

最新の音声認識技術「Whisper」に興味はあるけれど、
・Whisperの具体的な機能や使い方がよくわからない…。
・どのようにしてWhisperをビジネスや日常生活で活用できるのか知りたい…。
こんな悩みを持っている方は多いのではないでしょうか?そこでこの記事では、
・Whisperの基本的な特徴と機能
・Whisperの効果的な使い方と活用例
について詳しく解説します。
Whisperを使えば、時間を節約し、編集作業をスムーズに進めることが可能ですので、この記事を読んで、Whisperの魅力を最大限に活用しましょう。
公開日: 2023年11月30日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す > 監修
監修
専門領域:人工知能(AI) / 生成AI / ディープラーニング / 機械学習
我妻 幸長 Yukinaga Azuma
「ヒトとAIの共生」がミッションの会社、SAI-Lab株式会社の代表取締役。AIの教育/研究/アート。東北大学大学院理学研究科、物理学専攻修了。博士(理学)。法政大学デザイン工学部兼任講師。オンライン教育プラットフォームUdemyで、十数万人にAIを教える人気講師。複数の有名企業でAI技術を指導。「AGI福岡」「自由研究室 AIRS-Lab」を主宰。著書に、「はじめてのディープラーニング」「はじめてのディープラーニング2」(SBクリエイティブ)、「Pythonで動かして学ぶ!あたらしい数学の教科書」「あたらしい脳科学と人工知能の教科書」「Google Colaboratoryで学ぶ! あたらしい人工知能技術の教科書」「PyTorchで作る!深層学習モデル・AI アプリ開発入門」「BERT実践入門」「生成AIプロンプトエンジニアリング入門」(翔泳社)。共著に「No.1スクール講師陣による 世界一受けたいiPhoneアプリ開発の授業」(技術評論社)。
…続きを読むINDEX
Whisperとは?
Whisperは、OpenAIによって開発された無料の音声認識モデルで、文字起こしサービスとして一般に公開されています。このモデルは、Webから収集された68万時間分の多言語音声データを用いて教師付き学習を行っているため、高い精度で音声をテキストに変換できます。日本語でも高い精度で文字起こしができ、多言語対応している点がWhisperの大きな強みです。
また、WhisperはAPIを通じて利用することができます。例えば、音声ファイルを自動的にテキストに変換する機能を追加するなど、開発者は独自のアプリケーションやサービスにWhisperの機能を組み込むことが可能です。
Whisperの利用方法には、Google Colaboratoryを使用したり、Hugging Faceというオープンソースコミュニティを通じて利用したりする方法があります。これらのプラットフォームを利用することで、ユーザーは簡単にWhisperを試すことができ、その高い精度と使いやすさを気軽に体験できます。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >Whisperのモデルサイズの特徴
OpenAIが開発した音声認識モデル「Whisper」には、書き起こしに用いるモデルサイズが5つ存在します。これらのモデルは、サイズが大きくなるにつれて書き起こしの精度が向上していきます。
以下は、各モデルサイズにおける特徴の概要です。
| モデルサイズの種類 | 特徴 |
| Tinyモデル | 最も小さいモデルで、精度は最も低い。漢字、カタカナ、平仮名の書き起こしが不十分な場合が多い。 |
| Baseモデル | Tinyより大きいモデルで、漢字・カタカナ・平仮名の書き分けが上手くいっているが、誤字が存在する。 |
| Smallモデル | Baseよりも文字起こし精度が高いが、カタカナ語の書き起こしが不完全な場合がある。 |
| Mediumモデル | ほとんどの音を正確に文字起こしできる。句読点なども適切なタイミングで打たれる。 |
| Largeモデル | 最も大きいモデルで、ほぼ全ての音を正確な日本語として書き起こすことができる。 |
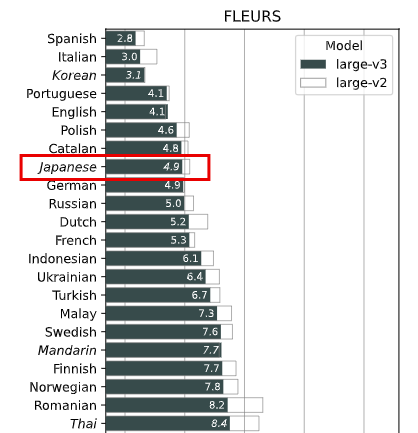
日本語の文字起こしの精度は、公開されている「単語誤り率」で「4.9%」と報告されており、95.1%の高い精度で文字起こしができています。
Whisperが音声を認識する仕組み
Whisperは、DALL・EやChatGPTなど、他のOpenAIのモデルの基盤にもなっているTransformerという技術がベースで、入力はログメルスペクトログラムで行います。
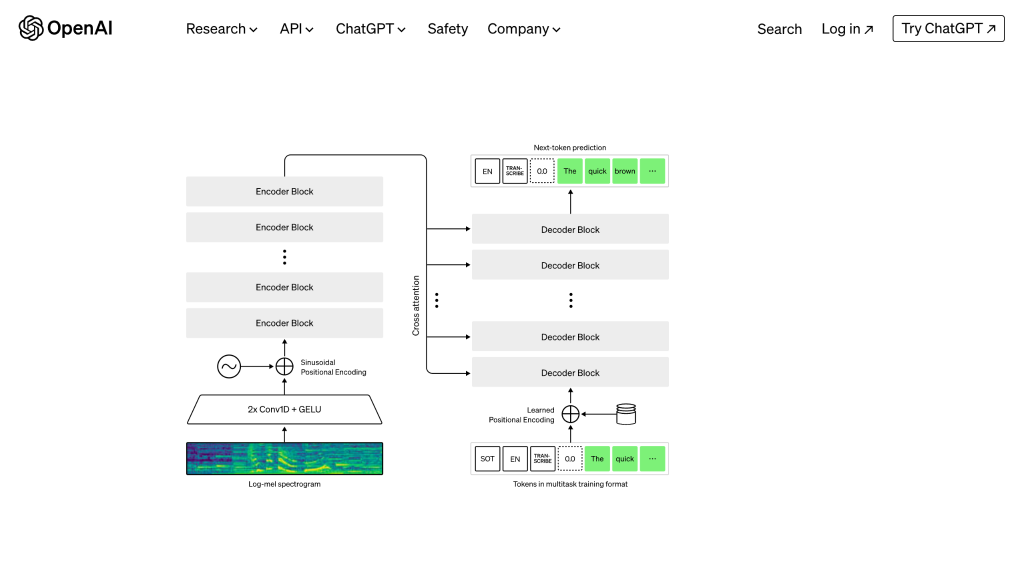
具体的には、入力された音声は30秒単位に区切られ、メルスペクトログラムという、人間の耳の知覚に近いメル尺度と呼ばれる周波数に基づいて、ログ変換を施すことで、特徴量(数値化したデータ)に変換されます。
変換されたデータは、Transformerモデルをベースにしたエンコーダーに送られそこからデコーダーがテキストに変換します。
Transformerは、attention層(モデルが学習を行う際に、入力されたデータのどの単語に注目するかを決めるための仕組み)を使ったエンコーダー・デコーダーの組み合わせで構成されており、音声からテキストへの変換だけでなく言語分類や音声検知など、複数のタスクを同時に処理することが可能です。
Transformerについては「Transformerとは?AI機械学習の仕組みを解説」で詳しく説明しています。
Whisperの使い方
Whisperを使用するための基本的なステップは以下になります。
- 環境設定
- 音声データの準備
- 文字起こしの実行
ここでは、これらの各ステップについて詳しく解説します。
Whisperの環境設定を行う
Google Colaboratoryを活用した、環境設定のやり方をご紹介します。
面倒な環境設定をしないで「試しに一度、触ってみたい!」という方は、オープンソースコミュニティ「Hugging Face」で簡単に利用することも可能です。

Google Colaboratoryを開いたら、「ノートブックを新規作成」を選択してください。
編集画面になったら、「編集」ボタンを選択してください。
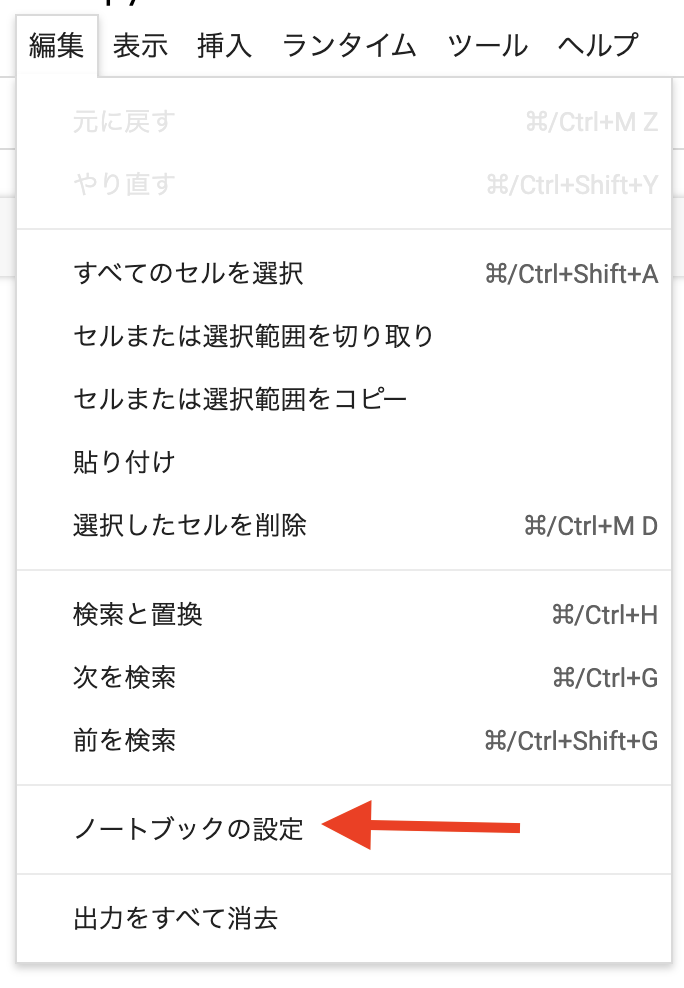
次に、メニュー欄の中から「ノートブックの設定」を選びます。
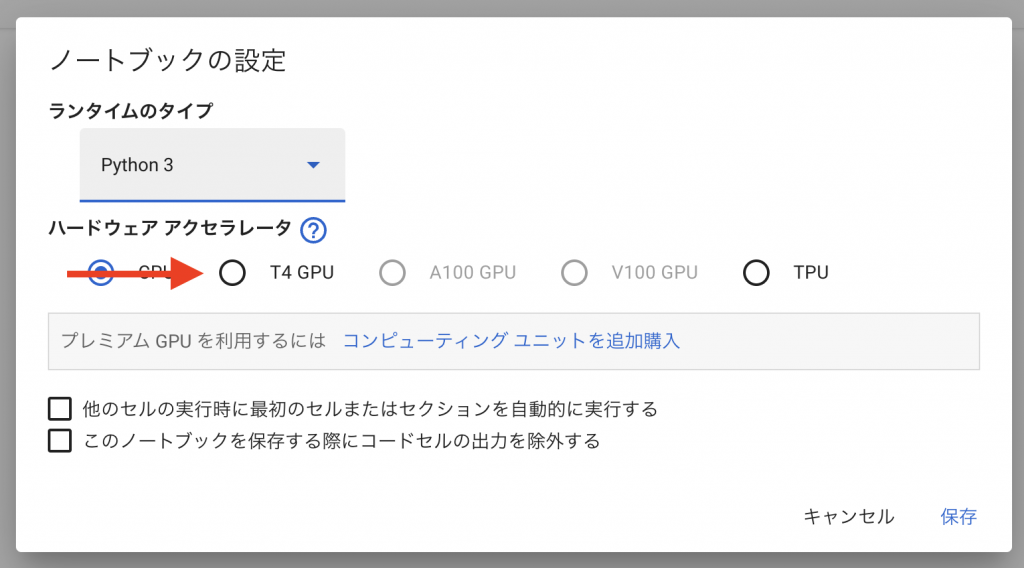
「ハードウェア アクセラレータ」を「T4 GPU」に設定して、右下の「保存」を押してください。
設定が完了したら、以下のインストールコードをコピペして貼り付けます。
※このコードはWhisperのオープンソースコードが記載されているGitHubのページでも確認できます。
|
1 2 |
pip install git+https://github.com/openai/whisper.git |
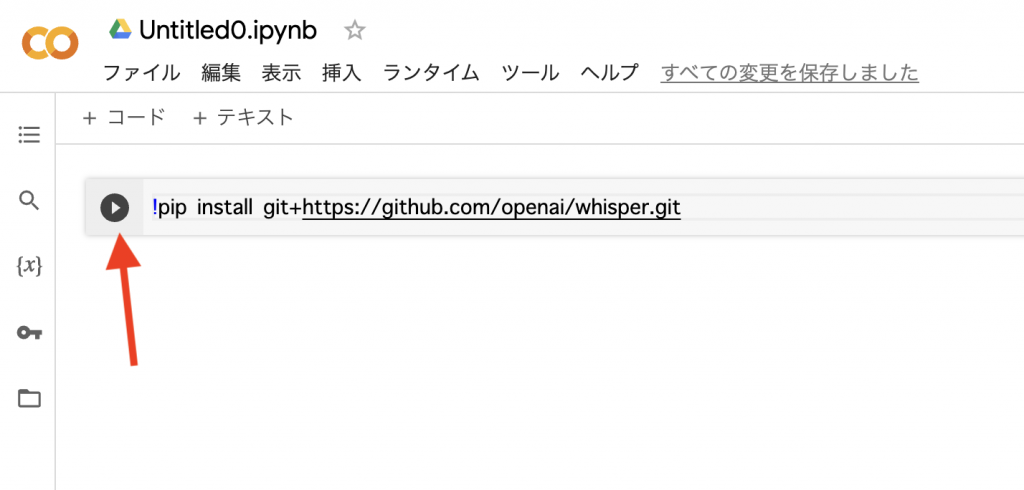
最初は、上図のコードを貼り付けて実行してください。
※「三角ボタン」が実行ボタンになります。
|
1 2 |
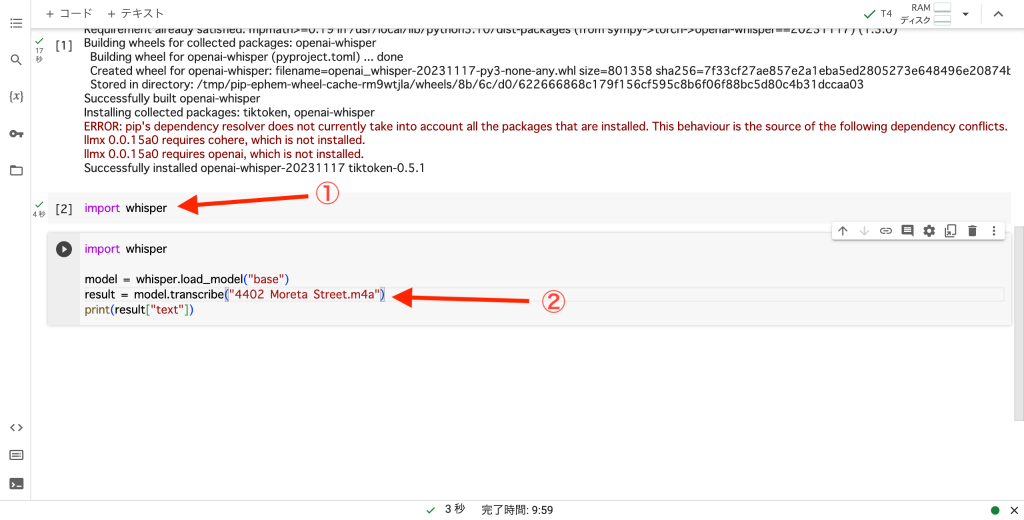
import whisper |
インストールが完了したら、最後に上記のコードを入力して同じように実行してください。
環境設定は以上です。
読み込ませる音声データを準備する
Whisperで文字起こしを行うためには、対応している音声データ形式のファイルを用意する必要があります。
Whisperは、mp3、mp4、mpeg、mpga、m4a、wav、webmといった一般的な音声ファイル形式に対応しています。
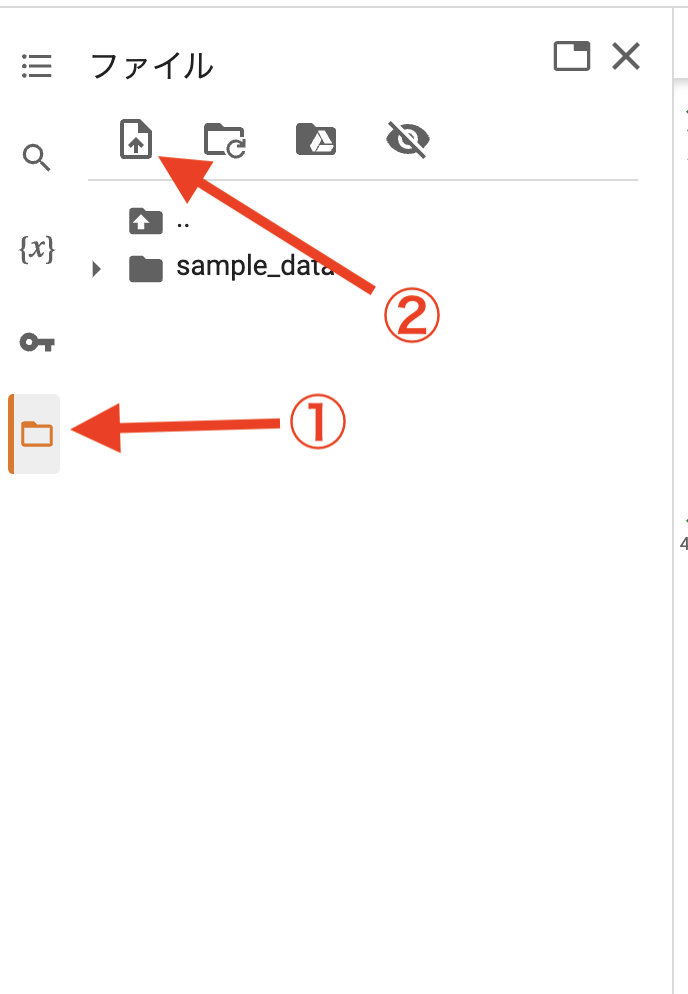
用意した音声ファイルをGoogle Colaboratoryに読み込ませる際には、左側にあるメニュー欄から①を選択します。
その後、②を選んで用意した音声ファイルをアップロードしてください。
文字起こしを実行する
音声データの準備が完了したら、実際にWhisperを使用して文字起こしを行います。
①まで終了していることを確かめた後、②のコードを入力します。
|
1 2 3 4 |
model = whisper.load_model("base") result = model.transcribe("4402 Moreta Street.m4a") print(result["text"]) |
この際、”4402 Moreta Streer.m4a”の場所には、ご自身で事前にアップロードした音声ファイルのファイル名を入力してください。
入力が完了したら、実行ボタンを選択します。
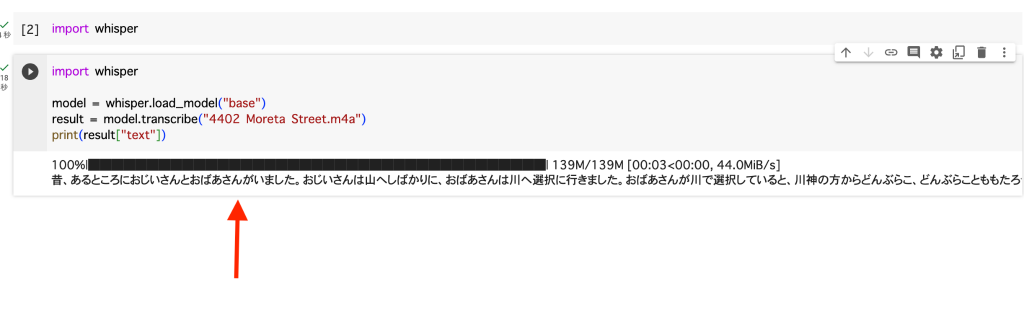
インポートが完了したら、文字が出力されます。
Whisper APIを活用するメリット
ここでは、Whisper APIを活用するメリットに関して解説します。
安価な価格で利用できる
Whisperは、音声データ1分あたりの料金が非常に低く、0.006ドル(日本円で約1円未満:23年11月時点)という驚くほど安価です。低コストで高品質な文字起こしサービスを利用できることは、多くのユーザーにとって大きなメリットといえるでしょう。
APIを直接使わなくても、既存のAIツールと組み合わせることでWhisperの機能を活用する方法もあります。そのため、技術的な知識が限られているユーザーでも、Whisperを利用して効率的に作業を進めることが可能です。
精度の高い音声認識が可能である
Whisperは多言語に対応しており、音声認識の精度は高いと評価されています。音声認識の高い精度により、さまざまな言語の音声データを正確にテキストに変換可能です。
また、日本企業を含む世界中の多くの企業や個人がWhisperを活用することで、コミュニケーションやデータ管理の効率を大幅に向上させることが期待されています。
今後、さらに多くの企業や個人がWhisperの利用を検討することで、音声データの活用方法が革新される可能性があります。
Whisper APIを活用するデメリット
Whisper APIの利用には、いくつかのデメリットがあります。
これらのデメリットを理解することは、Whisperの活用を検討する際に重要です。
実行環境を整える必要がある
Whisper APIを利用するためには、適切な実行環境の構築が必要です。料金は1分あたり0.006ドル(23年11月時点)と格安ですが、実行環境の構築が必要であり、簡単には利用できない点を考慮しておくべきでしょう。
また、Whisper APIの利用は有料であり、他の優秀な文字起こしサービスと比較して利用するかどうかを検討する必要があります。
機密情報の観点も留意しなければならない
Whisper APIを利用する際には、機密情報の保護にも注意が必要です。過去には、OpenAIのサービスであるChatGPTを使用していたサムスンのエンジニアが、社内機密のソースコードをアップロードしてしまい、情報が流出するという事件が発生しました。
Whisperに音声ファイルをアップロードする際には、機密情報保護の観点から問題があるとされています。Whisperに共有されたデータは削除ができず、精度を上げるための訓練に使用される可能性があるため、セキュリティ上の問題は解決すべき重要な課題です。
Whisperで始める、次世代の音声文字起こし革命
Whisperを使うことで、音声データからテキストへの変換が簡単かつ効率的に行えます。
Whisperは、音声の認識精度が高く、多言語に対応しているため、さまざまなシナリオでの利用が可能です。Whisperの基本的な使い方をマスターし、その高度な機能を最大限に活用するためには、ツールの特性を理解し、実践的なテクニックを学ぶことが大切です。Whisperを使いこなし、音声文字起こしの新たな時代を切り開いていきましょう。
Whisperの音声認識技術を深く学び、その可能性を最大限に引き出したい方には、以下の講座がおすすめです。
「音声」とAIで作文しよう!【Whisper+ChatGPT】 -AIによる音声認識とテキスト整形-

OpenAIが提供する「Whisper」と「ChatGPT」を使用し、音声データからテキストを自動で生成する方法を学びます。議事録、物語、ブログ記事、新規事業の企画書などの様々なタイプの文章を、音声データから手軽に作れるようになりましょう。
\無料でプレビューをチェック!/
講座を見てみるWhisperの仕組みを知り、OpenAIへの理解を深めましょう。
評価:★★★★★
openAIのサービスであるchatGPTとwhisperについて手を動かしながら身に着けることができた。ステップバイステップで大変わかりやすかった
評価:★★★★★
Whisperの精度や応用が分かりやすかった

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中