レコメンドシステムの一種に「協調フィルタリング」が挙げられますが、
・協調フィルタリングがどのようなものなのかわからない…。
・協調フィルタリングを実装する方法が知りたい…。
と考える方は多いのではないでしょうか。そこでこの記事では、
・協調フィルタリングを理解して実装するための基礎知識
・Pythonで協調フィルタリングを実装する方法
についてわかりやすく解説します。
公開日: 2024年5月1日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す > 監修
監修
専門領域:AI、データサイエンス、デジタルマーケティング、プログラミング
ウマたん (上野佑馬)
「データサイエンスやAIの力でつまらない非効率を減らしおもしろい非効率を増やす」がビジョンのWW inc.の代表取締役社長。日系大手→外資系→AIスタートアップでデータ分析やデジタルマーケティングを経験。多くの人にもっとデータサイエンスを身近に感じてもらうべく月に10万人が訪れる「スタビジ」というメデイアでデータサイエンスの面白さを発信中。著書に「データサイエンス大全」「漫画でわかるデジタルマーケティング×データ分析」など。
…続きを読むINDEX
協調フィルタリングとは:レコメンドシステムの1つ
ECサイトなどでユーザーに対しておすすめの商品などを紹介する「レコメンデーション」を実現するものが「レコメンドシステム(推奨システム)」です。協調フィルタリングはこのレコメンドシステムの一種であり、有効な販促手段として注目されています。
協調フィルタリングを用いることで、ユーザーに対して新しい商品との出会いや、潜在的に欲しいと思っている商品との出会いを提供でき、ユーザーの購買体験の向上も期待できるでしょう。
協調フィルタリングの強みや欠点などについては、「協調フィルタリングって何?商品のおすすめ機能を学ぼう」をご覧ください。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >2つの協調フィルタリングをそれぞれ解説
レコメンドシステムで用いられる協調フィルタリングは、ユーザーベースとアイテムベースの2種類が存在します。
ここからはそれぞれの協調フィルタリングについて説明します。
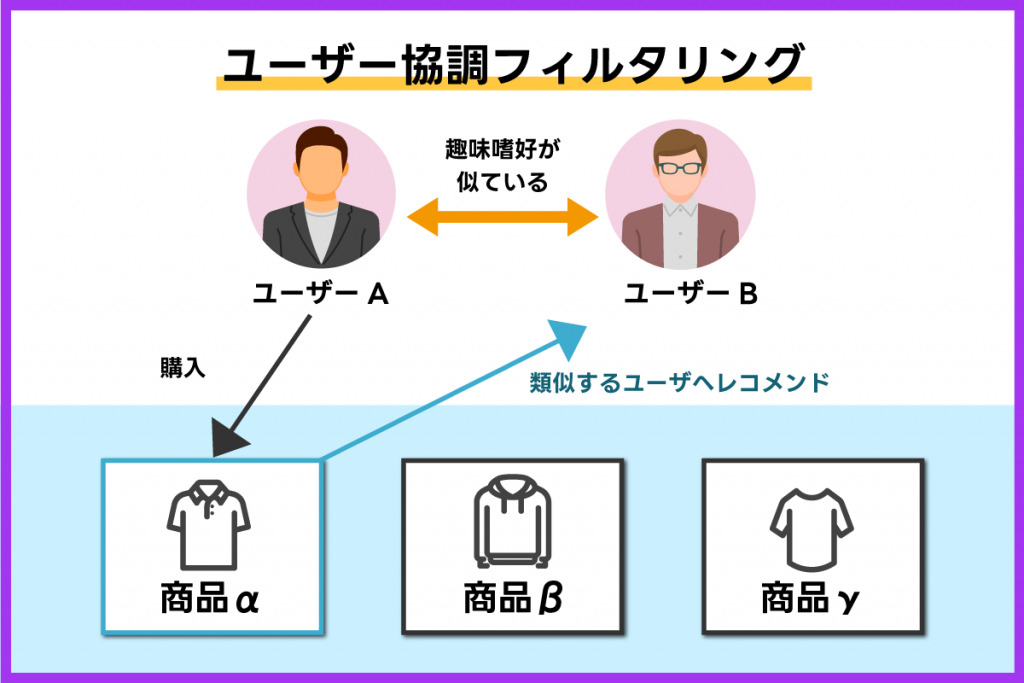
ユーザー協調フィルタリング
ユーザー協調フィルタリングは、ユーザー間の類似度を比較しておすすめ度を算出する手法です。ターゲットとなるユーザーに対して、類似するユーザーが購入したものや気に入っているものを紹介する仕組みです。
例えば、ユーザーAとユーザーBの趣味嗜好が似ていることがわかっていれば、ユーザーAが購入した商品はユーザーBも購入する可能性が高いと考えられます。このような考え方をもとにおすすめする手法がユーザー協調フィルタリングです。
「あなたに似たユーザーはこちらの商品も購入しています」というようなレコメンドが実現できる手法と考えてよいでしょう。
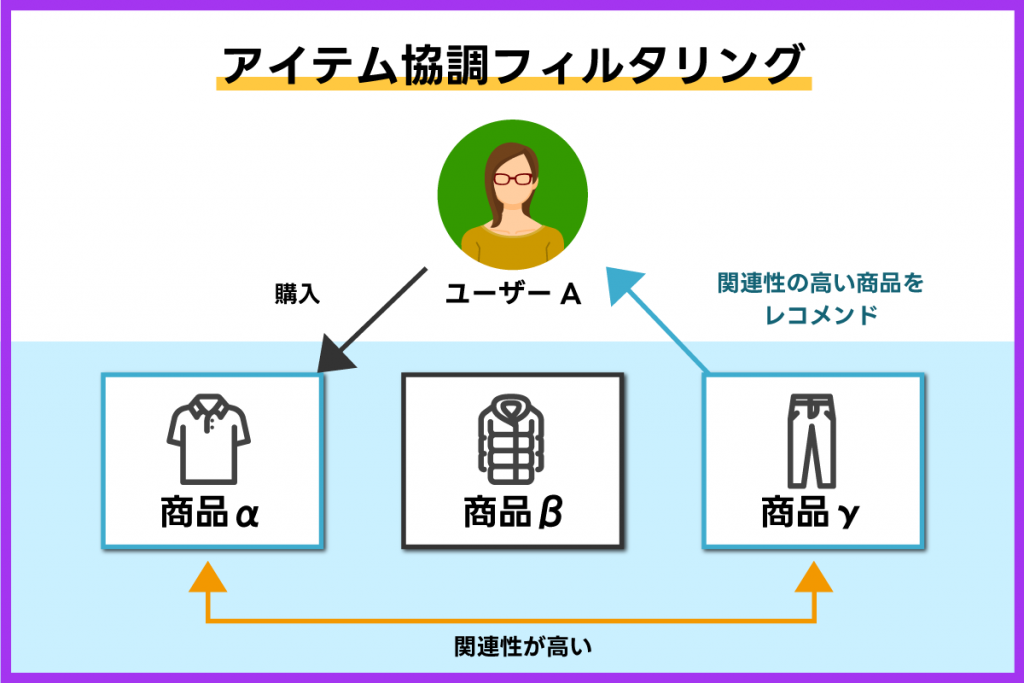
アイテム協調フィルタリング
アイテム協調フィルタリングは、アイテム間の類似度からおすすめ度を算出する手法です。商品の類似度から、似たようなおすすめ商品集などを作成し、アイテムを紹介する仕組みです。
例えば、商品αを購入したユーザーが商品βも購入している場合、別のユーザーが商品αを購入した際に商品βも併せて購入される可能性が考えられます。このような考えを基におすすめする手法がアイテム協調フィルタリングです。
「この商品を購入したユーザーはこちらの商品も購入しています」というようなレコメンドは、商品の類似度から算出されています。
協調フィルタリングのアルゴリズムとは
協調フィルタリングの基本的な考え方は、次のとおりとなります。
- ユーザー間の類似度を計算(ユーザー協調フィルタリングの場合)
- 類似度に基づき、特定のユーザーに対する商品群(リスト)を抽出
- 商品群(リスト)のなかからおすすめ度が高い商品を出力
このなかでも、特に類似度の計算に関しては重要度が高いため、もう少し掘り下げてみましょう。
類似度を計算する
協調フィルタリングでは、おすすめする商品を抽出する過程でユーザーまたはアイテム間の類似度を計算します。その評価を基におすすめ商品を算出しなければなりません。このときに「何をもって類似度が高い」と判断するかが重要です。
これは設計の際にどのように定義するかによって大きく異なりますが、例えば、ユーザーAが購入した商品αを高く評価し、ユーザーBも同様の商品を高く評価している場合、ユーザーAとユーザーBの類似度は高い、と考えることができます。
類似度の計算に使う関数を紹介
類似度の計算の際に利用される代表的な評価方法として「ピアソン相関係数」と「コサイン類似度」が挙げられます。ピアソン相関係数は、2つの変数の関係に注目し、変数間の関係を示すものです。線形関係が強いほど大きな値をとり、類似度を図ることができます。
ピアソン相関係数
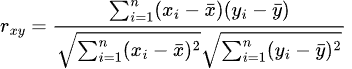
もう一つのコサイン類似度は「2つのベクトルがどの程度似ているか」という尺度で類似性を表すものです。コサイン類似度は-1~1の範囲で値が返され、1に近づくほど類似度が高いとされます。
コサイン類似度
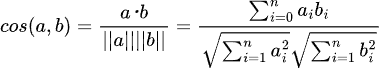
Pythonを使った具体的な算出方法を解説
実際にPythonを使った協調フィルタリングの例を紹介します。最後にサンプルコード全体を記載してますので、実際に動かしたい場合はそちらを参照ください。
ここでは、実用的とはいえませんがイメージを掴むための参考として、簡単なコードで解説しています。Pythonで実用的なレコメンドシステムの実装を検討する場合は、「Surprise」ライブラリなどの活用も検討するとよいでしょう。

データを用意する
協調フィルタリングを行うために、まずデータを用意します。使用するデータは主にユーザーの識別子、アイテムの識別子、評価値などが挙げられます。
今回は次の条件でデータを作成しました。
目的:特定のユーザーがプレイしたことのないゲームをおすすめする
条件1:ユーザーはA~Dの4人
条件2:Game1~3は全てのユーザーがプレイしており、その評価を基にユーザーの類似性を判断する
条件3:プレイしたことのないGameの評価は「0.0」とする
|
1 2 3 4 5 6 7 8 9 10 11 |
dataset = { 'UserA': { 'Game1':2.0, 'Game2':4.0, 'Game3':1.0, 'Game4':5.0, 'Game5':1.0, 'Game6':0.0, 'Game7':0.0 }, 'UserB': { 'Game1':2.0, 'Game2':3.0, 'Game3':1.0, 'Game4':0.0, 'Game5':0.0, 'Game6':4.0, 'Game7':5.0 }, 'UserC': { 'Game1':5.0, 'Game2':1.0, 'Game3':5.0, 'Game4':0.0, 'Game5':0.0, 'Game6':0.0, 'Game7':2.0 }, 'UserD': { 'Game1':4.0, 'Game2':1.0, 'Game3':4.0, 'Game4':3.0, 'Game5':5.0, 'Game6':0.0, 'Game7':0.0 } } |
ユーザーの類似度を計算する
次にユーザーの類似度を計算する関数を作成します。この関数は2ユーザー間の類似度を相関係数で求め、その結果を返す関数です。相関係数は数値計算を効率的に行うための拡張ライブラリである「Numpy」を用いて計算しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
def getSimilarUsers(user1, user2): user1_data = list(dataset[user1].values()) user2_data = list(dataset[user2].values()) user1_eval_data = [user1_data[i] for i in range(0,3)] user2_eval_data = [user2_data[i] for i in range(0,3)] co = np.corrcoef(user1_eval_data, user2_eval_data)[0,1] return(abs(co)) # 動作確認用 print('UserA-UserB:', getSimilarUsers('UserA','UserB')) print('UserA-UserC:', getSimilarUsers('UserA','UserC')) print('UserA-UserD:', getSimilarUsers('UserA','UserD')) |
この関数を実行すると、次のような結果が得られます。
UserAとの類似度をチェックすると、UserBが最も高い数値となっているため「UserAとUserBの類似度が高い」と判断することが可能です。
|
1 2 3 4 |
UserA-UserB: 0.9819805060619656 UserA-UserC: 0.944911182523068 UserA-UserD: 0.944911182523068 |
レコメンド関数を実装する
続いてレコメンド関数を実装します。この関数は、Gameをおすすめしたいユーザー名を引数として渡すことで、そのユーザーがプレイしたことのないおすすめのGameを返す関数です。
まずはユーザーがプレイしたことのないGameのリストを「user_not_play_games」として持っておきます。その後、前述の類似度の高いユーザーを抽出し「対象ユーザーのプレイしたことがない、かつ類似度が高いユーザーの評価が高いGame」を返す仕組みです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
def getRecommendGame(user): similar_user = '' best_sim_score = 0.0 best_sim_g_score = 0.0 not_user_dataset = dataset.copy() user_dataset = not_user_dataset.pop(user) user_not_play_games = [k for k, v in user_dataset.items() if v == 0.0] for u in not_user_dataset.keys(): tmp_score = getSimilarUsers(user, u) if best_sim_score <= tmp_score: similar_user = u best_sim_score = tmp_score for g in user_not_play_games: tmp_g_score = not_user_dataset[similar_user][g] if best_sim_g_score <= tmp_g_score: recommend_game = g best_sim_g_score = tmp_g_score return(recommend_game) |
ここでデータセットを表形式で確認してみましょう。UserAと類似度が高いユーザーはUserBです。「UserAがプレイしたことがなく、UserBの評価が高いGame」という条件で見ると「Game7」が該当することがわかります。
| User | Game1 | Game2 | Game3 | Game4 | Game5 | Game6 | Game7 |
| UserA | 2.0 | 4.0 | 1.0 | 5.0 | 1.0 | 0.0 | 0.0 |
| UserB | 2.0 | 3.0 | 1.0 | 0.0 | 0.0 | 4.0 | 5.0 |
| UserC | 5.0 | 1.0 | 5.0 | 0.0 | 0.0 | 0.0 | 2.0 |
| UserD | 4.0 | 1.0 | 4.0 | 3.0 | 5.0 | 0.0 | 0.0 |
最後に、ここまでに解説した内容を含めたサンプルコード全体を記載します。実際に実行してみると、想定通り「Game7」が出力されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
import numpy as np dataset = { 'UserA': { 'Game1':2.0, 'Game2':4.0, 'Game3':1.0, 'Game4':5.0, 'Game5':1.0, 'Game6':0.0, 'Game7':0.0 }, 'UserB': { 'Game1':2.0, 'Game2':3.0, 'Game3':1.0, 'Game4':0.0, 'Game5':0.0, 'Game6':4.0, 'Game7':5.0 }, 'UserC': { 'Game1':5.0, 'Game2':1.0, 'Game3':5.0, 'Game4':0.0, 'Game5':0.0, 'Game6':0.0, 'Game7':2.0 }, 'UserD': { 'Game1':4.0, 'Game2':1.0, 'Game3':4.0, 'Game4':3.0, 'Game5':5.0, 'Game6':0.0, 'Game7':0.0 } } def getSimilarUsers(user1, user2): user1_data = list(dataset[user1].values()) user2_data = list(dataset[user2].values()) user1_eval_data = [user1_data[i] for i in range(0,3)] user2_eval_data = [user2_data[i] for i in range(0,3)] co = np.corrcoef(user1_eval_data, user2_eval_data)[0,1] return(abs(co)) def getRecommendGame(user): similar_user = '' best_sim_score = 0.0 best_sim_g_score = 0.0 not_user_dataset = dataset.copy() user_dataset = not_user_dataset.pop(user) user_not_play_games = [k for k, v in user_dataset.items() if v == 0.0] for u in not_user_dataset.keys(): tmp_score = getSimilarUsers(user, u) if best_sim_score <= tmp_score: similar_user = u best_sim_score = tmp_score for g in user_not_play_games: tmp_g_score = not_user_dataset[similar_user][g] if best_sim_g_score <= tmp_g_score: recommend_game = g best_sim_g_score = tmp_g_score return(recommend_game) print(getRecommendGame('UserA')) |
出力結果:
|
1 |
Game7 |
こちらのサンプルコードを参考に、対象ユーザーを変更するなどして動作を確認してみましょう。実際に動かすことで、より深く理解できるようになります。
Pythonを使って協調フィルタリングを算出しよう!
協調フィルタリングは、おすすめの商品などを紹介するレコメンドシステムの一種です。レコメンドシステムで用いられる協調フィルタリングは、おもにユーザーベースとアイテムベースの2種類に分けられます。
ただ、この実装方法は、協調フィルタリングの基礎を理解するためのもので実用的とはいえません。実用的でより深く協調フィルタリングについて学びたい場合は、以下の講座がおすすめです。
【Python×協調フィルタリング】レコメンドで使われる協調フィルタリングのアルゴリズムを学びPythonで実装!

レコメンドロジックにはどんな種類があるのかを学び最もよく使われる協調フィルタリングについて理解してPythonで実装していこう!映画の評価データやジョークの評価データを使って協調フィルタリングを実装してみよう!
\無料でプレビューをチェック!/
講座を見てみる評価:★★★★★
コメント:とても丁寧に説明があり、分かり易いです。
評価:★★★★★
コメント:実装の手順を踏んで、協調フィルタリングを理解できた。
Pythonを用いて実装することで、協調フィルタリングの理解を深めることができます。

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中