転移学習(Transfer Learning)とは、ある領域で学習したこと(学習済みモデル)を別の領域に役立たせ、効率的に学習させる方法です。
今回は、人工知能(AI)分野で欠かせない、転移学習のメリットとアプローチ手法、ファインチューニングとの違いについてお伝えします。
公開日:2019年9月26日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す > 監修
監修
専門領域:人工知能(AI) / 生成AI / ディープラーニング / 機械学習
我妻 幸長 Yukinaga Azuma
「ヒトとAIの共生」がミッションの会社、SAI-Lab株式会社の代表取締役。AIの教育/研究/アート。東北大学大学院理学研究科、物理学専攻修了。博士(理学)。法政大学デザイン工学部兼任講師。オンライン教育プラットフォームUdemyで、十数万人にAIを教える人気講師。複数の有名企業でAI技術を指導。「AGI福岡」「自由研究室 AIRS-Lab」を主宰。著書に、「はじめてのディープラーニング」「はじめてのディープラーニング2」(SBクリエイティブ)、「Pythonで動かして学ぶ!あたらしい数学の教科書」「あたらしい脳科学と人工知能の教科書」「Google Colaboratoryで学ぶ! あたらしい人工知能技術の教科書」「PyTorchで作る!深層学習モデル・AI アプリ開発入門」「BERT実践入門」「生成AIプロンプトエンジニアリング入門」(翔泳社)。共著に「No.1スクール講師陣による 世界一受けたいiPhoneアプリ開発の授業」(技術評論社)。
…続きを読む転移学習とは?:学習の効率化を実現
転移学習(Transfer Learning)とは、ある領域で学習したこと(学習済みモデル)を別の領域に役立たせ、効率的に学習させる方法です。
人間に置き換えると、「友達がまとめたテスト勉強用ノートを借りる」「姉が実践してうまくいったダイエット法を真似する」というイメージです。
ただし、転移学習では、人でいうところの「友達がまとめた理科のノートを国語の勉強に活用する」「姉のダイエット方法を弟の婚活に応用する」といったことが可能となります。つまり、例えば画像認識なら「魚の種類に関する学習済モデルを利用して、車の画像から車種と年式を識別するシステムを簡単に作る」という使い回しが可能です。
転移学習は、機械学習の中で、人間の力に近づく可能性があると言われている分野です。

従来の機械学習では、場合によっては数十万~数百万という教師データを準備しなければなりませんでした。また、データの一つひとつへのラベル付けも欠かせません。機械学習を実行するスピードも重要であるため、相応のスペックを持つシステム基盤を準備することも必要になってきます。
このように、従来は、機械学習を完了させるまでに相応の時間とコストがかかっていました。このコストを少なくするために、一度学習したことを別のものにも使い回すという転移学習が用いられています。
ラベル付けや学習の時間、また学習に耐えられるスペックのシステムを準備することを考えると、もはや転移学習は機械学習においてなくてはならない手法といってもよいでしょう。
転移学習を行うメリット
転移学習を導入すると、どのようなメリットがあるのでしょうか。大きく2つのメリットが考えられます。
-
転移学習を行うメリット①学習時間を短縮できる
同じ分野で十分に学習された学習済みモデルを利用すると、少ないデータ量かつ短い時間で学習可能です。特に画像認識の分野では、コンテストで優秀な成績を収めた学習モデルが多数公開されているため、それらを利用することができます。
0からデータを学習させる場合は、膨大な時間が必要です。学習させるデータも同じようなデータばかりではなく、様々なパターンのデータを読み込ませなくてはなりません。また、サーバーのスペックも要求され、スペックが低いと学習に数十日かかることもあります。

その点、転移学習は学習が完了したモデルに新たな学習を追加して対応するため、学習のための計算量を少なくできます。しかし、新しい学習が必要であることには変わりありません。何をどれだけ学習させるかには、十分な検討が必要です。
-
転移学習を行うメリット②データが少なくても高い精度を出せる
画像認識などの分野では、学習させるための良質なデータセットがインターネットから自由にダウンロードできる場合もあります。しかし実際には、都合よく質の高いデータが膨大に集まっているというケースは少なく、大抵の場合はデータの収集から始めなくてはなりません。
まずデータのサンプルを数万~数十万個収集し、その後にデータの選別が必要です。さらに、採取に失敗したデータや、予期されたものから外れすぎているデータは、学習データとして使えません。
選別は、多くの場合手動で実施しなければならず、途方もない手間を要することもあります。さらに、ここから実際に人工知能へ学習させる工程も待っています。このような方法では、人工知能が実際に使えるようになるまでに相当な時間を要することは明白です。
しかし、転移学習ならば、すでに学習済みのモデルを使用できるため、追加できるデータ量が少なくても機械学習のモデルを構築したい時に役立ちます。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >転移学習のアプローチ手法
ここでは、一般的な学習済みモデルの適用による転移学習の流れをお伝えします。転移学習の流れとしては次のような形です。
①入力画像・音声などから、特徴量を抽出
まずは、すでに学習済みモデルの最終層以外の部分を利用して、データ内の特徴量を抽出していきます。この時、学習済みのモデルは「特徴抽出器」として扱われます。
このステップでは、特徴量の抽出のみが目的で、まだ学習には入りません。
②抽出した特徴量を用いて、クラス分類する
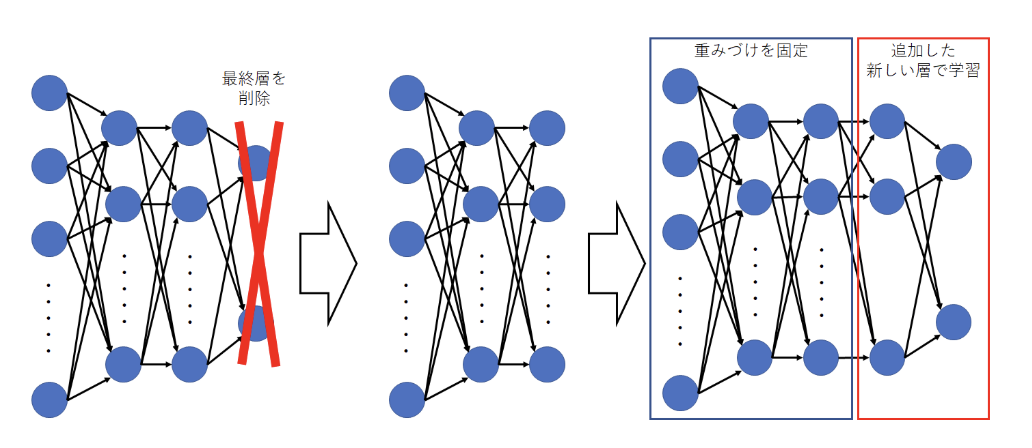
クラス分類とは、複数のデータをある決まったカテゴリに分類することです。①で実際に抽出した特徴量を用いて、新しく追加したモデルに学習を施します。
特に画像や音声を識別するモデルは他の分野に比べて流用しやすいため、転移学習が役立つでしょう。
転移学習のアプローチ:ドメイン適応
ここで、「ドメイン適応」と呼ばれる転移学習の手法についてお伝えします。ドメインとは、日本語で「領域」ともいい、何についてのデータの集まりであるかを表す言葉です。冒頭の例であれば、「魚の種類」「車種と年式」がドメインです。
ドメイン適応の手法をとると、十分な教師ラベルを持つドメイン(ソースドメイン)から得られた知識を、十分な情報がない目標のドメイン(ターゲットドメイン)に適用することができます。
ドメイン適応の使用可否を判断するポイントは、次の2点です。
- ソースドメインにラベル付けがされていること
- ターゲットドメインのサンプル分布をソースドメインの分布に近付けること
この2点のポイントが満たせない場合は、ドメイン適応による学習は困難なものとなってしまいます。
また2点のポイントが満たされていても、ターゲットドメインに対する識別性が十分に保証されないという問題があります。この問題に対して、東京大学の疑似ラベルの適用手法をはじめ、さまざまな手法が提案されています。
転移学習とファインチューニングの違いは?
転移学習とファインチューニングは、どちらも学習済みのモデルを使用した機械学習の手法です。よく混同されてしまいますが、この2つの手法は異なります。
それぞれの違いを見ていきましょう。
- ファインチューニング
ファインチューニングは、学習済みモデルの層の重みを微調整する手法です。学習済みモデルの重みを初期値とし、再度学習することによって微調整します。
- 転移学習
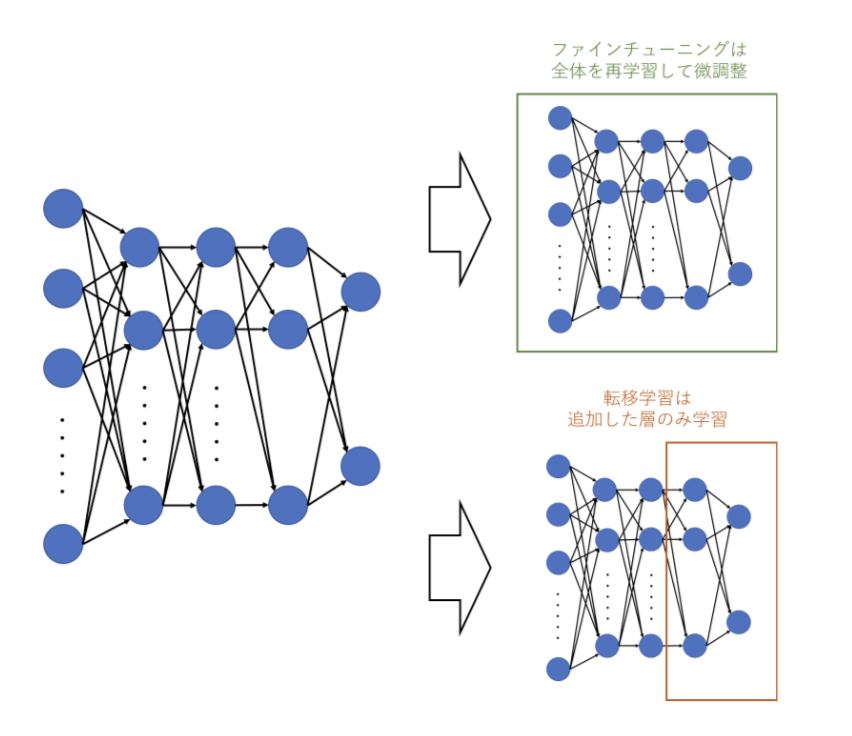
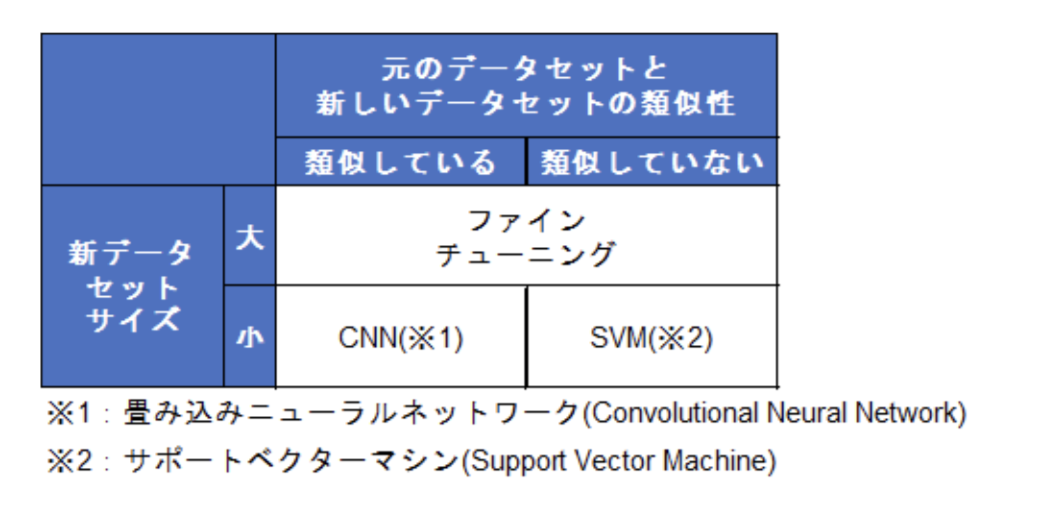
転移学習は、学習済みモデルの重みは固定し、追加した層のみを使用して学習します。スタンフォード大学から発行されているドキュメント「CS231n Convolutional Neural Networks for Visual Recognition」によると、次の表のような手法適用の判断ポイントがあると述べられています。転移学習は、すでに学習済みのモデルを流用し、学習に対するコストを少なくする手法です。ゼロから新しく学習させるよりも、高い精度の結果を出せる可能性が高まります。
ただし、ラベル付けの精度など、転移学習についてはまだ課題が残されているのも事実です。しかし、今も世界中で新たな手法が模索されています。スムーズなモデルの流用が可能になれば、より広い分野でAIが活躍する未来は、そう遠くないかもしれません。
AIパーフェクトマスター講座 -Google Colaboratoryで隅々まで学ぶ実用的な人工知能/機械学習-

ディープラーニングを中心に、AI技術を包括的に身に付けるためのコースです。画像識別や画像生成、RNNや強化学習などの有用な人工知能技術を幅広く学び、人工知能Webアプリの構築までを行います。開発環境にはGoogle Colabを使用します。
\無料でプレビューをチェック!/
講座を見てみる評価:★★★★★
数式の解説も丁寧、スライドもすごく丁寧。あと欲を言うなら、講座作成時点からPythonや各種ライブラリもアップデートして書き方変わってるので、それらを補完するすべが何か知れたら良かったです。
評価:★★★★★
一貫したAI技術を、総まとめされており、さらに現状の課題と対策も併せているので、初学者としては、大変参考になります。

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中