

Pythonを使ったWebスクレイピングに取り組みたいものの、
・コードの書き方が分からない…。
・スクレイピングに役立つライブラリが知りたい…。
という方も多いのではないでしょうか。そこでこの記事では、
・Pythonのライブラリを使用したWebスクレイピングの方法
・PythonでWebスクレイピングを行う際の注意点
について、サンプルコードを交えながら解説します。
Webスクレイピングが初めての方でも、この記事を読めばPythonでデータやタイトル、見出しなどを取得する方法がわかります。
Webスクレイピングとは、WebサイトからWebページのHTMLデータを取得し、見出しや写真といった特定のデータを抽出するコンピューターソフトウェア技術のことです。Webスクレイピングによって得られた情報は、不要な部分の削除といった加工が自動的に行われます。そのため、人の手でデータを収集する際にかかる時間を大幅に削減できます。
このWebスクレイピングを行うプログラムのことを「スクレイパ」と言います。なお、Webスクレイピングの作業を始める前に、対象のサイトを「クローリング」する必要があります。クローリングとは、WebサイトからHTMLなどの情報を取得する技術で、クローリングを行うプログラムのことを「クローラー」といいます。
Webスクレイピングは、「スクレイパ」と「クローラー」によって構成されています。

スクレイピングの基本的な流れ
Webスクレイピングを行う時の基本的な手順は以下の通りです。
1.クローリングをして対象のWebページの内部情報を取得する
↓
2.取得したWebページを解析し、スクレイピングをして特定のデータを検索・抽出する
↓
3.スクレイピングして抽出したデータを整形し保存(もしくは表示する)
上記の一連の作業を行うために、Webスクレイピングのライブラリやフレームワークを使用することが多いです。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >Webスクレイピングを行う際の注意点
スクレイピングで特定のデータを抽出する際、自分の管理元にないWebサイトの情報を抽出すると、違法行為になる可能性があります。
違法行為をしてしまうことを未然に防ぐために、注意点がいくつかあります。以下の点に留意して、行いましょう。
Webサイトの利用規約・著作権を事前に確認する
スクレイピングを行うWebサイトの利用規約、著作権を事前に確認しましょう。
Webサイトの中にはページ内の情報の抜き出しを禁止しているものもあります。そのため、抽出した情報を使用する時、著作権法に違反していないか確認しましょう。
robots.txtの指示を守っているのか確認する
robots.txtの指示を守っているかどうかも、Webスクレイピングを行う際に注意するべきポイントです。
robots.txtは検索エンジンのクローラー(ロボット)からWebページへのアクセスを制限するためのファイルです。robots.txtにはアクセスしても良いページ、してはいけないページなどの記述があるので、該当のページのスクレイピングが許可されているか確認しましょう。
アクセスの間隔を空けて負荷を抑える
Webスクレイピングの目的でサーバーにアクセスをする時は、最低1秒以上間隔をあけて、Webサーバーに負荷をかけないようにしてください。
Webサーバーに負荷がかかると、他の閲覧者がサイトを見られなくなったりサーバーが落ちてしまったりします。トラブルの原因とならないよう、Webサーバーへの負荷は極力避けましょう。
スクレイピングに使うプログラムに連絡先を明記する
クローリングをするためのプログラム、クローラーを開発する時は、コード内に連絡先を明示しておくのがおすすめです。
明示しておくことで、問題が起きた時サーバー管理者とスムーズに連絡を取ることができます。連絡先は、クローラーのUser-agentヘッダーにURLやメールアドレスを書きましょう。
Webスクレイピングに利用できるライブラリ
PythonにはWebスクレイピングに適したライブラリが複数用意されています。よく利用されるライブラリは、「Requests」、「Beautiful Soup」、「Selenium」の3つです。
ライブラリによって、出来ることや特徴が異なります。
| ライブラリ | Webページ取得 | データ抽出 | 特徴 |
| Requests | 〇 | × | Webページを取得する。 シンプルで人が直感的に分かりやすいプログラムを記述できる。 |
| Beautiful Soup | × | 〇 | 取得したWebページの情報(HTML)をパースする。 |
| Selenium | 〇 | 〇 | Webページ取得と、データ抽出の両方が利用できる。 JavaScriptが使用されたサイトやログインにも使用できる。 動作が遅いのがデメリット。 |
以下では、それぞれのライブラリについて詳しく解説します。
データを取得するためのスクレイピング【Requests】
Requestsは、Webサイトからデータを取得する機能を持ったライブラリです。ここでは、Webスクレイピングを行うために、Requestsを用いてHTMLデータを取得する処理を、ソースコードも交えて解説していきます。
ライブラリを利用するには、まずインストールが必要です。
Python3系バージョンのRequestsをインストールする時は、以下のコマンドを実行しましょう。
|
1 |
$pip3 install requests |
Requestsのメソッドを解説
ライブラリの機能を実行するために、メソッドを利用します。
Requestsで主に利用するメソッドは次の通りです。
| メソッド | 処理内容 |
| get() | サーバーから情報を取得する |
| post() | サーバーへ情報を登録する |
| put() | サーバーの情報を更新する |
| delete() | サーバーの情報を削除する |
それぞれのメソッドの使い方を詳しく見ていきましょう。
・get()
記述方法は
|
1 |
r= requests.get(URL, <オプション>) |
です。
引数のURLは必須で、<オプション>には任意で値を設定します。
| 引数 | 説明 |
| URL | 読み込み対象のURL |
続いて、<オプション>で利用される引数をいくつか紹介します。
| 引数 | 説明 |
| headers | 辞書を設定することで、ヘッダーとして送信する内容を書き換える |
| timeout | リクエストのタイムアウトを指定する |
| files | バイナリータイプのデータを送信する |
・post()
記述方法は
|
1 |
r= requests.post(URL, <送信データ>) |
です。
URLに対して、送信データを送ることができます。
送信データにはファイルを指定したり、JSONと呼ばれる形式で記述されたデータ列を指定したりすることができます。
・put()
記述方法は
|
1 |
r= requests.put(URL, <更新データ>) |
です。
postと同様にリクエストできます。
・delete()
記述方法は
|
1 |
r= requests.post(URL, <送信データ>) |
です。
postと同様にリクエストし、指定のデータを削除できます。
Webページのデータを取得しよう
それでは実際に、Webページのデータを取得してみましょう。
|
1 2 3 4 5 6 |
importimport requests url = "https://example.com" r= requests.get(url) |
上記を実行すると、response変数に、指定したURLのWebページ情報が取得できます。
Webページ情報が取得できたら、print()を利用して特定の情報を見ることができます。例えば、ヘッダー情報を取得したい時は
|
1 |
print(r.headers) |
を、ボディ内の情報を取得したいなら
|
1 |
print(r.content) |
を実行することで、情報を見ることができます。
タイトルや見出しを取得するためのスクレイピング【BeautifulSoup】
BeautifulSoupは、取得したHTMLデータを解析できるライブラリです。BeautifulSoup自体には、サーバーと情報をやり取りする機能はありません。そのため、まずはRequestsでHTMLデータを取得した上で、BeautifulSoupを使ってページのタイトルや見出しなどの情報を抽出します。
Python3系バージョンの Beautiful Soupをインストールする時は、以下のコマンドを実行しましょう。
|
1 |
$ pip3 install beautifulsoup4 |
BeautifulSoupのメソッドを解説
BeautifulSoupでHTML要素を取得するには、「find系」(find(), find_all())と「select系」(select_one(), select())のメソッドを使用します。
find系も、select系もHTMLの内容を検索し、条件に合う要素を返すという事は同じですが、条件の指定方法が異なります。
find系は、引数にHTMLの属性と属性値を指定します。一方、select系はCSSセレクタと呼ばれる、「何をどの値にするか」を設定した要素(セレクタ)を指定します。どちらを使うかは好みで良いでしょう。
また、メソッドに_allや_oneが付くことで、全ての要素を返すのか、1つだけの要素を返すのかが異なります。
処理速度を気にする場合は、全ての要素だと遅くなるため、1つだけの要素を返すメソッドを使うのがおすすめです。
これらを表で整理すると下記のようになります。
| タイプ | 全ての要素をリストで返す | 1つの要素だけ返す | 検索条件 |
| find系 | find_all() | find() | 属性、属性値 |
| select系 | select() | select_one | CSSセレクタ |
WebページのタイトルやURLを取得しよう
それでは実際に、RequestsでWebページを取得し、BeautifulSoupでタイトルやURLを取得してみましょう。
先に、ソースコードと実行結果です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import requests from bs4 import BeautifulSoup url = "https://example.com" r = requests.get(url) soup = BeautifulSoup(r.content, "html.parser") print(soup.select("h1")) print(soup.select("p")) |
上記コードを実行すると、
|
1 2 3 4 |
[<h1>Example Domain</h1>] [<p>This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.</p>, <p><a href="https://www.iana.org/domains/example">More information...</a></p>] |
のように出力されます。
ソースコードについて解説していきます。
|
1 2 |
import requests from bs4 import BeautifulSoup |
ここで、BeautifulSoupを使用するためにモジュールを読み込みます。
|
1 2 3 4 5 6 |
url = "https://example.com" r = requests.get(url) soup = BeautifulSoup(r.content, "html.parser") |
Requestsを使用し、「https://example.com」のWebページの情報を取得します。
その後、BeautifulSoupの関数を呼び出し、Webページのコンテンツの内容を分析しています。
第2引数で設定されている”html.parser”は分析を行う時に使用するパーサー(解析器)を指定しています。html.parserはPythonの標準ライブラリに入っており、ライブラリの追加が不要です。
この時点で、soupには、Webページのコンテンツの全てが入っています。
|
1 2 3 4 |
print(soup.select("h1")) print(soup.select("p")) |
で、selectメソッドを使用し、条件に合うデータを出力しています。今回は、Webページの、「<h1>」と「<p>」を指定しています。
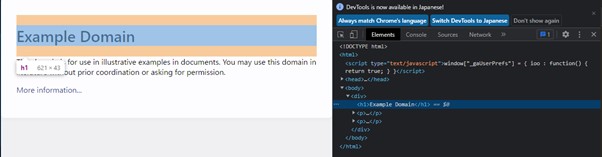
Chromeブラウザであれば、「F12」を押下することで、下記のようにWebページの情報を参照できますので、取得したいデータ情報を簡単に得ることができます。(左側がWebページで、右側がWebページのHTML構造)
Javaで作られたコンテンツを取得するためのスクレイピング【Selenium】
Seleniumとは、Webアプリケーションのテストを自動化するための複数の機能が備わったフレームワークです。その中の1つである「Selenium WebDriver」を使うと、プログラミング言語を通じてブラウザを自動的に操作できます。
また、SeleniumではJavaScriptで動的に生成されるコンテンツも扱うことが可能です。そのため、静的なHTMLだけでなく、動的なWebページをスクレイピングしたい場合に適しています。
Seleniumを用いたWebスクレイピングを行いたい方は、「Selenium WebDriverとは?インストール方法から使い方まで解説」を参考にしてください。
Webスクレイピングを活用して情報解析に役立てよう
今回の記事では、Pythonを使ってWebスクレイピングする方法を紹介しました。
RequestsとBeautifulSoupのライブラリを使用することで、簡単な記述でWebページから情報を取得し、データを解析・抽出することができます。また、Javaなどで作られた動的なページをスクレイピングしたい場合は、Seleniumが便利です。
PythonによるWebスクレイピングさらに詳しく学びたい方には以下の講座がおすすめです。
Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup・Selenium・Requests)

Python3のスクレイピング用ライブラリ BeautifulSoup・Selenium を用いて、世界中のWebサイトからデータを取得します。効率的にデータを収集・活用することで、業務効率化・自動化に貢献するスキルを身に付けましょう!
\無料でプレビューをチェック!/
講座を見てみる評価:★★★★★
私はpython初心者の中年です。その私から見ても落ち着いた話し方に知性を感じ、セリフもあらかじめ作られているので、無駄がなく、優良かつ有料なのも納得です。
評価:★★★★★
Webスクレイピングを体系立てて勉強できました。短期間で広範囲をカバーしているので、大変有意義なコースでした。
Webスクレイピングのやり方を習得することで、自動化したり、面倒な手間を省いたりするツールを作成することも可能ですので、是非使ってみてください。

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中