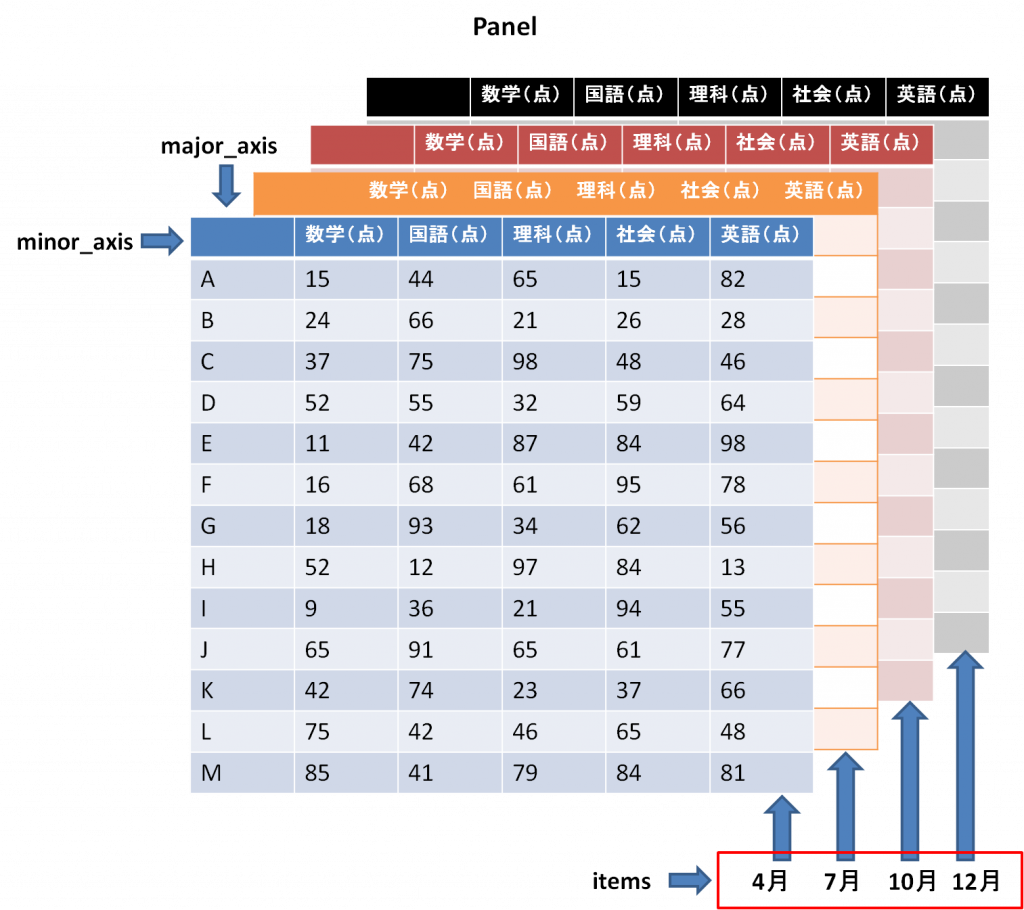
PanelはPandasで扱うことができる3次元配列です。Panelはitems、major_axis、minor_axisの3つのラベルがあります。DataFrameでindex、columnsに対応するのがmajor_axis、minor_axisです。
3次元配列は直感的に操作しづらく、使用頻度は低いですが、時系列データなどを扱う際にはよく利用されます。
Pandasをインストールしてみよう
Pandasを利用するには、Pandasをインストールする必要があります。Pandasのインストールには直接インストールする方法と、Anacondaなどのディストリビューションを利用する方法があります。
既にPythonを学習しており、開発環境がある程度整っているなら、コマンドラインで以下のように入力すれば、Pandasを単体でインストールすることができます。
|
1 |
pip install pandas |
Python初学者で、これからもPythonを利用してプログラミングをする方には、Anacondaなどのディストリビューションをインストールするのがおすすめです。
ディストリビューションとは、目的に応じたプログラムを集めて、簡単に環境構築できるようにまとめたものです。
Anacondaにはさまざまなパッケージや仮想環境マネージャが付属されており、Pandas以外にも
- NumPy
- SciPy
- Matplotlib
- Scikit-Learn
- Jupyter
などの代表的なライブラリも併せて環境構築できます。
Anacondaでライブラリのインストールをする場合は、「Environments」を開き、「Not installed」の検索ボックスに目的のライブラリ(この場合はPandas)を入力して、「Apply」をクリックします。
Pandasの関数やオブジェクトを利用する場合は、プログラム中でpandasをインポートする必要があります。
Anacondaについてより詳しく知りたい方は「AnacondaでPythonの環境構築!概要~インストール方法まで解説」をご覧ください。
Pandasを使ってデータ分析をしてみよう!順を追って解説
以下では、Pandasの基本的な使い方についてまとめます。
Pandasを使用する場合は、プログラム冒頭に
|
1 |
import pandas as pd |
と記述してインポートする必要があります。pdの部分は任意ですが、Pandasを用いる場合は、慣習的にpdとするのが一般的です。
ここではpdという名前でPandasを呼び出すように記述しています。
DataFrameオブジェクトの作成
| A | B | |
| a | 1 | 2 |
| b | 3 | 4 |
| c | 5 | 6 |
| d | 7 | 8 |
以上のようなDataFrameオブジェクト「df」を生成する場合は、
|
1 2 3 4 |
df = pd.DataFrame( { ‘A’ : pd.Series( [ 1, 3, 5, 7 ], index = [ a, b, c, d ] ), ‘B’ : pd.Series( [ 2, 4, 6, 8 ], index = [ a, b, c d ] ) } ) |
のように記述します。
CSVファイルを読み込む場合は、
|
1 |
df = pd.read_csv( ‘CSVファイルのパス’, sep = ‘ , ‘ ) |
のように記述します。この場合は「,」を区切りにしてファイルを読み込みます。
データの取り出し
特定の列を処理したい場合には、以下のように記述します。
|
1 |
df[ ‘A’ ] |
これで「A」列のデータについて扱うことができます。
最初や最後の2行を表示したい場合は、以下のように記述します。
|
1 2 |
df.head( 2 ) df.tail( 2 ) |
並び替え・結合
「A」列を昇順で並び替える場合は、以下のように記述します。
|
1 |
df.sort_values( by = “A”, ascending = True ).head() |
ascending = falseとすると降順になります。
DataFrame型の変数df1, df2があるとき、
|
1 |
pd.merge( df1, df2 ) |
とすれば、結合が可能です。
集計
|
1 |
df.[ ‘A’ ].value_counts() |
とすれば、「A」列に、どのデータがいくつあるかを表示してくれます。
他にもさまざまな集計機能が用意されています。
今回は、Pandasについて解説しました。PandasはPythonで利用できるデータ解析のためのライブラリです。Pandasをインポートすることで、Series、DataFrame、Panelといったデータ型や、それらを操作するための関数を利用できるようになります。
Pythonを使って機械学習のプログラミングをするなら、Pandasを利用すると、効率的に進めることができます。ぜひ利用してみてください。

評価:★★★★★
基本的な事柄について大変わかりやすい講義でした。ありがとうございました。
評価:★★★★★
参考書で学習していましたが、不鮮明・あやふやなところがあり、この動画ですっきりしました。

 RANKING
RANKING



 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中