

近年、ECサイトで買い物をする際、おすすめのサービスや商品として表示されたものが面白そうで、クリックして確認するだけのはずが、つい買ってしまった、という人も多いのではないでしょうか。
本記事では、このおすすめアイテムの表示を実現している主な手法「協調フィルタリング」について解説します。
問題点や例も含めてご紹介することで、初心者でも理解できるように解説していますので、ぜひ最後まで読んで協調フィルタリングとは何かを理解してください。
公開日:2017年11月10日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す > 監修
監修
専門領域:AI、データサイエンス、デジタルマーケティング、プログラミング
ウマたん (上野佑馬)
「データサイエンスやAIの力でつまらない非効率を減らしおもしろい非効率を増やす」がビジョンのWW inc.の代表取締役社長。日系大手→外資系→AIスタートアップでデータ分析やデジタルマーケティングを経験。多くの人にもっとデータサイエンスを身近に感じてもらうべく月に10万人が訪れる「スタビジ」というメデイアでデータサイエンスの面白さを発信中。著書に「データサイエンス大全」「漫画でわかるデジタルマーケティング×データ分析」など。
…続きを読む協調フィルタリングとは?
協調フィルタリングとは、レコメンドシステム(推薦システム)を実現する手法の一つです。
レコメンドシステムは、ECサイトなどでサイトの運営者がサイトの訪問者の好みに合うアイテムを「おすすめ」する際に使用するものです。
訪問者が能動的に行う通常の検索と異なり、「おすすめ」アイテムの表示に際し、運営者の意図(季節商品の上位表示など)を反映させることも可能です。
身近な具体例としては、アマゾンやTSUTAYA DISCAS、楽天ECサイトでのおすすめ商品の提示が挙げられます。
以下に、レコメンドシステムを実現している手法と協調フィルタリングの位置づけを図で示します。
なお、本稿ではレコメンドシステムでよく使われる「狭義の協調フィルタリング」を解説していきます。
◇協調フィルタリングと、協調フィルタリングのレコメンドシステムにおける位置づけ◇
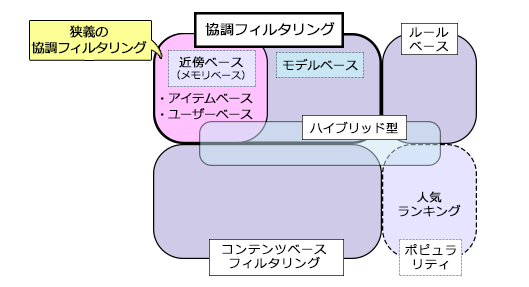
アイテムの購入/選択履歴は、口コミ同様、利用者によるそのアイテムの「おすすめ」とみなせます。
協調フィルタリングはこれを利用し、訪問者と似た行動履歴を持つ利用者のデータ(購買履歴など)を基に、訪問者が購入する可能性が高いアイテムを「おすすめ」として表示します。
訪問者と行動や好みが似た他人が良いと思うものは、訪問者も良いと思う確率が高いだろう、という考えです。
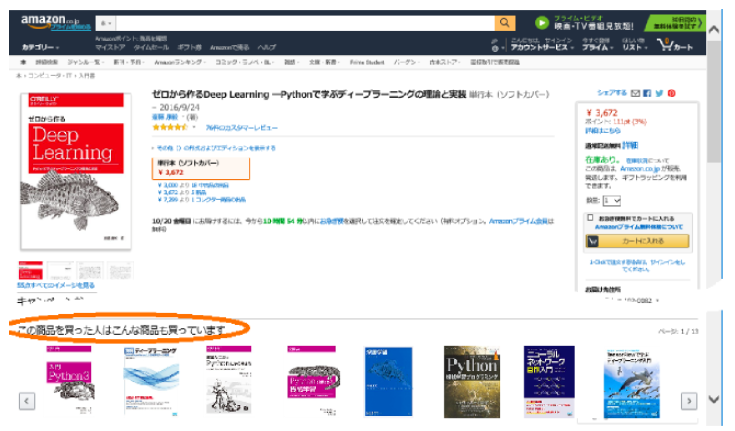
◇アマゾンのレコメンドシステム「この商品を買った人はこんな商品も買っています」◇
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >協調フィルタリングとコンテンツベースフィルタリングとの違い
コンテンツベースフィルタリングとは、レコメンドシステムを実現するもう一つの手法です。
協調フィルタリングでは、訪問者の行動履歴からおすすめアイテムを導いていました。
しかしコンテンツベースフィルタリングでは、事前にアイテムを属性に応じてグルーピングしておき、訪問者が検索したり購入したアイテムと似たアイテムを特徴が似ている順に表示し、おすすめしていきます。
コンテンツベースフィルタリングを利用する場合、予め用意してあるアイテムの情報と訪問者の好みを比較し、類似度の高いアイテムをおすすめすることので必然的におすすめアイテムは訪問者が想定している範囲に収まりがちになります。
これに対して協調フィルタリングでは、訪問者と似た他人の行動履歴を利用するため、訪問者自身についての情報が少ない場合でも比較的訪問者の好みにあったアイテムをおすすめできます。
さらに、類似利用者の行動履歴にあっても訪問者は持っていないアイテムをおすすめ候補にすることから、訪問者の想定の範囲を超えたアイテムをおすすめ(セレンディピティ)できる可能性があります。
また、協調フィルタリングでは類似利用者の行動履歴にあるアイテムをおすすめ候補に使うため、運営者がアイテムの特徴などを知る必要はありません。
コンテンツベースフィルタリングでは事前に行う必要があったアイテムの情報の用意、加工も、協調フィルタリングでは不要なことから、運営者のコスト抑制にも寄与します。
以下は、協調フィルタリングとコンテンツベースフィルタリングの簡単な比較です。
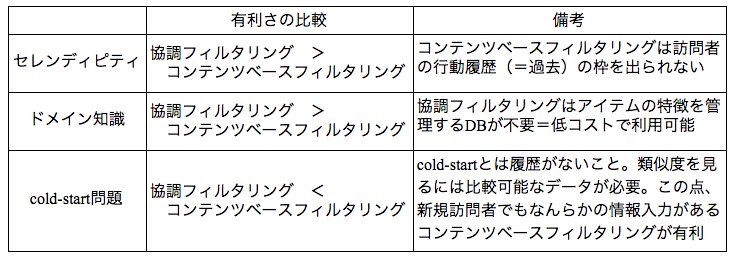
協調フィルタリングの強み
ここでは協調フィルタリングの強みを見ていきましょう。まずは簡単な具体例を紹介します。
【例】
・プレーヤー:A・B・Cの3人
・ゲーム:7種類(①〜⑦)
・遊び方:①〜③の3個はA・B・C全員がプレイする。
Aは①〜③に加えて④と⑤をプレイする。
Bは①〜③に加えて⑥と⑦をプレイする。
Cは①〜③に加えて⑦をプレイする。
プレイ後は①〜⑦のゲームを5段階(1が一番つまらない、5が一番面白い)で評価する。
・結果

結果の評価
①〜③の評価から、AとBは好みが似ていそうです。好みが似ていることを「相関が強い」といいます。従って、AとCは相関が弱そうと言えます。
あるものにおいて好みが似ている人達は、他のものにおいても好みが似ている場合が多いことから、AとBの⑥と⑦のゲームについての感想は似ている可能性が高いと考えられます。
特に⑦のゲームは、Bの評価は高く、Cの評価は低いので、Aは高い確率で⑦を面白いと感じそうです。
ところで、「好み」が度合いを表す以上、例えば評価数値が同じ3でも、評価を甘めにつけるプレーヤーと辛めにつけるプレーヤーの3では意味が違います。
このバイアスの影響を回避するには、全プレーヤーの評価値を、評価基準を揃えた値に変換してから比較します。
なお、今回取り上げた例はゲームという単一ジャンルにおける好みの類似から、まだプレイしていないゲームについての好みを予想しましたが、あるものにおいて好みが似ている人達は、他のものにおいても好みが似ています。
……ということは、他のジャンルでも同じような好みである可能性が高いと考えることが可能です。
このため、例えば上記のAが明るい色の服を好むのであれば、Bもそうであろうと考え、Aの購入履歴を基にBに明るい色の服をおすすめすることで実際にBが気に入って購入することも十分考えられるのです。
協調フィルタリングの強みとは
実際にレコメンドシステムがおすすめアイテムを表示する際は、訪問者と似た利用者何人分の評価を参考にすればよいか、という問題が出てきます。参考にする人数が少ないほど個々の利用者の評価が色濃く出ます。
類似度の高い利用者上位5人の評価を参考にした場合と、上位100人の評価を参考にした場合では、5人の評価を参考にした時の方が、より訪問者の好みに合ったアイテムがおすすめされる可能性も高くなります。
しかし、好みではないアイテムが含まれる可能性も高くなります。機械学習でいえば過学習の状態に陥りやすくなります。
過去の研究からは30~100人を参考にすると、おすすめアイテムの内容が類似利用者の平均的な好みになるそうです。機械学習でいえば頑健性のあるシステムになるといえます。
協調フィルタリングの強みをまとめると、次のようになります。
(1)相関の要因を知らなくても予測が可能である。
(2)アイテムの特徴を知ることなしにおすすめとして挙げることが可能である。
(3)異なるジャンルのアイテムでもおすすめすることが可能である。
協調フィルタリングの欠点
協調フィルタリングの欠点は次のとおりです。
おすすめの対象アイテムが、訪問者と類似の利用者のデータから引けるアイテムに限定される
アイテムの知識がなくてもおすすめアイテムを提示できるのは、訪問者と似た利用者の行動履歴からアイテムを引いてくるからです。
つまり、類似度の高い利用者の行動履歴にないアイテムは誰も評価していないアイテムであることから、おすすめの対象とならないのです。
同じ型で色やサイズだけ異なるようなアイテムをおすすめしてしまう
協調フィルタリングはアイテムの特徴を一切考慮しません。
また、訪問者と類似度の高い利用者は、収入も似通っている場合が多いでしょう。
おすすめの対象にできるアイテムが訪問者と類似度の高い利用者の行動履歴にあるアイテムに限られることから、形は同じで色やサイズだけしか違わない類似品がおすすめに挙がってしまいます。
行動履歴のない訪問者に対応できない
協調フィルタリングでは行動履歴のない訪問者に対応できません。
協調フィルタリングでは、訪問者と既存の利用者との類似度を見ることで、訪問者の好みに合うであろうアイテムをおすすめします。
訪問者が他のサイトでなんらかの行動履歴があるとしても、その情報を取得できない場合は同じです。
少数派問題
行動履歴がそこそこある訪問者でも、その好みが特殊で類似の利用者を見つけることが困難な場合、おすすめアイテムを引いてくるデータベースがないのと同じ状況になります。
このため、協調フィルタリングでは対応が困難です。
スタートアップ問題
新規システムで利用者がまだ誰もいない場合、訪問者が来ても類似度の高い利用者がいないため、協調フィルタリングでは対応できません。
これらの事態を回避・解決するため、実際には異なる2つの協調フィルタリングを組み合わせたハイブリッド型で運用することが多いのです。
いかがでしたでしょうか?
ぜひ協調フィルタリングをマスターして、お仕事にお役立てください。
【Python×協調フィルタリング】レコメンドで使われる協調フィルタリングのアルゴリズムを学びPythonで実装!

レコメンドロジックにはどんな種類があるのかを学び最もよく使われる協調フィルタリングについて理解してPythonで実装していこう!映画の評価データやジョークの評価データを使って協調フィルタリングを実装してみよう!
\無料でプレビューをチェック!/
講座を見てみる評価:★★★★★
Pythonの基礎から協調フィルタリングを実際に試すところまでを理解できるコースです。協調フィルタリングを勉強するきっかけや導入にお勧めだと思います。
評価:★★★★★
イラストも交えて説明してくれるので、とてもわかりやすかったです

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中