近年のAIの技術の進歩には、深層学習 (ディープラーニング) モデルのTransformerが大きな役割を果たしています。この記事では、
・Transformerの仕組みや使用するメリット
・Transformerをベースにした言語モデル
について解説します。AIについて知識を深めたい方はぜひ参考にしてください。
公開日:2023年7月28日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >INDEX
ChatGPTのベースにもなったTransformerとは?
Transformerとは、AIの性能を向上させるための深層学習(ディープラーニング)モデルのひとつです。自然言語処理に関する論文として2017年に発表された『Attention Is All You Need』の中で初めて登場しました。
従来の深層学習モデルと異なり、Recurrent層や畳み込み層を使用せず、Attention層のみを用いて学習を行うことがTransformerの特徴です。この特徴により、従来よりも高速かつ精度の高い自然言語処理が可能となりました。
Transformerは機械翻訳を中心として、幅広い分野で応用されています。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >Transformerの仕組み
ここでは、Transformerが具体的にどのような仕組みで処理を行っているかについて解説します。
EncoderとDecoderに分けられる
次の図は、Transformerの構造の全体像を表したものです。
Transformerは、Encoder(エンコーダ)とDecoder(デコーダ)という2つの部分で構成されています。
エンコーダの役割は、Transformerに入力されたデータを機械が処理できる形式に変換することです。例えば、言語翻訳のための学習では、英語などで書かれた文章が入力されエンコーダによって数値のベクトルに変換されます。
一方、デコーダの役割は、エンコーダによって変換されたデータを受け取り、処理内容に応じて別の形式へ変換することです。例えば、英語から日本語への翻訳を行う際は、数値のベクトルに変換された英語の文章を日本語の文章へと変換します。
Transformerの仕組みが発表された論文では、エンコーダとデコーダの層がそれぞれ6つずつ用意されていました。現在は、必要に応じて層の数が調整される場合もあります。
従来の深層学習モデルには、エンコーダやデコーダにRNN( リカレント ニューラル ネットワーク )と呼ばれる仕組みが採用されていました。しかし、RNNには情報を逐次処理するため速度が遅いことや、長い文章などが入力されると精度が下がるといった欠点があります。
一方、TransformerはRNNを使うことなくエンコーダやデコーダの仕組みを構築しているため、高速かつ高精度な学習が可能です。
Multi-head Attention層
Transformerのエンコーダとデコーダの中には、それぞれ「Multi-head Attention」という層があります。
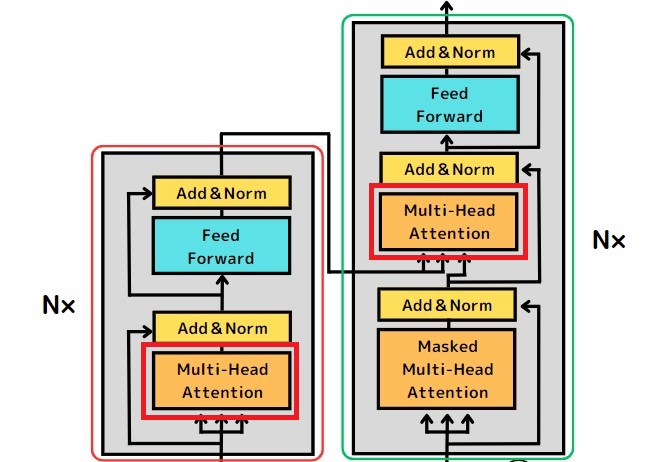
「Attention」とは、深層学習モデルが学習を行う際に、入力されたデータのどの単語に注目するかを決めるための仕組みです。Transformerの「Multi-head Attention」は「Attention」が発展したもので、同時に複数の箇所に注目できます。
デコーダには、「Multi-Head Attention」と同様の機能を持つ「Masked Multi-Head Attention」という層があります。
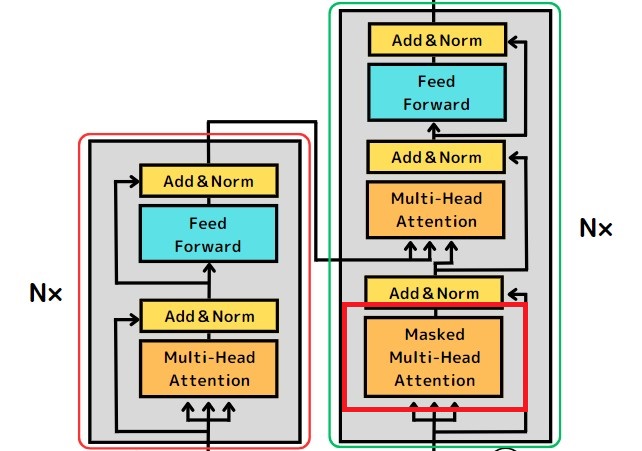
「Masked Multi-Head Attention」は、情報の一部をマスクした状態で機能する点が特徴です。具体的には、Transformerが自身で出力した情報を隠した状態でデータを処理します。
Transformerが出力した情報を自己参照しながら学習を行ってしまうと、学習モデルが不正確になるリスクがあります。学習モデルが実際に使用される場面では、入力された情報以外を参照することはできません。自己参照による学習を防ぎ、学習モデルの精度を高めることが、情報をマスクする理由です。
Neural Network層
Transformerのエンコーダ、デコーダにはそれぞれ「Feed Forward」と呼ばれる層があります。
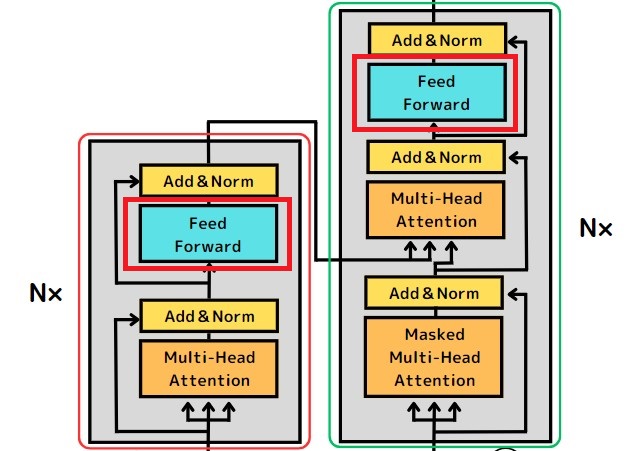
「Feed Forward」はNeural Network(ニューラルネットワーク)層の一種で、入力された情報を線形変換するための仕組みです。
ニューラルネットワークの詳細については、下記の記事を参考にしてください。
◆ニューラルネットワークとは?人工知能の基本を初心者向けに解説!
(https://udemy.benesse.co.jp/data-science/ai/neural-network.html)
Transformerを使用するメリット
深層学習モデルとしてTransformerを使用すると、従来のモデルにはない次のようなメリットが得られます。
並列処理ができる
Transformerは入力された情報を並列処理でき、機会学習のスピードが速いことが特徴です。並列処理とは、複数の命令を同時に実行することです。従来の深層学習モデルであるRNNでは、テキストなどの情報を1単語ずつしか処理できませんでした。
一方、Transformerは同時に複数の単語を処理し、機械学習を進めることができます。
長期記憶ができる
Transformerは、長い文章などのデータが入力された場合でも、前半の内容を忘れずに後半まで処理を行うことが可能です。
従来型のRNNでは、文中の単語を順番に処理していく方式のため、処理の途中で古い情報を忘れてしまうという現象が起きていました。Transformerは長期記憶が可能なため、長いテキストであっても正確に処理できます。
Transformerをベースにしたモデル
Transformerは、これまで様々な大規模言語モデルの開発に応用されてきました。Transformerをベースとして開発された主な言語モデルは次の通りです。
BERT
BERTは、Transformerの仕組みをベースとして開発され、2018年10月11日にGoogleによってリリースされた自然言語処理モデルです。英語版のGoogleの検索エンジンには、BERTが取り入れられています。
BERTの特徴や仕組みについては、次の記事を参考にしてください。
◆BERTとは何か?Googleが誇る最先端技術の仕組みを解説!
(https://udemy.benesse.co.jp/data-science/ai/bert.html)
GPT
GPTは、OpenAI社によって開発されたTransformerをベースとする言語生成モデルです。対話形式で利用できるAIのChatGPTに利用されています。自然なテキストの生成などが得意分野です。
GPTの活用例や特徴については、次の記事を参考にしてください。
◆ChatGPTをもっと使いこなしたい方必見!今知るべき「ChatGPT」の活用方法別おすすめ講座
(https://udemy.benesse.co.jp/career/chatgpt.html)
◆対話型AI「ChatGPT」と「Bard」の違いは?特徴や性能を解説!
(https://udemy.benesse.co.jp/data-science/chatgpt-bard.html)
◆ChatGPT APIを使ったチャットボット開発を初心者向けに解説!
(https://udemy.benesse.co.jp/development/system/chatgpt-chatbot.html)
PaLM
PaLMとは、Googleの研究者チームによって2022年4月に発表された言語モデルです。BERTと同じくTransformerをベースに開発されていますが、より多くのパラメータを持っていることがPaLMの特徴として挙げられます。
大規模なニューラルネットワークを持つPaLMは、言語の翻訳や理解だけでなく、推論やプログラミングコードの生成など様々な処理が可能です。
Conformer
Conformerは、Transformerと従来型の畳み込みニューラルネットワーク(CNN)を組み合わせて作られたモデルです。
Transformerは入力された情報全体の文脈を踏まえた解析を得意としています。例えば、長いテキストの前半に言及された内容を踏まえて、後半の内容を認識することが可能です。

一方、CNNは局所的な情報の解析を得意としています。例えば、音声データの波形などの細かなパターンを認識し、何の言葉が発話されているかを特定することが可能です。
Conformerは、これら2つの特性を組み合わせて作られています。CNNにより音声データから発話されている言葉を解析し、Transformerで全体の文脈を踏まえて文章化できるため、文字起こしなどの音声認識タスクが得意です。
DeFormer
DeFormerは、Transformerの仕組みをベースとして、より高速に動作するように改善されたモデルです。Transformerの機能を分解し、必要な処理だけを行うようにすることで、使用メモリを削減しています。DeFormerを利用すると、質問へ回答するタスクにかかる時間の短縮が可能です。
T5
T5は、2020年にGoogleによって発表されたテキスト生成モデルです。Transformerをベースに、モデルの構造や使用するパラメータなどを調整して開発されました。
入力と出力をいずれもテキストの形式で扱うことがT5の特徴です。様々なタスクをテキストのみで処理するため、翻訳や文章生成など様々な事柄を1つのモデルで対応できます。
Transformerに関連する用語
ここでは、Transformerと関連性の高い主な用語について解説します。
RNN, CNN
RNN( リカレント ニューラル ネットワーク )とは、再帰型ニューラルネットワークとも呼ばれる仕組みです。RNNは、時系列の順序を含むデータを扱うことができます。また、テキストの文脈を考慮できるため、機械翻訳などのタスクに用いられます。
CNN(コンボリューション ニューラル ネットワーク)とは、畳み込みニューラルネットワークとも呼ばれる仕組みです。CNNは各層のニューロンが互いに全て接続された全結合型ではなく、入力データの一部のみと接続される順伝播型のニューラルネットワークです。CNNは自然言語処理だけでなく、画像認識処理にも活用されます。
CNNの詳細については、次の記事も参考にしてください。
◆畳み込みニューラルネットワークとは?手順も丁寧に解説
(https://udemy.benesse.co.jp/data-science/ai/convolution-neural-network.html)
深層学習(ディープラーニング)モデル
深層学習モデルとは、十分な学習データに基づき、インプットされたデータの特徴を機械が自動的に抽出する仕組みのことです。深層学習モデルには、人間の神経回路を模して構築された多層ニューラルネットワークが利用されています。画像処理や自然言語処理などが、深層学習モデルの活用される主な分野です。
ディープラーニングの詳細については、次の記事を参考にしてください。
◆話題のディープラーニングとは?初心者向けに1から徹底解説!
(https://udemy.benesse.co.jp/data-science/deep-learning/deeplearning.html)
自然言語処理 (NLP)
自然言語処理とは、人間が日常的に用いる言語である自然言語で書かれたテキストを、機械によって処理する技術です。自然言語処理機能を備えたAIは、日本語や英語などで書かれた文章を分析したり、自然なテキストを生成したりできます。
自然言語処理の概要や主な活用方法については、次の記事を参考にしてください。
◆NLPとは?AI(人工知能)分野のNLP(自然言語処理)をわかりやすく解説!
(https://udemy.benesse.co.jp/data-science/ai/nlp.html)
◆自然言語処理とは?スマートスピーカーにも使われている技術をわかりやすく解説!
(https://udemy.benesse.co.jp/data-science/ai/language-processing.html)
まとめ
深層学習モデルのひとつであるTransformerは、様々な生成系AIの発展を支える仕組みです。TransformerはAttentionと呼ばれる層のみで機械学習ができ、従来型のモデルよりも高速かつ正確にタスクを処理できます。ChatGPTなど、Transformerをベースとして開発された生成系AIを用いて、業務効率化に取り組んでみてはいかがでしょうか。
これからAIの仕組みについてより知識を深めたい人には、下記の講座がおすすめです。
GPTを自作して大規模言語モデルを理解する:PythonでTransformerとAttentionを学ぶLLM機械学習

GPT1の部品を作りながらPyTorchでGPT本体を自作します。LLMがどのように作用しているのか本体を自作してコードレベルで見ていきます。レクチャーの内容に応じてニューラルネットワークについても触れていきます。
\無料でプレビューをチェック!/
講座を見てみるレビューの一部をご紹介
評価:★★★★☆
図解による直感的な理解に終始せず、
プログラミングを進めることで理解が深まったと思う。
Transformerの仕組みを知って、AIの知識を深めましょう!

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中