

AIや深層学習について勉強するためにHugging Face (ハギングフェイス) を活用したいけれど、
・Hugging Faceのインストール方法が分からない…。
・Hugging Faceをどのように活用したらいのか分からない… 。
と悩んでいる方も多いのではないでしょうか。そこでこの記事では、
・ Hugging Face のインストール方法
・ Hugging Face の有効的な活用方法
についてご紹介します。
公開日:2023年10月27日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >INDEX
Hugging Faceとは?
Hugging Faceは、人工知能(AI)の分野で急速に注目を集めているプラットフォームの一つです。
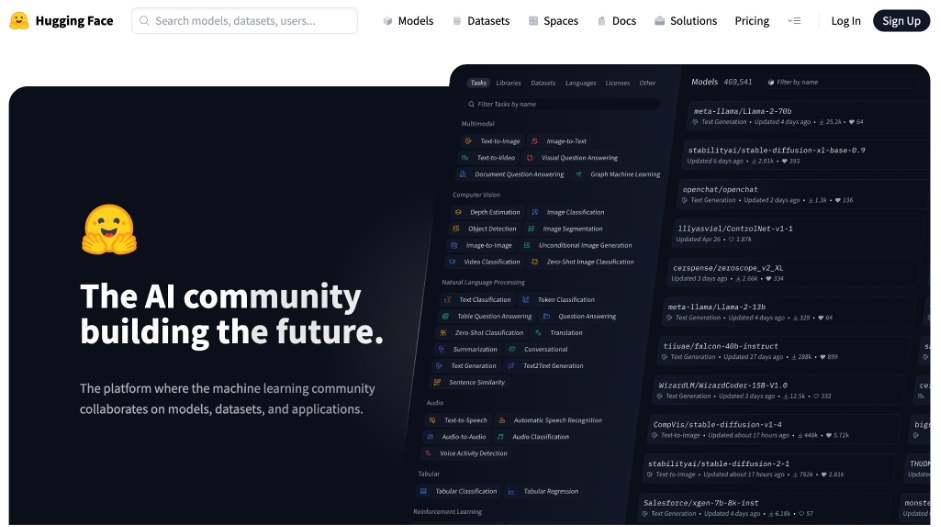
このプラットフォームは、AIモデルやデータセットを共有・利用することを主な目的としています。
具体的には、研究者や開発者が作成したAIモデルやデータセットを公開し、他のユーザーがそれらを利用して研究や開発を進めることができます。
Hugging Faceには、Transformersというライブラリが含まれており、これを使用することで、深層学習に関するデータを利用することが可能です。
また、Datasetsというライブラリも提供されており、これには大規模なデータセットが公開されています。ライブラリを活用することで、AIの研究や開発をより効率的に進めることが可能になります。
転移学習が容易にできる
転移学習は、深層学習の分野で非常に重要な技術の一つです。この技術は、事前に大量のデータを用いて学習したモデルを、新しいタスクに合わせて再学習させることを指します。
近年、深層学習のモデルは複雑化してきており、新しいタスクのためにモデルをゼロから学習させることは、時間や計算資源の観点から非常に難しくなってきました。また、転移学習を行う際には、学習済みのモデルを選択したり、そのモデルのパラメータを調整(チューニング)をしたりする必要がありました。
しかし、さまざまなモデルやデータセットが豊富に存在するHugging Faceを使用することで、このプロセスを大幅に短縮することが可能となりました。
転移学習の詳細は「 転移学習とは?ディープラーニングで期待の「転移学習」はどうやる? 」をご確認ください。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >Hugging Faceの代表的なライブラリを紹介
Hugging Faceは、自然言語処理の分野で非常に人気のあるライブラリを提供している企業です。その中でも、特に注目されているライブラリをいくつかご紹介します。
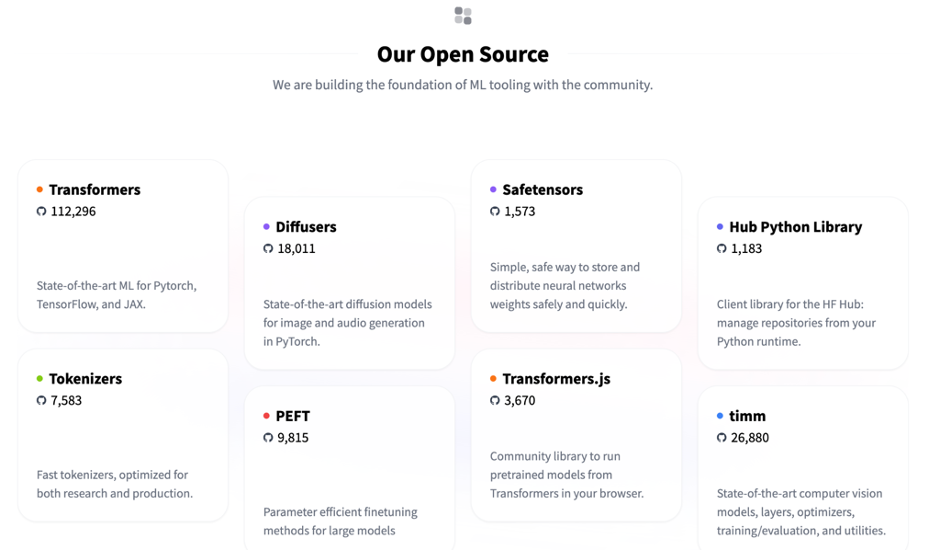
ここでご紹介しているライブラリは、自然言語処理の研究や実務での利用に役立ちます。
Transformers
Transformerは、2017年にGoogleが発表した深層学習モデルで、現在では自然言語処理の分野で最も利用されているモデルの一つです。このモデルは、大規模なテキストデータを効率的に処理する能力を持っており、多くの応用例が存在します。例えば、チャットボットであるChatGPTも、Transformerモデルをベースとしています。
Hugging FaceのTransformers ライブラリには、多数の学習済みモデルが提供されており、これをベースにして、新たなデータセットでの学習や、モデルのパラメータ調整などのタスクを行うことができます。
Transformerの詳細は「Transformerとは?AI機械学習の仕組みを解説」をご確認ください。
Datasets
機械学習の研究や実務を行う際は、大量のデータセットが必要となることが多々あります。Datasetsライブラリは、このようなニーズに応えるためのもので、多数のデータセットを提供しています。
また、データの変換やフィルタリングなど、前処理の機能も含まれており、データの取り扱いを効率的に行うことができます。
Tokenizers
自然言語処理において、テキストデータを処理するための最初のステップとして「トークン化」が行われます。トークンとは、文章における基本的な単位であり、一般的には個々の単語やフレーズを指します。
Tokenizersライブラリは、このトークン化のプロセスを補助するためのもので、さまざまなトークン化の手法が利用可能です。これにより、テキストデータの処理をより効率的に行うことができます。
Accelerate
機械学習の学習や推論を行う際、計算リソースとしてCPUやGPU、TPUなどが利用されます。Accelerateライブラリは、これらの異なる計算リソースを共通のコードで対応できるようにするためのものです。
従来、学習時の環境の違いによってコードが動かないという問題がありましたが、Accelerateを使用することで、このような問題を未然に防ぐことができます。
Hugging Transformersの使い方
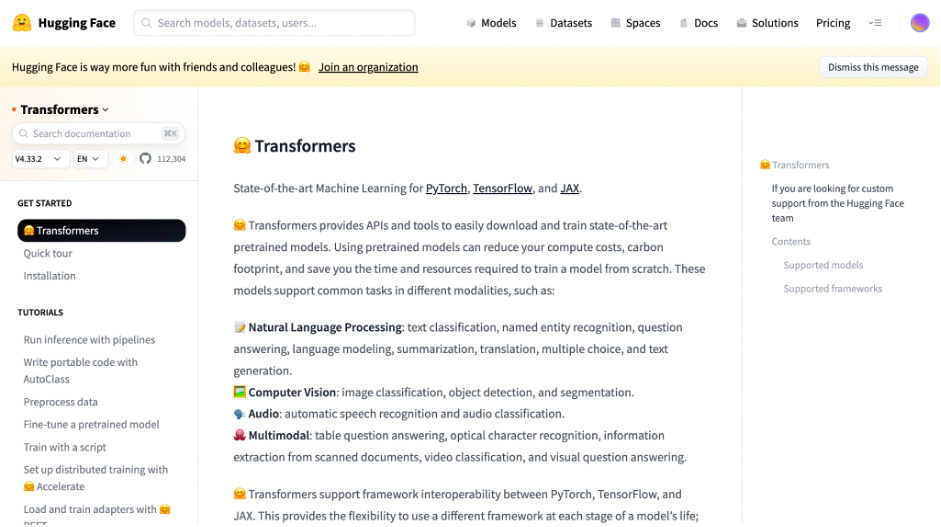
ここでは、Transformersの基本的な使い方をサンプルコードを交えて解説します。
インストール
Transformersのライブラリを使用する前に、まずは必要なライブラリをインストールする必要があります。以下のコマンドを使用して、Transformersと関連するライブラリを簡単にインストールできます。
|
1 |
!pip install transformers |
また、他の必要なライブラリやデータセットがある場合は、それに応じてインストールやインポートを行いましょう。
モデルの読み込み
Transformersライブラリを使用すると、多数の事前学習済みモデルを簡単に読み込むことができます。以下のコードは、DistilBERTという事前学習済みモデルを読み込む例です。
|
1 2 |
from transformers import AutoModelForSequenceClassification model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=4) |
このモデルは、BERTの軽量版として知られており、高い性能を持ちながらも計算コストが低いのが特徴です。読み込んだモデルは、訓練や評価を行った後、実際のデータでの予測に使用することができます。
BERTの詳細は「BERTとは何か?Googleが誇る最先端技術の仕組みを解説!」をご確認ください。
Hugging Face Datasetsの使い方
HuggingFaceのDatasetsライブラリは、自然言語処理に関する多数のデータセットを提供しており、これを利用することで、研究や開発を効率的に進めることができます。
ここでは、Datasetsの基本的な使い方や操作方法をサンプルコードを交えて解説します。
インストール・データセットの読み込み
Hugging FaceのDatasetsライブラリを使用する前に、必要なライブラリをインストールする必要があります。
|
1 |
!pip install transformers datasets |
上記のコマンドで、transformersとdatasetsの両方をインストールできます。データセットは、Hugging Faceの公式サイトから検索することができ、load_dataset関数を使用して簡単に読み込むことができます。
データセットの操作
Datasetsライブラリを使用すると、読み込んだデータセットの内容を簡単に確認したり、操作したりすることができます。
特に、データセットの構造やラベルの確認は、学習や評価を行う前の重要なステップとなります。また、pandasなどのライブラリとの連携もスムーズで、データの可視化や前処理を効率的に行うことが可能です。
例えば、emotionsというデータセットを読み込んだ場合、以下のようにして内容を確認することができます。
|
1 2 3 4 |
from datasets import load_dataset emotions = load_dataset("emotion") print(emotions) |
このように、Datasetsライブラリを使用することで、自然言語処理の研究や開発を効率的に進めることができます。
深層学習に有用なHugging Faceを使いこなそう
Hugging Faceは、深層学習の研究や実務において非常に有用なツールとして注目を浴びています。
特に、自然言語処理の分野での活用が進んでおり、多くのプロジェクトや研究でその力を発揮しています。ライブラリの豊富さや移転学習の容易さなどの特徴を活かすことで、深層学習のプロジェクトをよりスムーズに進めることができるでしょう。
Hugging Faceの実践に興味がある方には、下記の講座がおすすめです。
GPTを自作して大規模言語モデルを理解する:PythonでTransformerとAttentionを学ぶLLM機械学習

GPT1の部品を作りながらPyTorchでGPT本体を自作します。LLMがどのように作用しているのか本体を自作してコードレベルで見ていきます。レクチャーの内容に応じてニューラルネットワークについても触れていきます。
\無料でプレビューをチェック!/
講座を見てみるレビューの一部をご紹介
評価:★★★★☆
図解による直感的な理解に終始せず、
プログラミングを進めることで理解が深まったと思う。
HuggingFaceを使いこなして、深層学習の知識を効率的に取得しましょう!

 RANKING
RANKING



 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中