

本記事では、近年の人工知能(AI)ブームを理解するための基本である「機械学習」について解説します。
機械学習の学習モデルは様々なものがあります。ここでは、近年話題に事欠かないディープラーニングにも触れながら解説していきます。
実用例や問題点も含めてご紹介することで、初心者でも理解できるように解説していますので、ぜひ最後まで読んで、機械学習とは何か理解してください。
公開日:2017年10月11日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >INDEX
機械学習とは?(教師あり/なし学習、強化学習)
機械学習とは、その字が表すとおり「機械(コンピュータ)が学習する」ことです。機械が学習するためには、学習の元となるデータを入力値として用います。
この入力値を「機械学習アルゴリズム」と呼ばれる処理を通して、データを分類したり、認識したりする処理を見つけ出します。そして、この学習した処理を使うことで、学習後に入力された未だ学習していないデータに対しても、分類したり識別したりすることができるようになります。
機械学習を、学習した結果の出力値の種類で大きく分けると、次のように分類されます。
分類や認識(識別)
学習した結果(出力)は、動物の種類、指紋など離散値(飛び飛びの値)になります。
予測(回帰)
学習した結果(出力)は、降水量、株価など連続値(入力値と同じ数値)になります。
機械学習は様々な場面で効果を発揮します。それは、その利用シーンにあったアルゴリズムを選択・使用することによって実現します。場合によっては、複数のアルゴリズムを組み合わせることで効率よく学習・判定することができるようにもなります。
「機械学習アルゴリズム」を使うことで、人間の書く固定的なプログラムでは解決しえない難しいタスクに取り組むことが可能になります。
機械学習の分類にはさまざまな分類方法がありますが、このアルゴリズムを次の3種類に分ける考え方があります。
・教師あり学習(Supervised Learning)
・教師なし学習(Unsupervised Learning)
・強化学習(Reinforcement Learning)
それでは、それぞれのアルゴリズムについて詳しくみてみましょう。
教師あり学習
「教師あり学習」は、事前に与えられたデータから、その「入力と出力の関係」を学習するアルゴリズムです。入力されるデータには、入力値とともに、あらかじめそのデータの正解が付与されています。まさしく正解が分かっているデータですから「教師ありデータ」と呼びます。
大量のデータを人間(教師)が用意し、それをプログラムに与えることで、プログラムは入力と出力の関係を学習します。一般的には、分類や予測は、教師あり学習を使うとよいと言われています。
一度、与えられた入出力データ間の関係が学習できれば、それを未知のデータに適用し、出力の予想が可能になります。分類の問題であればこれを分類器、回帰の問題であればこれを回帰曲線といいます。
教師なし学習
「教師なし学習」は、人間(教師)から正解となる出力データを与えられることなく、入力データから、そのデータの構造、特性、新たな知見を学習するアルゴリズムです。学習する元となるデータには、正解がついていないにも関わらず、そのデータから特徴を見つけ出すことが可能となる様々な手法があります。
適切な手法を使うことにより、例え正解を教えられなくても、コンピュータが学習することができるようになりました。なお、この学習のために利用されるデータは、教師ありデータに対して「教師なしデータ」と呼ばれます。
強化学習
「強化学習」とは、 教師あり学習、教師なし学習のような固定的で明確なデータを元にした学習ではなく、プログラム自体が与えられた環境(=現在の状態)を観測し、各行動の、評価、を自ら更新していき、連続した一連の行動の結果、価値が最大化する(=報酬が最も多く得られる)行動を方法を自ら学習していきます。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >人工知能(AI)、機械学習、ディープラーニングの違いとは?
◆人工知能(AI)、機械学習、ディープラーニング(深層学習)の関係図
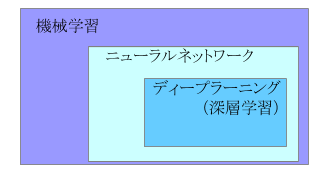
人工知能(AI)、機械学習、ディープラーニング(深層学習)の関係は、上の図のようになっています。
つまり、ディープラーニングは機械学習の一部であり、機械学習は人工知能(AI)の一部なのです。
実は、人工知能(AI)は、現在流行している機械学習やその一部であるディープラーニングだけではありません。他にも多くの人工知能の分野があります。
人工知能(AI)の種類と特徴
ここでは、わかりやすく「記号処理的人工知能」と「非記号処理的人工知能」の2つに分類します。
記号処理的人工知能が得意な分野は、数式処理、自動推論、自然言語処理などです。自動推論や機械翻訳はこの応用分野です。エキスパートシステムはこのタイプの人工知能です。
記号とは、厳密に定義、定式化できるものを指します。数式や自然言語の言葉それぞれを厳密に定義した記号化し、それをトップダウン処理で色々な観点から処理します。しかしそれゆえ、模倣や学習という概念を持たないことから、定義された枠組み(フレーム)を外れた処理はできません。
非記号処理的人工知能が得意な分野は、パターン認識(画像、音声、文字など)、機械学習です。
パターン認識はボトムアップ的な処理で、数多くのパターンを分析し、ときには学習し、その情報を基にパターンマッチして、対象を認識します。
つまり、機械学習は非記号処理的人工知能の範疇に含まれます。
機械学習とディープラーニングの違い
次に、機械学習とディープラーニングの違いについて見ていきます。
機械学習は、開発者が全ての動作をプログラムするのではなく、データをAI自身が解析し、法則性やルールを見つけ出す、つまり、トレーニングによって特定のタスクを実行できるようになる人工知能をさします。
ディープラーニングは機械学習の中の一手法で、20世紀後半に研究が進められた一連のニューラルネットワークとその関連技術の発展形です。従来の機械学習と異なり、人間の神経を参考にしたニューラルネットワークを何層も重ねることにより、データの分析と学習を強化した人工知能をさします。
なお、ディープラーニングは、分析の対象を区別するための特徴量を自動で見つけ出す、と言われることもありますが、CNNの畳み込み層での処理がそのように見えるだけで、ディープラーニングも人間が大部分の特徴量を決めなければ、実はきちんと機能しません。
人工知能/機械学習初心者でも知っておきたい!DQN(Deep Q-Network)とは?
DQN(Deep Q-Network )はGoogle傘下のDeepMind社が開発した強化学習の一手法です。
DQNが新しい技術といわれるのは、Q学習(強化学習の一つ)と、ディープラーニングを組み合わせている点です
CNN(畳み込みニューラルネットワーク)を使用した他、RMSPropのような最適化手法を適用したことも成果を上げる要因となっています。
CNNのような多層ニューラルネットワークは工夫なしには学習が遅く、また学習率を大きくしても学習が発散するため、自分でデータを集めて学習する従来型のオンライン型強化学習では高速化が困難でした。
そこでDQNはバッチ強化学習、つまり十分な数のデータがあることにしてサンプル追加せず、既存データだけで最適方策を学習することにしました。DQNで使われているNeural Fitted Q Iterationでは、各最適化中では完全に教師あり学習になっており、非常に学習が安定していると考えられます。
こうしてDQNは、予備知識のない状態からブロック崩しゲームを膨大な回数こなすことで、ゲームのルールを認識し、最終的には人間の出しうる得点を凌駕できるまでになりました。Atari 2600のゲーム49種類のうち、半数以上のゲームで、人間が記録したスコアの75%以上を獲得してもいます。
豊富な演習問題とKaggle実践で身に付ける!『Python データ分析 & 機械学習 ~パーフェクトスターターコース』

Numpy, Pandas, Matplotlib, Seaborn, scikit-learn & Kaggle ... データ前処理、分析、視覚化、さらに予想モデルの構築・評価まで。初めて出会うデータセットへ即応できる力を付けましょう!
\無料でプレビューをチェック!/
講座を見てみる評価:★★★★★
Python, module, 統計modelの基礎学習を終えて、初めての機械学習がこのコースでした。演習が多くて学んだことをoutputできるコースでした。特徴量の前処理あたりから難しかったですが、最後のKaggleの演習で点と点がつながり分析の流れや機械学習modelの基礎を学べました。貴重な学習ができました。ありがとうございました。
評価:★★★★★
kaggleで、過去のデータ(タイタニック以外)でも、自分の興味があるものであれば、積極的に他の人が作成したコードを元に工夫して勉強するに値するのが、良く解かった。ありがとうございます。

 RANKING
RANKING



 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中