

昨今、ビッグデータを人工知能(=AI)で解析し、顧客ニーズを汲み取り、自社商品の改善につなげる企業が増えてきています。
この記事では、そんなビッグデータを解析できる手法の1つとして、クラスタリング(=クラスター分析)を紹介します。
クラスタリングや統計学、AIについて全く知らない人でも理解できるよう、数式などは一切使用せずに解説していますので、ぜひ最後まで読んでクラスタリングの概要を掴んでください。
公開日:2017年12月28日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す > 監修
監修
専門領域:リサーチ全般 (Research) / 統計学 (Statistics) / R / Excel
Miyamoto Shota
慶應義塾大学法学部卒業後、大手インフラ企業を経て国内シンクタンクにてデータ分析やリサーチ活動に従事。公的統計データやマーケティングデータの分析に加え、統計的手法や機械学習モデルを用いた需要予測、売れ行き要因分析等のリサーチ活動に従事。その後、国内MBAを取得、現在は会社を設立しリサーチ活動や講師業を行う。
…続きを読むINDEX
クラスタリングとは?機械学習の分野でも使われる!
「クラスタリング」とは、簡単にいうとデータなどの集合体を、機能やカテゴリごとに分けて集めることです。
また、クラスタリングはクラスター分析、クラスター解析と呼ばれることもあります。
また、機械学習の分野でこのクラスタリングという言葉が使われている時、それは「教師なし学習」に分類される機械学習のうちの種類の一つのことを指しています。
機械学習におけるクラスタリングでは、入力されたデータ同士の類似度にもとづいて、データをグループ化できるのが大きな特徴です。
なお、クラスタリングを行うためのアルゴリズムには、以下の2種類があります。
・「階層クラスター分析(=階層クラスタリング)」
・「非階層クラスター分析(=非階層クラスタリング)」
こちらの2種類のアルゴリズムについてはのちほどわかりやすく解説します。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >分類対象の少ないデータに適した階層クラスター分析
まずは、クラスタリングを行うアルゴリズムの一種である、「階層クラスター分析」について、解説していきます。
階層クラスター分析とは、集合体のデータのうち、最も似ている組み合わせから先にまとめていく階層的手法です。
この手法の場合、1つのクラスター(集合)になるまで、階層的に併合を繰り返すので、データを樹形図で見ることができます。
階層クラスター分析について理解を深めるために、メリットとデメリット、また階層クラスターの手法2種類を紹介します。
階層クラスター分析のメリット、デメリットは?どのようなデータ分析に適するのか?
階層クラスター分析を利用するメリットは、あらかじめクラスター数を定義する必要がない点です。
また、出力されたクラスターを必ず樹形図で見ることができるため、階層クラスター分析の場合、あとからクラスター数を決めることもできます。
デメリットは、ビッグデータといった大量のデータ分析には向いていない点です。
これは、計算量が増えて実行しづらくなるためです。
階層クラスター分析に適している分類の対象数は、数十個以下といわれています。
なお、階層クラスター分析には「ウォード法」「群平均法」「最長距離法」「最短距離法」といった方法がありますが、こちらの記事では、中でも抑えておきたい「ウォード法」と「群平均法」の2種類を分かりやすく解説します。
階層クラスター分析の手法①ウォード法
「ウォード法」とは、凝集型のクラスター分析の手法の1つです。
別名「凝集型階層的クラスタリング」とも呼ばれています。
ウォード法では、すでにあるクラスターの中で、1番距離の近い2つのクラスターが選ばれ、1つのクラスターに結合されていく操作を、目標のクラスター数になるまで続けていきます。
下記がウォード法のイメージ図です。
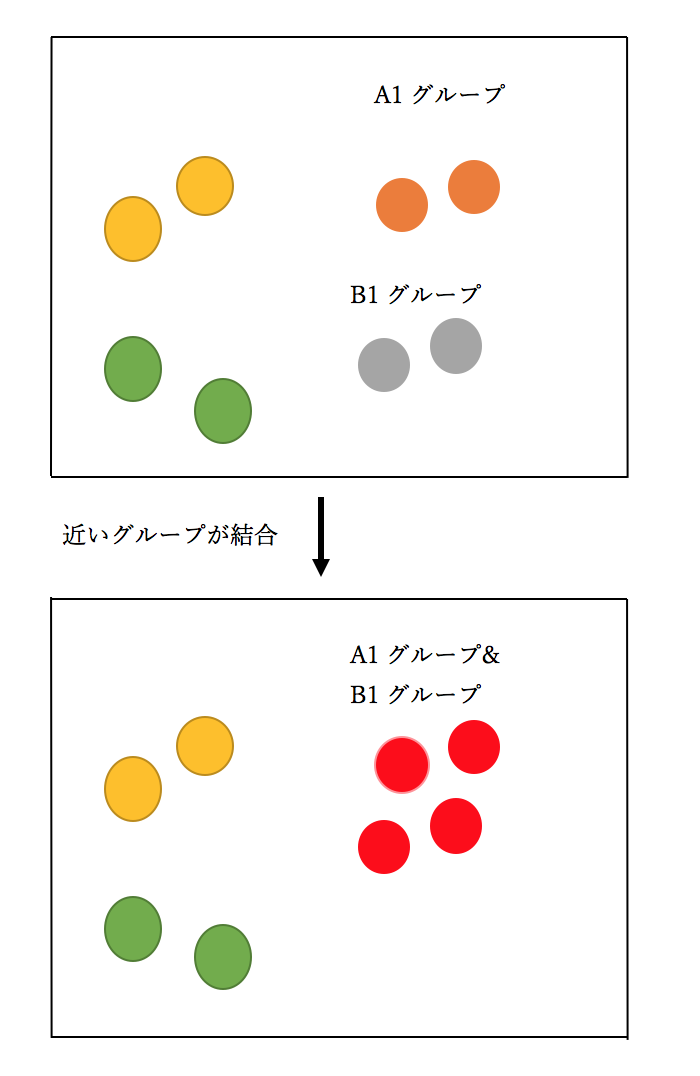
ウォード法は計算量が多いのが難点ですが、分類される感度が高いため、クラスター分析の中では、よく使われる手法です。
階層クラスター分析の手法②群平均法
「群平均法」とは、2つのクラスターに属している対象の間のすべての組み合わせの距離を求め、それらの平均値をクラスター間の距離として定める手法です。
以下が群平均法のイメージ図です。
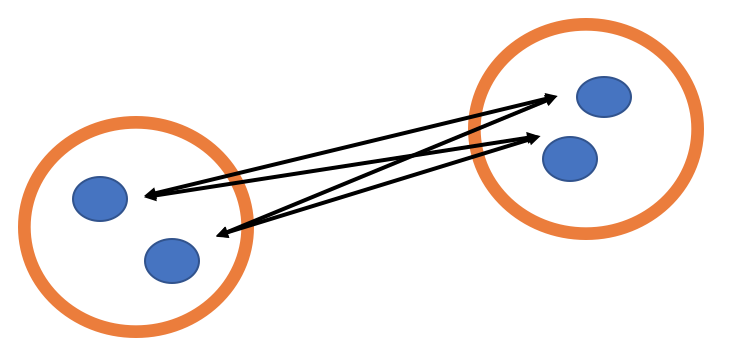
この群平均法を利用するメリットは、鎖効果を防止できる点です。
クラスター分析における鎖効果とは、1つのクラスターに対象が1つずつ吸収されていき、新しいクラスターが作られる現象のことです。
鎖効果は、クラスター分析の中で起きて欲しくない現象です。
ですから、ウォード法を実施した際に、鎖効果が起きてしまう場合などに群平均法が有効と言えるでしょう。
ビッグデータ解析に使われる非階層クラスター分析
続いて、クラスタリングのもう1つのアルゴリズムの手法である「非階層クラスター分析」のメリットやデメリット、また手法などを解説していきます。
非階層クラスター分析とは、違った性質のものが混ざり合っている集合体の中から、似ている性質の対象のものを集めて、クラスターを作る手法です。
非階層クラスター分析は、ビッグデータの解析をしたり、大量のデータを分類したりする際に頻繁に使用されます。
では、なぜ非階層クラスター分析が、ビッグデータの解析に適しているのでしょうか?
非階層のクラスター分析メリットとデメリット、そして実際の手法について紹介します。
ビッグデータ解析に使われる非階層クラスター分析のメリットデメリットは?
非階層クラスター分析では、階層クラスター分析とは異なり、階層的な構造がないため、サンプル数が大きいデータであっても取り扱うことが可能なのです。
デメリットとしては、非階層クラスター分析では、自動でクラスター数を決めてくれないため、実行する人が予めクラスター数を決めておく必要がある点が挙げられます。
他の見方をすれば、クラスター数を分析者が決められるため、分類対象が多いビッグデータを対象にすることも可能になり、適していると言えます。
非階層クラスター分析の手法:K-MEANS法
続いて、非階層クラスター分析の中でも、最も有名な代表的手法である「k-means法」について解説します。
k-means法は、クラスター数を最初からk個として定め、クラスターの中心点の位置を対象のデータからランダムにk個決める手法です。
はじめにk個のクラスターに分けると決め、そのあとk個を代表するベクトルをランダムに決めます。
そして、距離の近い代表するベクトルのところのグループに入り、それぞれのグループのデータの平均を取り、その平均を次の代表するベクトルにします。
この作業を繰り返し、クラスターの代表するベクトルが変化しなくなった時点で作業は終了となります。
クラスタリングのまとめ
ここまで、クラスタリングについて、また「階層クラスター分析」と「非階層クラスター分析」について紹介してきました。
最後におさらいしておきましょう。
・クラスタリングとは「強化なし学習」に分類される機械学習の1つで、入力されたデータの類似性をもとにして分類する手法のこと
・クラスタリングのアルゴリズムには「階層クラスター分析」と「非階層クラスター分析」の2種類がある
・階層クラスター分析は階層構造のある分類方法
・階層クラスター分析は、出力されたクラスターを樹形図で見ることもできるが、大量のデータ分類は向いていないため、対象の少ないデータに実行するのに有効
・非階層クラスター分析は階層構造のない分類方法
・非階層クラスター分析は、事前にクラスター数を決めておく必要があるが、対象のビッグデータに実行するのに最適な分類方法
クラスタリングについて、まずは上記を覚えておきましょう。
クラスタリングについての理解をさらに深めよう!
クラスタリングを理解することは ビッグデータ解析を実務に活かすうえで必要不可欠です。
クラスタリングについて動画でわかりやすく学びたい方には、下記の講座がおすすめです。
社会人のためのデータサイエンス基礎講座|データサイエンスの基礎を数学やプログラミングの知識なしで学べる基礎講座

現代の一般教養でもあるデータサイエンスの基礎(全体像、パラ/ノンパラメトリック、未学習/過学習、教師あり/なし学習、回帰/分類、クラスタリング/次元削減、MSE/混同行列/ROC曲線など)を学びましょう!数学やプログラミングの知識不要です
\無料でプレビューをチェック!/
講座を見てみるレビューの一部をご紹介
評価:★★★★★
モデルの評価方法についても誤分類率、真偽陽性率、閾値、ROCなどの概念が図示等も豊富で繋がりを持って理解することができました。
評価:★★★★★
コメント:とても分かりやすい内容で、途中で飽きること無く、すんなりと頭に入ってきました。データサイエンス・データ分析の重要タームを直感的(難しいことを考える必要がなく)につかめる内容になっている点が良かったのだと思います。
ぜひデータ分析について深く学び、 DX時代に対応できるスキルを手に入れましょう。

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中