

Chat GPTをはじめとするチャットボットの仕組みに欠かせない大規模言語モデル(LLM)。 この記事では、
・LLMの仕組みや具体例
・LLMの活用例
について解説します。LLMを理解することで、チャットボットの有効な活用方法が分かります。チャットボットに関する知識を深めたい方は、ぜひ参考にしてください。
公開日:2023年7月28日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す > 監修
監修
専門領域:AI、データサイエンス、デジタルマーケティング、プログラミング
ウマたん (上野佑馬)
「データサイエンスやAIの力でつまらない非効率を減らしおもしろい非効率を増やす」がビジョンのWW inc.の代表取締役社長。日系大手→外資系→AIスタートアップでデータ分析やデジタルマーケティングを経験。多くの人にもっとデータサイエンスを身近に感じてもらうべく月に10万人が訪れる「スタビジ」というメデイアでデータサイエンスの面白さを発信中。著書に「データサイエンス大全」「漫画でわかるデジタルマーケティング×データ分析」など。
…続きを読む大規模言語モデル(LLM)とは?
LLMは「Large Language Model(ラージ ランゲージ モデル)」の略称で、大規模言語モデルと呼ばれることもあります。LLMとは、大規模なデータセットを用いた機械学習によって精度を高めた自然言語処理モデルのことです。
ディープラーニングによって訓練されたLLMは、様々な用途で活用されます。テキストの生成や文章の要約をはじめ、質問への回答や翻訳、文法の修正といったタスクを処理することが可能です。
名称に大規模とついているものの、規模の大小に関する明確な定義はありません。昨今人気が高まっているChatGPTには、GPT-3やGPT-4というLLMが利用されています。
LLMの将来性
LLMは将来性が高い技術のひとつです。現時点でも実用性の高い技術として幅広い分野で活用していますが、さらに改善の余地が残されています。
今後、より大規模で高性能なモデルが開発され、テキストの理解や生成といった自然言語処理の精度が向上する見込みです。人間のような自然な対話や、前後の文脈を考慮した返答などができるLLMの登場が期待されています。
ただし、LLMの技術向上に伴い、倫理やプライバシーの問題が起きる可能性には注意が必要です。権利侵害などのトラブルを防ぎ、LLMを安全に活用できる体制の整備が求められています。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >LLMの仕組み
LLMが様々な自然言語タスクに適用できるようになるまでの手順は次の通りです。
1.テキストデータの収集と前処理
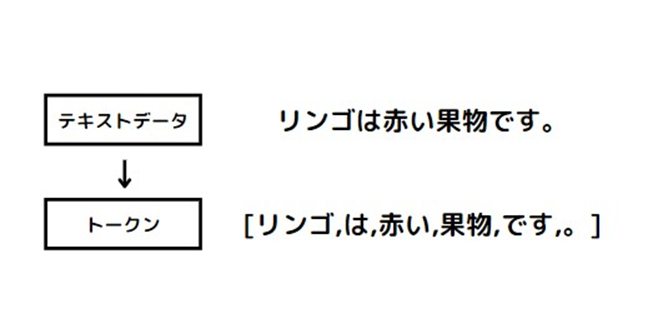
まず、LLMの学習に使用するための大量のテキストデータを収集します。収集したデータをコンピュータが理解できる形式に変換する前処理も行います。主な前処理は、テキストを文ごとや単語ごとに分割するトークン化や、文の区切りなどを表す特殊トークンの追加などです。
2.ベクトルへの変換

文や単語をコンピュータが理解できる数値に変換するために、ベクトル化と呼ばれる処理を行います。分野や単語のトークンを数値に変換することで、コンピュータによる分析が可能です。
3.ニューラルネットワークモデルの構築
トークンのベクトルを入力として、次に続くトークンを予測するようなニューラルネットワークモデルを構築します。LLMでは、Transformerと呼ばれる仕組みをベースとしてモデルを構築することが一般的です。
4.自然言語タスクへの適用
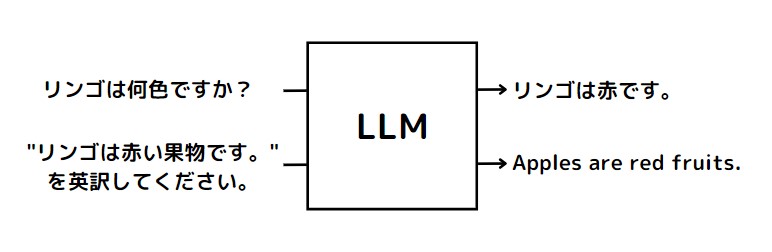
トレーニングされたLLMは、翻訳や文章の生成、質問への回答といった自然言語タスクに適用されます。
主要なLLMの紹介
LLMはこれまでに数多くの種類が開発されてきました。主要なLLMは次の通りです。
Transformer
Transformerは、大規模言語モデルが生まれるきっかけとなったLLMです。Transformerが持つディープラーニングの仕組みは、様々な大規模言語モデルのベースになっています。
Transformerの詳細については下記の記事を参考にしてください。
◆Transformerとは?AI機械学習の仕組みを解説 https://udemy.benesse.co.jp/marketing/transformer.htm
BERT
BERTはGoogleによって開発された言語モデルです。双方向学習と呼ばれる手法により、自然言語処理の性能を向上させています。
BERTの詳細については下記の記事を参考にしてください。
◆BERTとは何か?Googleが誇る最先端技術の仕組みを解説!https://udemy.benesse.co.jp/data-science/chatgpt-bard.html
GPT-3、GPT-4
GPT-3およびGPT-4は、OpenAI社が開発した言語モデルです。文章の生成や質問への応答など、高度な自然言語処理タスクを実行できます。GPT-3やGPT-4はChatGPTに使用されています。
ChatGPTの詳細については下記の記事を参考にしてください。
◆対話型AI「ChatGPT」と「Bard」の違いは?特徴や性能を解説!https://udemy.benesse.co.jp/data-science/ai/bert.html
現在のLLMの課題とは?
現在も開発が進められているLLMには、いくつかの課題も残されています。今後解決が期待されている主な課題は次の通りです。
虚偽の内容を生成する可能性がある
LLMによって生成される文章の内容は、必ずしも正しいとは限りません。大規模言語モデルの学習元に誤った情報が含まれていた場合、LLMで生成された文章の中に虚偽の内容が含まれることがあります。
言語モデルによって嘘が生成されてしまう現象はハルシネーションや幻覚と呼ばれ、問題視されています。
機密情報が引き出される可能性がある
LLMを利用した生成系AIへの指示(プロンプト)によっては、機密情報を引き出すことが可能です。悪意のあるプロンプトを入力し、LLMを通じて機密情報を取得する行為はプロンプトインジェクションと呼ばれます。

プロンプトインジェクションによる被害を防ぐには、機密性の高い情報を生成系AIに入力しないようにするなどの対策が必要です。
学習データの偏り
大量の情報源によって訓練されたLLMは、学習データに偏りが生じている場合があります。学習元に特定のトピックや文化に関する情報が多く含まれていた場合、大規模言語モデルが生成する文章にもバイアスがかかってしまうリスクがあります。
膨大な計算コスト
大規模言語モデルの学習や運用には、計算を行うためのリソースとして多くのコンピュータと、それらを稼働させるためのエネルギーが必要です。必要最小限の電力消費となるように、エネルギー効率の向上が期待されています。
言語によって精度が異なる
使用する言語によって精度が異なる点も、LLMが抱える課題のひとつです。大規模言語モデルはテキストデータをもとに学習を行うため、参照元のボリュームによって精度に違いが生じます。現状では英語で使用した場合の精度が高い傾向があります。
LLMの活用例
膨大な学習データによってトレーニングされたLLMは、様々な自然言語処理タスクに活用されます。
例えば、テーマや読者像などを設定して指示をするだけで、文章を自動で生成することが可能です。また、WebサイトやPDFファイルなどのテキストを読み込み、要約することもできます。
分からないことについて対話形式で質問できるため、知らない分野を学習する際にもLLMが便利です。そのほか、翻訳や文章の自動校正などにもLLMが利用できます。
大規模言語モデルを用いたツールの活用方法をより詳しく知りたい方は、下記の記事も参考にしてください。
◆ChatGPTをもっと使いこなしたい方必見!今知るべき「ChatGPT」の活用方法別おすすめ講座
https://udemy.benesse.co.jp/career/chatgpt.html
まとめ
大規模言語モデル(LLM)とは、膨大な量のテキストデータをもとに学習を行い、自然言語処理のタスクを自動化する技術です。文章の作成や翻訳、質疑応答などを行う生成系AIの多くは、LLMの仕組みを活用しています。AIの技術に興味がある方は、LLMについてより詳しく学んでみてはいかがでしょうか。
これからLLMについてより知識を深めたい人には、下記の講座がおすすめです。
大規模言語モデル(LLM)・生成系AIをディープラーニングの成り立ちから学びPythonで動かしてみよう!

大規模言語モデル(LLM)や生成系AIの流れに乗り遅れるな!パーセプトロン→ディープラーニング→Transformer→GPTモデルまでの流れを総ざらい!概要を理解した後はPythonで動かしてみよう!
\無料でプレビューをチェック!/
講座を見てみるレビューの一部をご紹介
評価:★★★★★
このコースは非常に充実しており、期待以上の価値がありました。LLMモデルや生成系AIの概念を理解することができました。特にAPIを用いたコーディングの実演は非常に役立ちました。この内容は実務でAPIを使用してコーディングをするときに役立つものと感じました。理論と実践の両面をバランスよく学ぶことができ、将来のプロジェクトに活かせるスキルを身につけることができました。これから受講する方にも強くお勧めします。
評価:★★★★★
初心者にわかりやすい整理された内容と説明でした。
LLMの仕組みを理解して、チャットボット開発にチャレンジしましょう!

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中