tidyverse (タイディーバース) は、データ分析のためのプログラミング言語Rにおいて、「モダンなデータ分析」を行うためのパッケージ群です。データの読み込み、抽出、加工、可視化といった、データ分析における基本的な作業を効率的に行うための、さまざまな機能を提供しています。
この記事では、Rプログラミングにおいて、tidyverseを利用する方法やメリットについて、実際のプログラム例と合わせて紹介しています。
公開日:2021年6月29日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す > 監修
監修
専門領域:データサイエンス,AI,プログラミング(R,Python)
shun .
とあるメーカーでAIエンジニアとして勤務。エンジンの解析やAIを使用したアルゴリズム開発に携わる。主要言語はRとPython。データサイエンスやプログラミングが好物。Udemy講座ではイメージをたくさん利用し、データサイエンス特有のわかりづらい概念をできるだけかみ砕いて解説。
…続きを読むデータ分析に最適なtidyverseとは?
tidyverseは、R言語のパッケージ (拡張機能) の名称です。tidyverseは、“tidy” + “verse” の造語で、tidyは“tidy data” という概念 (後述) を、verseはUniverseなど、「世界」というような意味合いです。つまり、tidyverseは、Rにおいて “tidy data” を実現するための、統一された世界観に基づくパッケージ群、というように解釈できます。
なお、R言語の概要、基本的な使い方について知りたい方は、「【R言語入門】統計学に必須な「R言語」について1から解説!」を参照してください。
tidyverseを利用するメリットとは?
tidyverseは、単独のパッケージではなく、さまざまなパッケージの総称です。それぞれのパッケージが提供する機能、プログラム例については、以下で紹介しています。
まず、Rユーザーがtidyverseを利用する理由は何でしょうか? ひとつは、tidyverseは、標準のRの文法 (組み込み関数) を念頭に、より使いやすくなるよう設計されているということがあります。プログラミングに不慣れな分析者にとって、より直感的に、アイディアをプログラムとして実現しやすい環境を提供しています。
もうひとつ、tidyverseを共通のプラットフォームとして利用することで、分析の再現性や共同作業の効率性を高められる、ということがあります。近年、データ分析においてtidyverseを活用することは、スタンダードになりつつあります。そのため、多くの解説書も、tidyverseを念頭に置いた記述になっています。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >tidyverseでできることとは?
tidyverseの根本には、データ分析の世界で広く受け入れられている “tidy data” という考え方があります。tidy dataは、「整然データ」と訳されることもあります。tidy dataは、以下の3つの原則に沿って整理されたデータ構造のことです。
- 1つの変数は1つの列に格納される
- 1つの観測結果 (レコード) は1行に格納される
- 個々のデータは1つのセルに格納される
tidyverseは、このtidy dataを念頭に、tidyでないデータをtidyに変換したり、逆にtidy dataとして処理した結果を、人間にとって見やすいtidyでない形式に変換できたりします。

tidyverseに含まれるパッケージとそれぞれの用途を紹介
tidyverseを構成する中核的なパッケージは以下の通りです。それぞれ、どのような用途があるのか、あわせてご紹介します。
- ggplot2: グラフィックスを作成するためのパッケージ
- dplyr: データ操作、抽出、加工のためのパッケージ
- tidyr: “tidy data” を作成、操作するためのパッケージ
- readr: ファイルを柔軟に読み込むためのパッケージ
- purrr: 関数型プログラミングを実現するためのパッケージ
- tibble: データ構造tibbleを作成、操作するためのパッケージ
- stringr: 文字列を容易に、柔軟に操作するためのパッケージ
- forcats: factor型のデータを柔軟に操作するためのパッケージ
- magrittr: パイプ (%>%) 演算子の機能を提供するパッケージ
magrittrパッケージが提供するパイプ (%>%) 演算子は、UNIX / Linuxにおけるそれと同じく、演算子の左側で行った処理の結果を、演算子の右側の処理に引き渡します。
tidyverseをインストールしてデータ分析をしてみよう
ここからtidyverseを構成する各パッケージをインストールし、データ分析を実践してみましょう。
なお、以下は、お手元にR言語の実行環境があることを前提としていますが、RやRStudioのインストールについては、「【R言語入門】統計学に必須な「R言語」について1から解説!」を参考にしてください。
tidyverseをインストールしてパッケージを確認しよう
まずは、tidyverseパッケージ群をインストールしましょう。tidyverseは、install.packages(“tidyverse”) としてインストールできます。この際、上記のパッケージ群がまとめてインストールされます。
tidyverseパッケージ群をインストールしたら、library() 関数で読み込んでみましょう。library(tidyverse) とすると、以下のように出力されます。

tidyverseを使用して簡単なデータ分析をしよう
ここからは、実際にtidyverseを使ったRプログラムの例を紹介します。今回は、総務省統計局が公開している「SSDSE(教育用標準データセット)」のうち、「SSDSE-B: 都道府県別、時系列、多分野データ」を使用します。
まず、readrパッケージの read_csv() 関数を使い、統計局のWebサイトからSSDSE-Bをダウンロードし、読み込みます。URLを直接引数に指定できます。

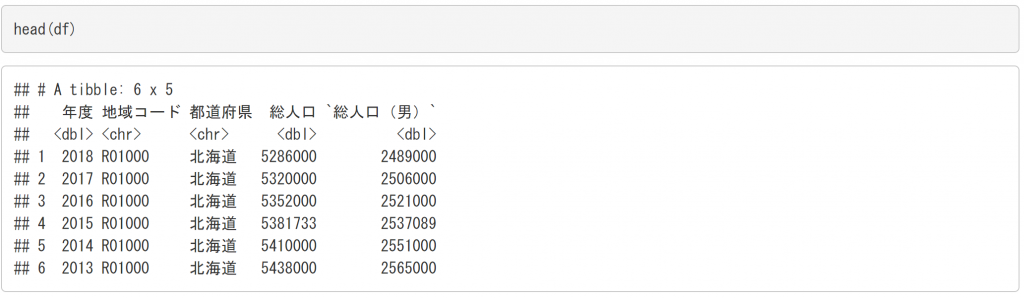
データの先頭を確認してみましょう。
このデータについて、dplyrパッケージとパイプ演算子を使って、以下のような処理を行い、データを抽出します。
- 年度、都道府県、総人口の列だけを抽出する (select() 関数)
- 北海道、東京都、愛知県、大阪府、福岡県のレコードだけを抽出する (filter() 関数、%in% 演算子)
- 2007年と2018年のレコードだけを抽出する (filter() 関数)
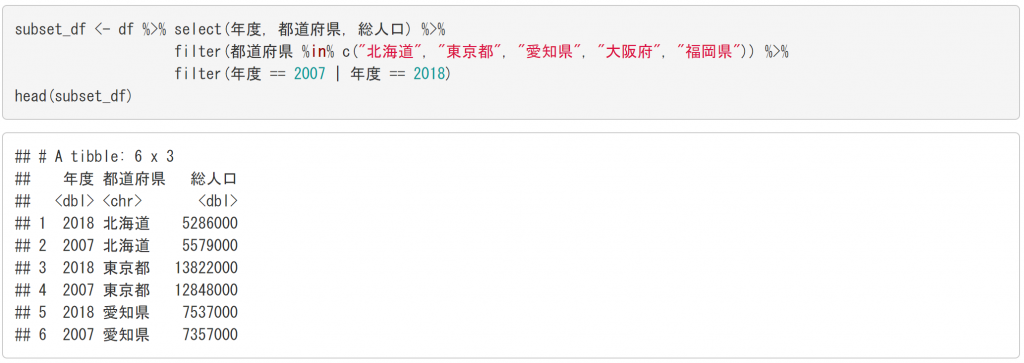
select() 関数は、列を抽出する関数です。列名を指定します。filter() 関数は、行を抽出する関数です。行番号や条件などを指定します。ここでは、組み込みの %in% 演算子を使い、左側の列 (都道府県) の値が、右側のベクトルに一致する行を抽出しています。
さらに、もう一つ filter() 関数を使い、年度列の値が2007または、2018に一致する行だけを抽出しています。
処理した結果をまとめて、subset_df というオブジェクトに代入しています。
次に、2007年から2018年にかけての人口の変化を示す、変化率を計算し、データフレームに追加してみましょう。tidyrパッケージの pivot_wider() 関数と、dplyrパッケージの mutate() 関数を使います。
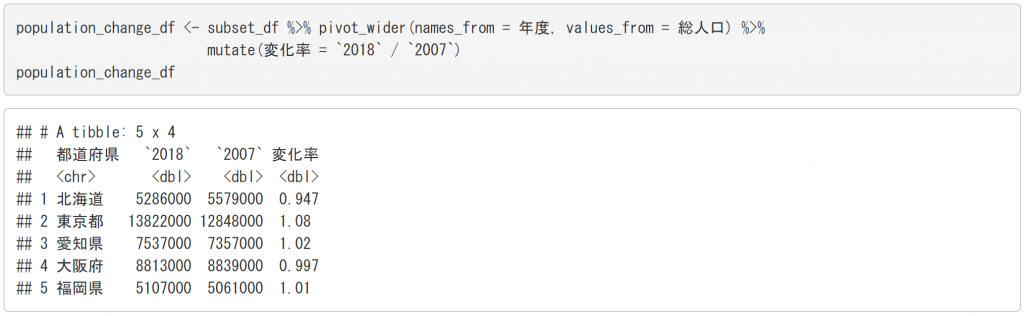
pivot_wider() 関数は、指定した列の値 (ラベル) をもとに、縦長のデータを、横長の形式に変換します。mutate() 関数は、引数に指定した列をデータフレームに追加します。ここでは、割り算の結果を変化率という列名で追加しています。
結果として、北海道と大阪府では2007年と2018年を比べると人口が減少傾向にあり、他の地域では人口が増加していることがわかりました。
この結果を、ggplot2パッケージで可視化してみましょう。その前に、都道府県列をfactor型に変換し、順序を指定します。

forcatsパッケージの as_factor() 関数は、データフレームの列やベクトルをfactor型に変換します。また、mutate() 関数で既存の列を指定することで、上書きができます。さて、加工したデータについて、都道府県名と人口変化率をggplot2で棒グラフとして可視化してみましょう。

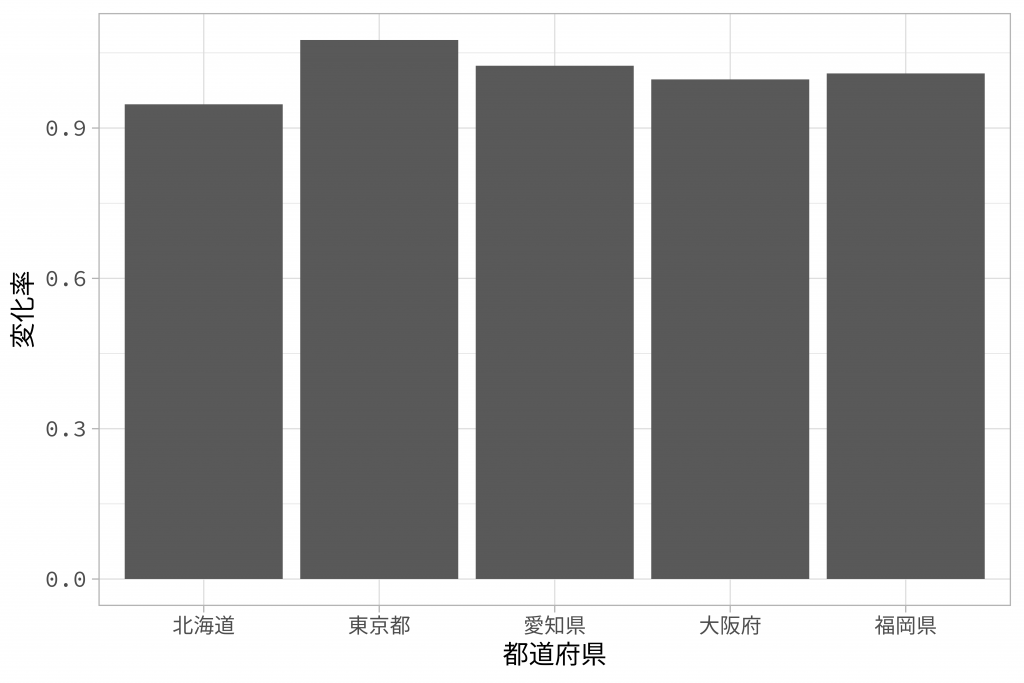
ggplot2パッケージでは、パイプ (%>%) ではなくプラス (+) で処理を繋げていくことに注意してください。
tidyverseを活用して、各都道府県のデータを抽出、集計し、可視化することができました。
ここまでtidyverseパッケージ群の概要と、tidyverseを構成するパッケージの機能を使ったデータ分析の例を紹介してきました。tidyverseは、ここではとても紹介しきれないほどの豊富な機能があります。Rによるデータサイエンスのスキルを高めていくうえで、tidyverseの使い方を学ぶことは必要不可欠です。この記事が、その第一歩となれば幸いです。
AIエンジニアが教えるRとtidyverseによるデータの前処理講座

データ分析プロジェクトで避けては通れないデータの前処理の効率的なやり方を現役AIエンジニアの立場からわかりやすく説明します.このコースを受講することにより,データの前処理のほぼすべて(80%程度)に対応することができます.
\無料でプレビューをチェック!/
講座を見てみる評価:★★★★★
説明が長いとのreviewが多かったのですが、説明の中で、勉強した関数を実務でどのように使用、応用できるのか実例をたくさん見せてくれる所が私はとてもよかったです。お陰様でRを使ったデータ処理がとても楽になりました。shun .先生ありがとうございます!
評価:★★★★★
データの前処理をするためにRを勉強しています。ネットを見ながら独学でやっていましたが、パッケージが色々ありすぎて迷子になってしまい、ここにたどり着きました。ベースRの説明はさらっとした感じですが、tidyverseについては時間をかけてとても丁寧です。実務をされている先生のようで、よく使うものに絞った現実的な内容です。nestの使い方がとても勉強になりました。

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中