

Seaborn(シーボーン)は、Pythonでデータを可視化するためのライブラリです。この記事では、Seabornの概要やインストール方法、基本的なグラフの描画方法について解説します。Pythonを使ったデータ分析に興味がある方はぜひ参考にしてください。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >Seabornとは?
Pythonで利用できるデータ可視化ライブラリであるSeabornを活用すると、データの特徴をより分かりやすく把握することができ、機械学習を実施する際にも役立ちます。
Seabornの内部では、データ可視化のためのライブラリであるMatplotlibをベースとしているため、どちらも動作や機能が似ています。Matplotlibの詳細については、以下の記事でご確認ください。
◆Pythonでグラフ描画する方法を解説。Matplotlibを使えば簡単!
Matplotlibとの違い
SeabornとMatplotlibの主な違いは、グラフのデザイン性です。Seabornにはグラフの色分けを自動で行う機能などがあり、Matplotlibより見やすいデザインでデータを可視化できます。
また、複雑なグラフを描画する場合であっても、SeabornではMatplotlibよりも短い行数で実装することが可能です。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >Seabornのインストール
まずは、Pythonをインストールし実行環境を整えた上で、MacのターミナルまたはWindowsのコマンドプロンプトで次のコマンドを入力しましょう。
|
1 |
pip install seaborn |
Pythonの開発環境としてAnacondaを使用している場合、次のコマンドでもSeabornをインストールできます。
|
1 |
conda install seaborn |
Seabornのインストール後、Pythonのプログラム上でライブラリをインポートするためのコードは次の通りです。
|
1 |
import seaborn as sns |
慣例として、「sns」という短縮名でSeabornのインポートを行います。

【Seaborn入門】データの可視化方法を解説!
Seabornのライブラリに予め用意されているデータセット「iris」を用いて、データの可視化方法を解説します。
irisは、アヤメの花のガクの長さや花弁の長さをまとめたデータです。3種類のアヤメに関するデータが各50個体分含まれているため、データ可視化のサンプル素材として活用できます。
Seabornの利用に必要なライブラリをインポートし、irisのデータを読み込むPythonのコードは次の通りです。
|
1 2 3 4 5 6 7 8 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') print(iris.head()) |
最終行にある「head()」は、読み込み済みデータの最初の5行を返す関数です。ただし、head関数そのものにはデータを表示する機能がないため、コンソール上にデータを表示するprint関数と組み合わせています。
コードの実行結果は次の通りです。
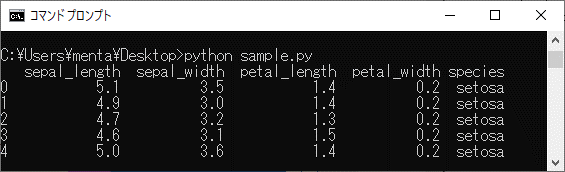
ガクの長さを表す「sepal_length」や、花弁の幅を表す「petal_width」、アヤメの種類を表す「species」といった列を含むデータの冒頭5行が確認できました。
以下では、このデータを用いてSeabornによる基本的なグラフの描画方法を解説します。
ヒストグラム(histplot)
ヒストグラムは、ある変数に対する分布を可視化したい時に用いるグラフです。一般的なヒストグラムはhisplot関数で実装できます。
|
1 2 3 4 5 6 7 8 9 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') sns.histplot(iris, x='sepal_length') plt.show() |
上記の「sepal_length(ガクの長さ)」の値をヒストグラムとして表示するコードを実行すると、次のようなグラフが描画されます。
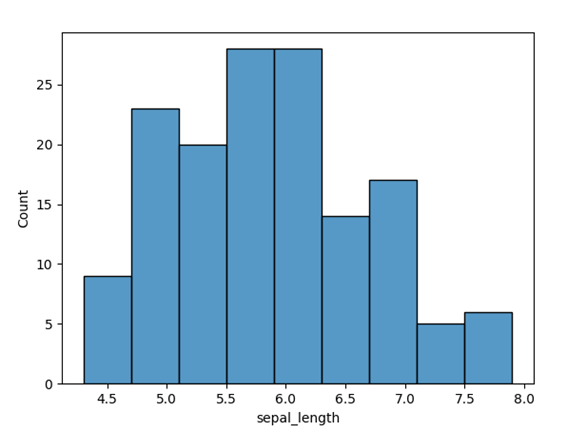
hisplot関数の代わりにdisplot関数を使用しても、ヒストグラムの描画が可能です。displot関数では通常のヒストグラムだけでなく、2変量を指定した散布図のようなグラフも作成できます。
散布図(scatterplot)
散布図は、2つの変数間にある相関関係を確認できるグラフです。散布図はscatterplot関数で実装できます。
|
1 2 3 4 5 6 7 8 9 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') sns.scatterplot(x='sepal_length' , y='petal_length', data=iris) plt.show() |
上記の「sepal_length(ガクの長さ)」をx軸、「petal_length(花弁の長さ)」をy軸にプロットするコードを実行すると、次のような散布図が描画されます。
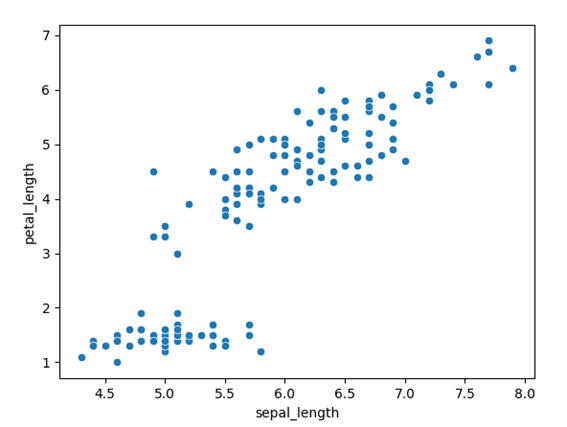
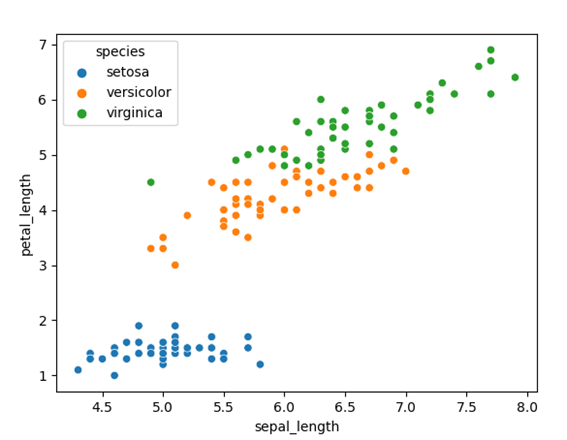
hue引数に列名を指定すると、項目ごとにプロットを色分けできます。例えば、scatterplot関数の部分を次のように書き換えると、アヤメの種類による色分けが可能です。
|
1 |
sns.scatterplot(x='sepal_length' , y='petal_length', hue='species', data=iris) |
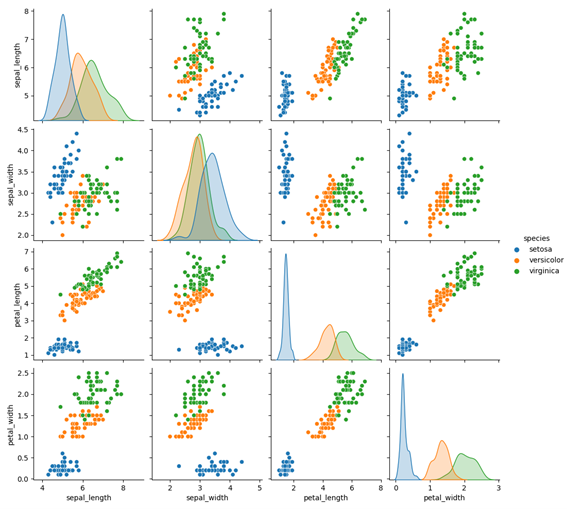
散布図行列(pairplot)
散布図行列とは、三つ以上の変数を含むデータに対して、2変数同士の異なる組み合わせで作成した散布図を行列形式で並べたものです。どの変数同士に相関関係があるかを一目で確認できます。
散布図行列を作る関数はpairplot関数です。hue引数にデータのクラスを表す列名を指定すると、クラスごとに色分けできます。
|
1 2 3 4 5 6 7 8 9 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') sns.pairplot(iris, hue='species') plt.show() |
棒グラフ【平均】(barplot)
barplot関数を用いると、データごとの平均値を棒グラフで表すことが可能です。例えば、x軸に「species(アヤメの種類)」、y軸に「sepal_length(ガクの長さ)」を指定すると、アヤメの種類ごとのガクの長さの平均値が表せます。
|
1 2 3 4 5 6 7 8 9 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') sns.barplot(iris, x='species', y='sepal_length', hue='species') plt.show() |
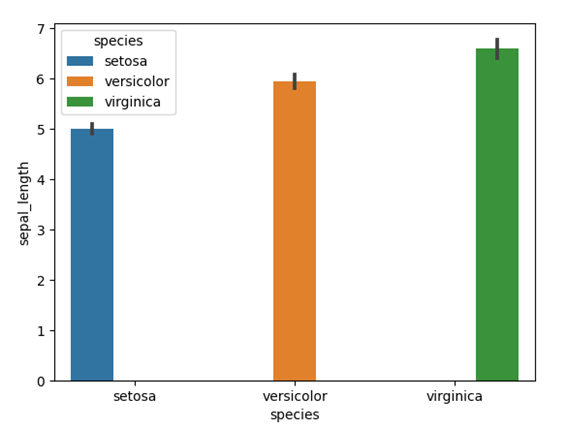
上記の例では、hue引数にも「species(アヤメの種類)」を指定し、種類ごとに色分けをしました。棒グラフの上部にある黒い線はデータの信頼区間を表します。
棒グラフ【個数】(countplot)
countplot関数を使用すると、対象となるデータの個数を集計し、棒グラフで表示することが可能です。x軸に列名を設定した場合、y軸に個数が表示されます。
|
1 2 3 4 5 6 7 8 9 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') sns.countplot(iris, x='petal_width') plt.show() |
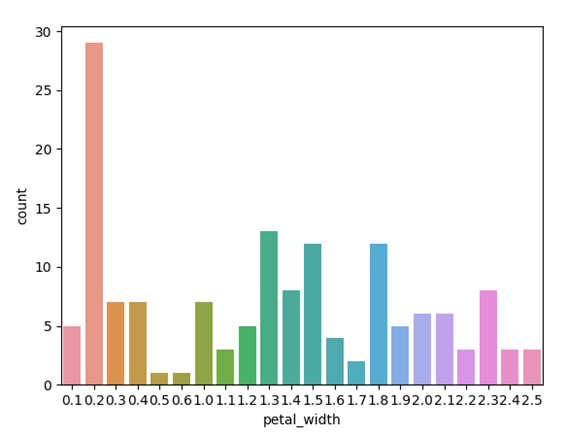
上記は、「petal_width(花弁の幅)」をx軸、データの個数をy軸に設定した例です。反対に、列名をy軸に指定した場合は、x軸が個数となります。
箱ひげ図(boxplot)
箱ひげ図とは、データの上位25%にあたる値や中央値、最大値といった基本統計量を可視化できるグラフです。箱ひげ図はboxplot関数で描画できます。hue引数に列名を指定すると、項目ごとの色分けが可能です。
|
1 2 3 4 5 6 7 8 9 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') sns.boxplot(iris, x='petal_width', y='species', hue='species') plt.show() |
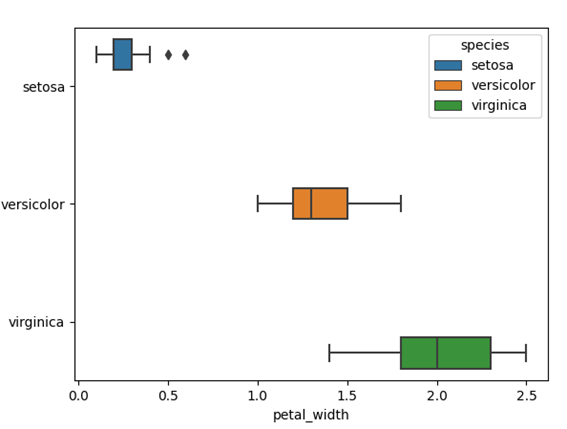
上記の例では、「petal_width(花弁の幅)」の分布を「species(アヤメの種類)」ごとに分けて、箱ひげ図として描画しました。
ヒートマップ(heatmap)
heatmap関数を使用すると、データをヒートマップとして描画したり、グレースケール画像をグラフ化したりできます。
heatmap関数は、引数にデータを直接指定するため、ヒートマップに無関係な情報は予め削除しておく必要があります。以下の例は、irisのデータから「sepal_length(ガクの長さ)」の列だけを残してヒートマップ化するコードです。
|
1 2 3 4 5 6 7 8 9 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') sns.heatmap(iris.drop(columns=['sepal_width', 'petal_length', 'petal_width', 'species'])) plt.show() |
drop関数を用いて、「sepal_width」や「petal_length」など不要な列を削除しています。上記のコードを実行すると、次のようなヒートマップが描画されます。
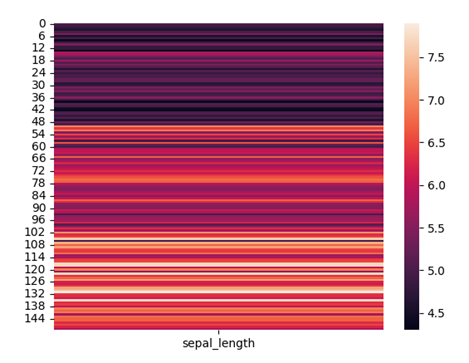
heatmap関数では、annot引数をTrueにすることで、ヒートマップ内にデータの数値を表示できます。また、fmt引数を指定すると、整数や小数など数値の型を変更することが可能です。
バイオリンプロット(violinplot)
バイオリンプロットとは、箱ひげ図では読み取れないデータ分布まで可視化できるグラフです。バイオリンプロットの中心には箱ひげ図が描画されます。
バイオリンプロットを描画するためのviolinplot関数では、hue引数の指定で列名ごとの色分けが可能です。
|
1 2 3 4 5 6 7 8 9 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') sns.boxplot(iris, x='petal_width', y='species', hue='species') plt.show() |
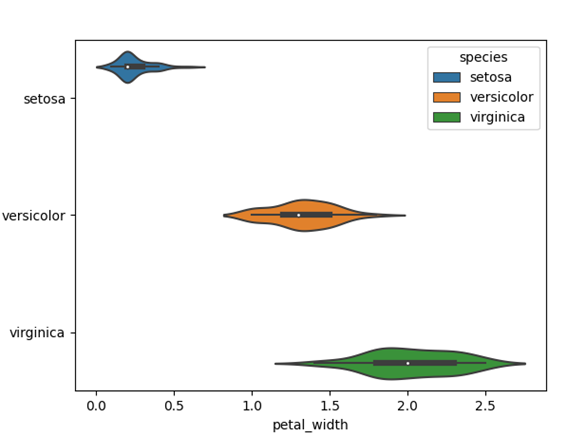
上記の例では、「petal_width(花弁の幅)」のバイオリンプロットが「species(アヤメの種類)」ごとに描画されています。
ポイントプロット(pointplot)
ポイントプロットとは、箱ひげ図を簡略化したグラフです。平均値と信頼区間のみが描画されます。poinplot関数によって描画でき、hue引数による項目ごとの色分けが可能です。
|
1 2 3 4 5 6 7 8 9 |
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np iris = sns.load_dataset('iris') sns.pointplot(iris, x='petal_width', y='species', hue='species') plt.show() |
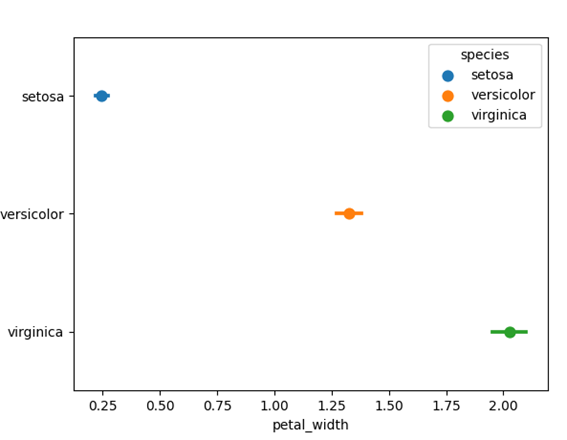
上記の例では、「petal_width(花弁の幅)」のポイントプロットが「species(アヤメの種類)」ごとに描画されています。
Seabornを学べるUdemy講座を紹介!
Seabornには、ここまでに紹介した関数以外にも様々な機能があります。Seabornを含むデータの可視化手法や、データサイエンスについて学びたい方には、Udemyの講座がおすすめです。
次のUdemy講座では、Pythonを使ったデータサイエンスの基礎や実践的なスキルが学べます。
◆米国データサイエンティストがやさしく教えるデータサイエンスのためのPython講座
◆【世界で18万人が受講】実践 Python データサイエンス
英語版のみではあるものの、データの可視化をマスターしたい方には次の講座もおすすめです。
◆2022 Python Data Analysis & Visualization Masterclass
SeabornはPythonで利用できるデータ可視化のためのライブラリで、複雑なデータをシンプルなコードでグラフ化できます。類似の機能を持つMatplotlibと比べて、Seabornではよりデザイン性の高いグラフを作ることが可能です。データ分析を手軽に行いたい方は、ぜひSeabornを活用してください。

 RANKING
RANKING



 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中