チャットボットやスマートスピーカー等の普及によって、音声でコンピューターを操作する機会が増えてきました。これらのシステムはAI(人工知能)を使用していますが、そのコアになる技術が「自然言語処理」です。
これは人間の会話(自然言語)の認識・生成を行う技術の総称ですが、自然言語処理はAI(人工知能)分野で今最も注目の集まる分野です。
というのも、この自然言語処理において最近大きなブレイクスルーがあり、それが2018年末に登場した「BERT」という手法なのです。複数のタスクにおいて人間の言語理解力を超える精度を示したことで大きな注目を集め、「ついにAI(人工知能)が人間を超えた」と言われるほどです。
この記事では、自然言語処理に一つの転換点をもたらしたBERTという手法は一体何か、どんな成果を上げたのかについて、AI(人工知能)初心者の方にもわかりやすく解説します。
公開日:2019年7月19日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す > 監修
監修
専門領域:人工知能(AI) / 生成AI / ディープラーニング / 機械学習
我妻 幸長 Yukinaga Azuma
「ヒトとAIの共生」がミッションの会社、SAI-Lab株式会社の代表取締役。AIの教育/研究/アート。東北大学大学院理学研究科、物理学専攻修了。博士(理学)。法政大学デザイン工学部兼任講師。オンライン教育プラットフォームUdemyで、十数万人にAIを教える人気講師。複数の有名企業でAI技術を指導。「AGI福岡」「自由研究室 AIRS-Lab」を主宰。著書に、「はじめてのディープラーニング」「はじめてのディープラーニング2」(SBクリエイティブ)、「Pythonで動かして学ぶ!あたらしい数学の教科書」「あたらしい脳科学と人工知能の教科書」「Google Colaboratoryで学ぶ! あたらしい人工知能技術の教科書」「PyTorchで作る!深層学習モデル・AI アプリ開発入門」「BERT実践入門」「生成AIプロンプトエンジニアリング入門」(翔泳社)。共著に「No.1スクール講師陣による 世界一受けたいiPhoneアプリ開発の授業」(技術評論社)。
…続きを読むBERTとは?特徴を知っておこう
BERTとは「Bidirectional Encoder Representations from Transformers(Transformerによる双方向のエンコード表現)」を指し、2018年10月11日にGoogleが発表した自然言語処理モデルです。
BERTの特徴として、汎用性の高さが挙げられます。これは、WikipediaやBooksCorpusなどから得た大量の文章データを学習モデルが事前学習し、文章理解や感情分析などの様々なタスクに応用できるというものです。

例えば、感情分析タスクであれば、与えられた文から感情を読み取って「肯定的」か「否定的」かのどちらであるかという結果を出力できます。これを活かして、アルゴリズムが複数の映画レビューを参照し、その映画の平均的な評価を分析するというタスクを高精度で行っています。
また、BERTは、今後「文脈の理解」や「暗黙の了解」など、より深いレベルでの言語理解に役立つと考えられているほか、株式会社ABEJAが運営するコンタクトセンター「ABEJA Insight for Contact Center」で活用されるなど、実用化も進んでいます。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >BERTが話題になったのはなぜ?どんな特徴がある?
BERTが登場する以前にも、上記で述べたような自然言語処理タスクを解くモデルは数多く存在していました。ではなぜ、BERTがこれほど大きな話題になったのでしょうか?
実は、BERTモデルの構造は、既存のタスク処理モデルと比べて根本的な相違点があります。
基本的に、従来のニューラルネットワークを用いた自然言語処理モデルは、文章理解や感情分析などの特定のタスクのみに対応しています。具体的には、タスクを実行するモデルに単語列の分散表現(文中の単語をベクトル化したもの)を入力します。この入力に応じてモデルが計算を行い、そのタスクに応じた結果を出力します。
この点、BERTは事前学習モデルであり、既存のタスク実行モデルに「くっつける」ことで、そのモデルの精度を向上させる役割を果たします。この「くっつける」作業をFine-tuning、転移学習と呼びます。
つまり、BERTでは既存の様々なタスク実行モデルに転移学習できるということです。
また、BERTを転移学習したモデルは、少ないデータを追加学習するのみで動作するので、一からモデルを構築しなくてすみます。
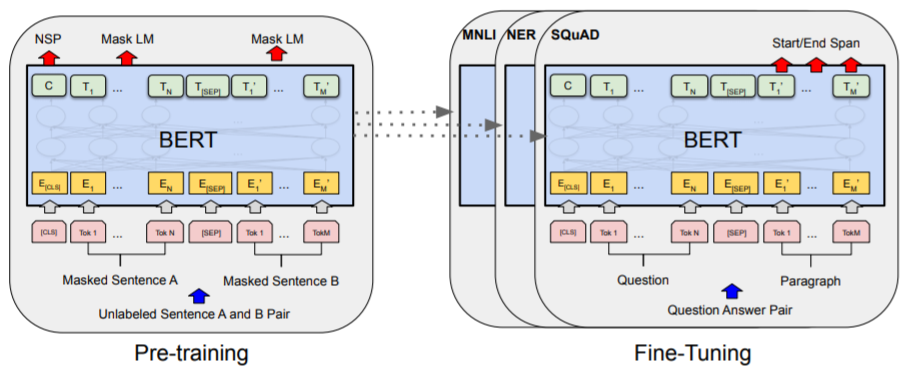
【引用】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
また、自然言語処理における長年の課題として、学習用データの不足が挙げられます。これはデータ収集やラベルの付与に多大な時間とコストがかかるのが主な理由です。
一方でBERTは、ネット上にある大量のラベル未付与のデータを用いて事前学習を行うため、データ不足という課題を克服するという点でも画期的です。
BERTを転移学習したモデルは複数のタスクで高い精度を記録しており、モデルの精度を測る指標である「SQuAD」や「MultiNLI」「GLUE」などの複数のベンチマークタスクにおいて、SOTA(State of the Art=最高水準)を達成しています。
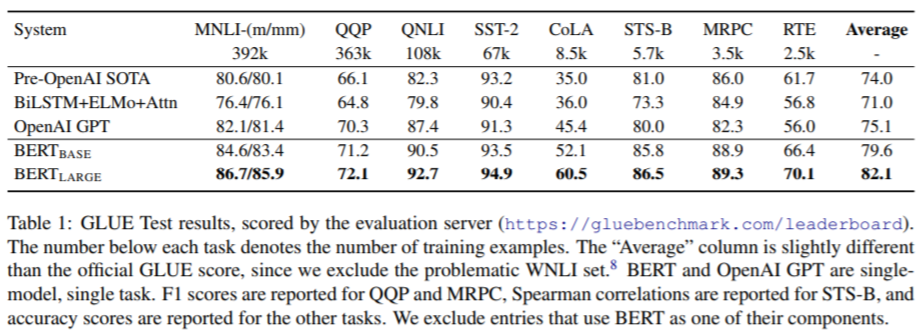
【引用】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERTが評価されたポイント
では、BERTは具体的にどのようなタスクで好成績を出したのでしょうか。有名なベンチマークタスク「SQuAD」と「GLUE」について解説します。
SQuADとは「Stanford Question Answering Dataset」の略で、スタンフォード大学が一般公開している言語処理の精度を測るベンチマークです。
約10万個の質問応答のペアデータを含んでおり、Wikipediaの文章から適切な回答を選択します。
例えば、
質問「Where do water droplets collide with ice crystals to form precipitation?」(水滴が氷の結晶と衝突して雨を形成するのはどこですか?)
Wikipedia「-Precipitation forms as smller droplets coalesce via collision with other rain drops or ice crystals within a cloud」(雨粒は、雲の中で他の雨粒や氷の結晶と衝突して合体し、小さな水滴として形成されます)
答え「within a cloud」(雲の中)
という具合に、文章から適切な回答を抜き出します。
また、GLUEは自然言語処理に関する9種類の学習データを含んだデータセットで、BERTでは以下の8種類を用いています。
- MNLI(Multi-Genre Natural Language Inference):約43万個のテキストデータで、テキスト同士の関連性(含意・矛盾・中立)を判定。
- QQP(Quora Question Pairs):2つの質問が同じ意味かを判定。
- QNLI(Question Natural Language Inference):文章内に質問の回答が含まれているかを判定。
- SST-2(Stanford Sentiment Treebank):映画のレビューを基に感情分析し、良し悪しを判定。
- CoLA(The Corpus of Linguistic Acceptability):文章が文法的に正しいかを判定。
- STS-B(The Semantic Textual Similarity Benchmark):2つのニュース見出しの意味的類似性を判定。
- MRPC(Microsoft Research Paraphrase Corpus):2つのニュース記事が意味的に等価かを判定。
- RTE(Recognizing Textual Entailment):2つの文章が含意関係かどうかを判定。
この他、「SWAG」や「CoNLL」など計11種類の自然言語タスクで評価したところ、全タスクでSOTA(State-of-the-Art:最先端・最新技術)を達成するという圧倒的な成果に。特に、SQuAD 1.1ver.とSWAGでは、人間の平均スコアを凌駕しています。
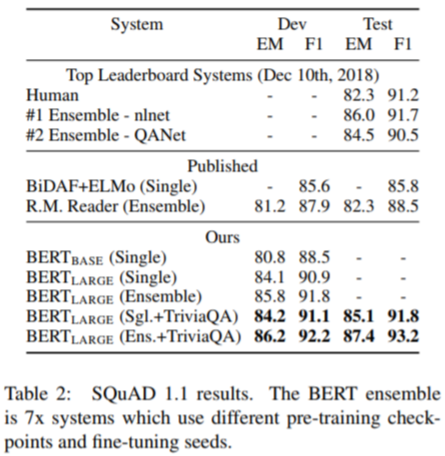
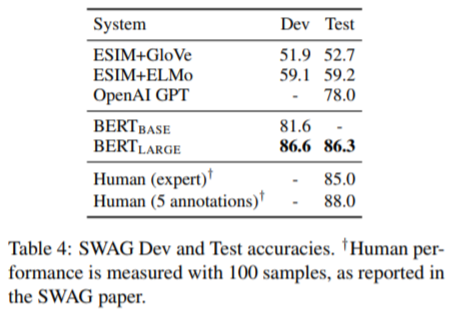
【引用】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
このように、単一のBERTモデルを様々なタスクに応用可能であるほか、複数のタスクで人間の精度を超えるほどの言語理解力を獲得したという点もブレイクスルーだといえます。
BERTの構造・仕組みは?どのように実現する?
では、BERTはどのような手法でブレイクスルーを起こしたのか、以下ではBERTの構造・仕組みについて解説します。
BERTの事前学習の特徴として、「Transformerが文章データを基に、文脈を双方向(Bidirectional)に学習する」ことが挙げられます。
Transformerとは言語処理に秀でた機械学習アーキテクチャで、BERTではTransformerが文章内の特定の単語を左右両方の文脈から予測することで学習します。具体的には「穴埋めクイズ」と「隣接文予測」という手法を用いますが、こちらは下記で説明します。

事前学習モデルはBERT以前にも存在し、例えばOpenAI GPTなどが挙げられますが、これは単一方向のみの学習、つまり特定の単語の右側(もしくは左側)にある単語列を読み込んで文脈を予測します。
また、双方向モデルはELMoなどが既に存在しますが、BERTと比べて双方向性が浅く、いずれにしてもBERTのような高精度なモデルではありませんでした。
BERTは事前学習モデルなので、学習データは分散表現として出力されます。分散表現のベクトルでは意味の近い単語同士が近くに配置されるなどの情報として表され、これを各タスクに応じたモデルへ転移学習を行うことで、目的に特化した出力が得られる仕組みです。
ちなみに、BERTは計104つの言語で学習を済ませており、日本語にも対応しています。学習済みモデルはコチラから無償利用できます。
BERTの学習タスク①MASKED LANGUAGE MODEL
続いて、BERTの双方向学習を実現した2つの手法を解説します。1つめが「Masked Language Model(穴埋めクイズ)」という手法で、アイデア自体はシンプルです。
Masked Language Modelでは、文章データ内から特定のトークン(文章の最小単位となる文字や文字列)を15%ランダムに選び、[MASK]トークンに置き換えて隠します。
例えば、
my dog is hairy → my dog is [MASK]
このマスク化された部分の単語を、前後の文脈から予測します。ですが、予測する単語が文章内の15%と少ないこと、また文章全体を予測する訳ではないので処理に時間がかかるという難点があります。
BERTの学習タスク②NEXT SENTENCE PREDICTION
2つめの手法である「Next Sentence Prediction(隣接文クイズ)」とは、2つの文章を与えて、それらが相互関係にあるかを判定します。
具体的には、学習データの2つの文章のうち、後者が50%の確率で前者と無関係な文章に置き換えられます。そして後者が前者の後に来る表現として意味的に正しければIsNext、そうでなければNotNextの判定をします。
例えば、
入力:[CLS] the man went to [MASK] store [SEP] /he bought a gallon [MASK] milk [SEP]
判定:IsNext
入力:[CLS] the man went to [MASK] store [SEP]/penguin [MASK] are flight #less birds [SEP]
判定:NotNext
このプロセスを大量に繰り返すことで、モデルに言語処理能力を獲得させるわけですが、この手法は学習コストがかかり、最大で16個のクラウドTPUを使用した場合でも、学習に4日かかっています。
その後発表された新たな手法では、従来のBERTの学習を76分で完了した成果も発表されており、事前学習を用いた自然言語処理は、今後より多くのタスクで活用しそうです。
AI(人工知能)が自然言語を文脈レベルで理解することは長い間困難とされてきました。例えば、ロボットに大学入試の問題を解かせるプロジェクトとして有名な「ロボットは東大に入れるか。」プロジェクトでは、言語理解タスクにおいて壁に当たり、プロジェクトは断念を余儀なくされています。
BERTは自然言語処理の性能を飛躍的に向上させた最初の実例だと言えます。
一方で、BERTが達成した言語理解力は、あくまで特定のタスクにおいてのみ効果があるものです。「BERTの登場=AI(人工知能)が人間以上の言語力を獲得した」とは、一概に言えません。
しかし、自然言語処理の研究は日進月歩で進んでいます。2019年6月に登場した「XLNet」では、既にBERTのスコアを凌駕してSOTAを達成しています。
次々と画期的な手法が登場する自然言語処理は、今後も注目すべき分野だといえそうです。
BERTによる自然言語処理を学ぼう! -Attention、TransformerからBERTへとつながるNLP技術-

ディープラーニング(深層学習)を使う自然言語処理技術の中でも、特に注目を集めているBERTを解説するコースです。Google Colaboratory環境でPyTorchを使用し、コードを動かしながらBERTの原理、実装を学びます。
\無料でプレビューをチェック!/
講座を見てみる評価:★★★★★
原著論文を引用して説明しているところ、説明が分かりやすいところ、コードだ十分な説明付きで提供されているところが良かったです
評価:★★★★★
まず理論の詳しい解説があり、その後Google Colaboratoryでの実装、コードの説明があったのでとても分かりやすかったです。

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中