

生成AIを業務活用したいシステム担当者には、Amazon Bedrockの利用がおすすめですが、
・Amazon Bedrockの特徴や導入メリットがよく分からない…。
・SageMakerとの違いや、どの基盤モデルが自社に合うのか迷っている…。
と悩まれている方も多いのではないでしょうか。そこでこの記事では、
・Amazon Bedrockの概要と特徴
・利用できる生成AIモデルの紹介
・SageMakerとの違い
・料金体系
・実際の使い方、導入時の注意点
についてわかりやすく解説します。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >INDEX
Amazon Bedrockとは
Amazon Bedrock(アマゾン ベッドロック)は、AWSが展開するインフラ管理不要な生成AI基盤です。Amazonだけでなく、サードパーティ製の生成AIモデルも利用できます。インフラ管理やモデルのホスティングはAWS側で担うため、AIの導入工数を大幅に削減でき、利用者はAI活用に集中できます。
また、一部の機能はノーコードのGUI操作にも対応しており、専門知識がなくても直感的に生成AIを活用することが可能です。Amazon Bedrockを活用することで、ビジネス現場におけるAI活用が容易になり、業務効率化や新規サービスの迅速な立ち上げが実現できます。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >Amazon Bedrockの特徴
主要な特徴としては次のようなものが挙げられます。
業務効率化やAI導入を検討する方にとっては、見逃せない特徴ばかりです。これらの特徴について詳しく見ていきましょう。
用途に応じて幅広い基盤モデルを選択できる
Amazon Nova、Amazon Titan、Claude、Llamaなど、業務内容にあわせて適切なAIモデルを選ぶことが可能です。各モデルは多言語対応、大規模データ処理など、それぞれ強みが異なるため、業務内容や要件に合わせたモデル選定が可能です。また、単一のサービス上で複数のモデルを比較・検証できる柔軟性も大きな魅力です。
Cursorの詳細については、「▶Claude 3とは?特徴や活用方法、ChatGPTとの違いを解説!」の記事をご覧ください。
AWSサービス間の連携がスムーズにできる
Amazon S3やLambda、API GatewayなどのAWSサービスと簡単に統合でき、Step Functionsを活用したAIワークフローの自動化も実現できます。さらに、AWS IAMによる認証情報やアクセス権限の統合管理が可能で、実行環境やワークフロー全体のセキュリティと運用効率を高められます。
Lambdaの詳細については、「▶AWS Lambdaとは?対応言語やメリット・デメリットを徹底解説!」の記事をご覧ください。
独自要件に合わせて基盤モデルを調整できる
自社データを活用して、検索を使って答えを生成するRAG(Retrieval-Augmented Generation:検索拡張生成)構成や独自応答の実装も可能です。また、特別な学習作業(ファインチューニング)を行わなくても、プロンプト(AIへの指示文)を工夫することで、AIの回答精度を上げることができます。さらにデータをAIが理解しやすい形(埋め込みベクトル)に変えて、知識を効率的に整理したり使ったりすることも可能です。
RAGの詳細については、「▶RAGとは?LLMの欠点を補う仕組みとメリット・活用方法を解説」の記事をご覧ください。
安全性の高い環境で利用できる
データの暗号化(KMS連携対応)や応答ログの非保存、ユーザーデータの学習不使用など、高いセキュリティ基準を満たしています。IAMやVPC設定による厳密なアクセス制御も可能で、法人利用で求められるセキュリティ基準にも適合しています。
Amazon BedrockとSageMakerの違い
Amazon BedrockとSageMakerは、どちらもAWSが提供するAIサービスです。大まかに分けると、Bedrockは生成AI専用のサービスであり、SageMakerは機械学習全般をカバーするサービスという違いがあります。
また、BedrockはAPIベースで基盤モデルを即座に活用でき、インスタンスやインフラの管理が不要という特徴があります。一方、SageMakerではインスタンス管理が必要ですが、ノートブックやSDKを使った柔軟な操作や、カスタムモデルの構築・トレーニングが可能である点が特徴です。
| 項目 | Amazon Bedrock | Amazon SageMaker |
|---|---|---|
| 主な用途 | 既存のAIモデルを活用したアプリ開発 | 既存データを基にした独自のAIモデル開発 |
| できること | 文章生成や質問回答をするAIの簡易な制作 | 独自AIの開発・データ分析 |
| 必要な知識 | 特別な知識は不要 | AIやデータ分析、プログラミングの知識 |
| カスタマイズ | 簡単な調節はできるが、細かい変更は難しい | 自分のデータで完全にカスタマイズできる |
| 対象ユーザー | AIを手軽に使いたい方向け | AIを研究し、作り込みたい方向け |
| インフラ管理 | AWSがほとんどの仕組みを管理してくれる | 自分でAIを動かす仕組みを作り、管理する必要がある |
| 使えるAIモデル | 既存のAIモデルを選んで使える(例:文章生成AI) | 自分でAIモデルを作って使える(例:画像認識AI) |
【AWS】Amazon Bedrockによる生成AIウェブアプリ構築(AIエージェント編)

Amazon BedrockのGenUでAIエージェントの基本を学ぼう
\無料でプレビューをチェック!/
講座を見てみるAmazon Bedrockで利用できる7つの主要基盤モデル
さまざまな用途や業務要件に応じて選べる基盤モデルが提供されており、主要なモデルは次の通りです。
- Amazon Nova:利用目的に応じてモデルを選択
- AI21 Labs(Jamba):多言語に対応
- Anthropic(Claude):大量のデータ処理に特化
- Cohere(Command,Embed)ビジネス文書作成に特化
- Meta(Llama):自然言語の理解とテキスト生成に特化
- Mistral AI(Mistral):コード生成・ドキュメントの作成に特化
- Stability AI(Stable Diffusion):画像生成に特化
注意点として、ここで挙げた基盤モデルはすべてのリージョンで利用できるわけではありません。(2025年6月時点)
利用したいモデルが見つからない場合の対処法は後述の「▼利用したいモデルが見つからない場合の対処法」で解説しているため、ここでは各モデルの特徴について見ていきましょう。
Amazon Nova:利用目的に応じてモデルを選択
Amazon Novaは、Micro、Lite、Pro、Premier、Canvas、Reelなど用途ごとのモデルが提供されており、テキスト・画像・動画生成に対応しています。生成コンテンツだけでなく、精度や速度、コストに応じて利用したいAIモデルを指定できます。また、200以上の言語に対応(Micro/Lite/Pro/Premier)し、競合モデルと比較して最大75%低コストで利用できる点も特徴です。
AI21 Labs(Jamba):多言語に対応
Jambaは英語、スペイン語、フランス語、ドイツ語など多言語に対応し、長文生成や要約、翻訳タスクに強みを持っています。大規模なデータセットでトレーニングされており、高精度な出力が可能です。
Anthropic(Claude):大量のデータ処理に特化
Claudeは20万トークンまでの入力に対応し、長文処理や大量データの要約・抽出に適しています。高度な推論能力と人間らしい理解力を持ち、2025年5月にはClaude 4シリーズ(Opus 4/Sonnet 4)が発表され、さらに性能が向上しています。
Cohere(Command,Embed):ビジネス文書作成に特化
Cohereは業務文書やレポート、メールなどビジネス向けの文章生成に強みがあります。プライバシーやセキュリティを重視した設計で、API経由で簡単に統合できる点も魅力です。
Meta(Llama):自然言語の理解とテキスト生成に特化
MetaのLlamaは、議事録作成やFAQ生成、会話型AIなど自然言語理解とテキスト生成に強みを持ちます。高い理解力と生成能力を備え、無償で広く公開されているため、商用・研究利用を含め多様な用途で活用されています。
Mistral AI(Mistral):コード生成・ドキュメントの作成に特化
Mistralはプログラムコードの生成や最適化、技術文書やマニュアルの作成など、開発業務に役立つタスクで高い性能を発揮するモデルです。自然言語とコードの両方のタスク理解に優れており、業務効率化や自動化に幅広く活用されています。
Stability AI(Stable Diffusion):画像生成に特化
Stable Diffusionはテキストから高品質な画像を生成でき、広告制作やゲームキャラクター制作など幅広い用途に活用されています。複雑な構図にも対応可能で、クリエイティブ業務の効率化に貢献します。
Stable Diffusionの詳細については、「▶Stable Diffusionで画像から画像を生成する方法を解説!」「▶Stable Diffusionを使って動画からAI動画を作成する方法を解説!」の記事をご覧ください。
Amazon Bedrockの料金体系
Amazon Bedrockの料金は、主に「従量課金型」と「サブスクリプション型(プロビジョンドスループット)」の2種類があります。利用シーンに応じて使い分けが重要です。
| 料金プラン | 課金方式 | 特徴 | 適した利用シーン |
|---|---|---|---|
| オンデマンド(従量課金) | トークン数や画像生成数に基づく従量課金 | 利用分のみ支払い、初期投資不要 | 利用料が少ない場合や検証フェーズ |
| プロビジョンドスループット(サブスクリプション) | 時間単位の契約料金(1か月/6か月) | 期間コミットで割引適用、スループット保証 | 継続的かつ安定した利用が必要な場合 |
この2つの料金プランについて、もう少し掘り下げて解説します。
オンデマンドプラン(従量課金):初期導入向け
オンデマンドプランでは、使用したトークン数や生成画像数に応じて課金されるため、初期コストが不要です。需要に応じてスケールアップ・ダウンが可能で、利用量が少ない検証段階や予測不能な需要変動がある場合に柔軟に対応できます。
また、大量のデータを一括処理したい場合は「バッチモード」の利用が推奨されます。複数のプロンプトを一括で処理でき、オンデマンド比50%低コストで実行可能です。
プロビジョンドスループットプラン(サブスクリプション):継続利用者向け
プロビジョンドスループットプランは、継続的な利用でコスト効率を最大化できます。用途に応じて最適なモデルを選択する必要があり、モデルごとに性能やコストが異なります。
事前にオンデマンドで評価・比較を行い、推論負荷や応答速度を検証することがおすすめです。継続性を重視する場合、長期間のコミットメントで単価を抑えつつ、安定したパフォーマンスを確保できます。
Amazon Bedrockの使い方
基本的な使い方について、実際の画面キャプチャを用いて解説します。
使用したいモデルを有効化する方法
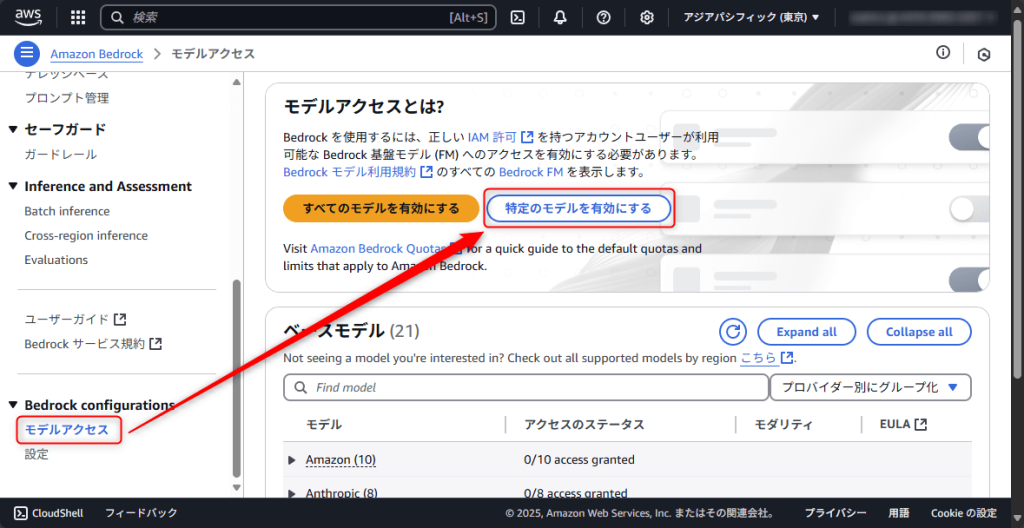
利用する際は、はじめに使用したいモデルを有効化する必要があります。
Amazon Bedrockのコンソール画面から「モデルアクセス」を選択し、「特定のモデルを有効にする」を選択します。
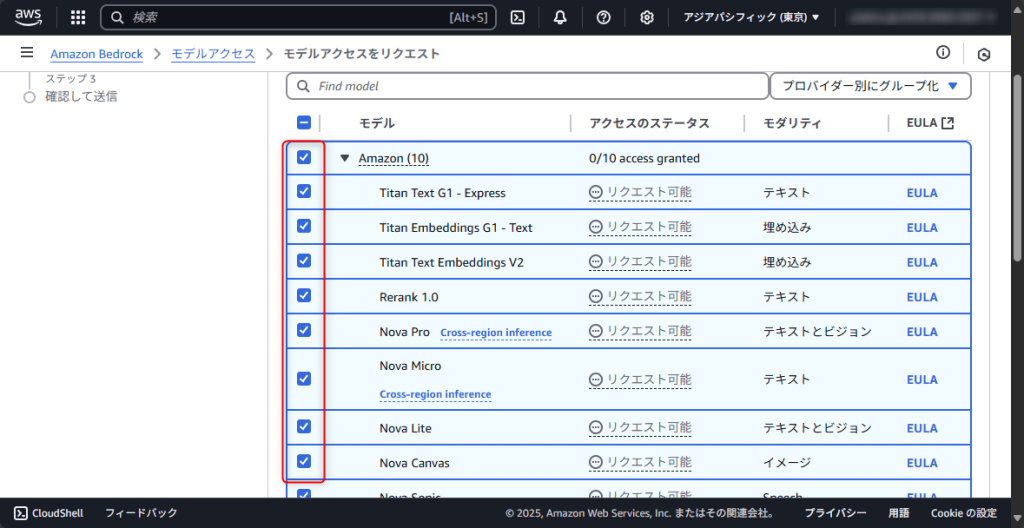
利用したいモデルにチェックを入れ、画面下部の「次へ」ボタンをクリックします。ここでは、Amazonのすべてのモデルを選択しました。
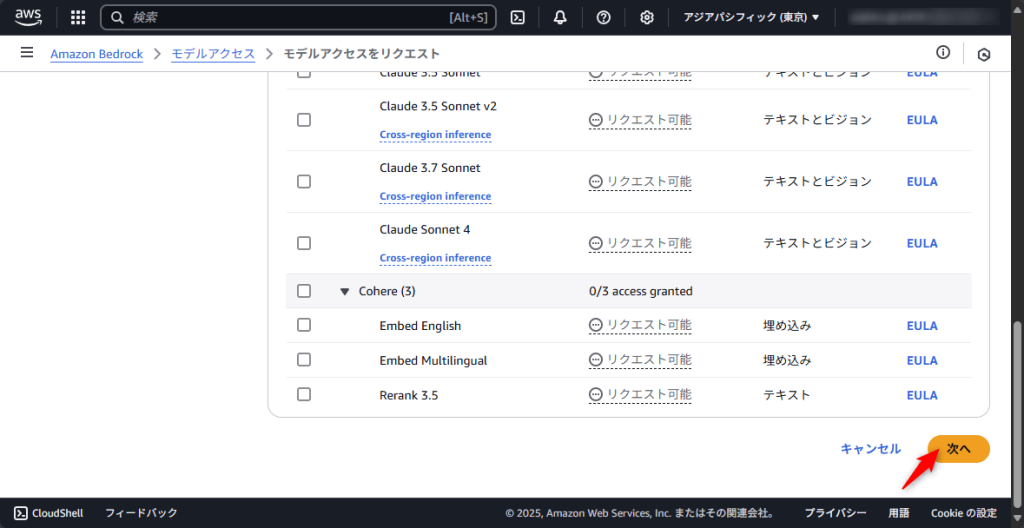
モデルアクセスリクエストの確認画面が表示されたら、「送信」ボタンをクリックしてください。
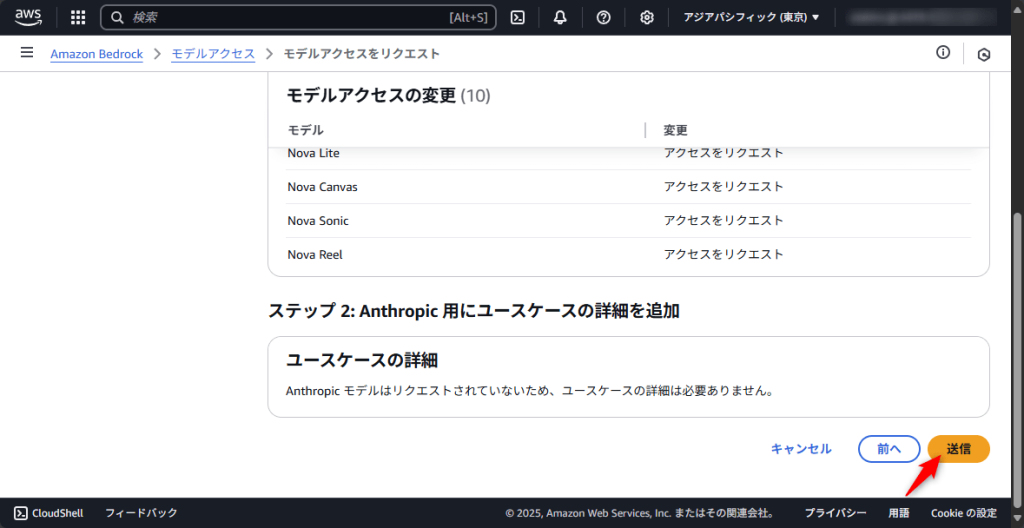
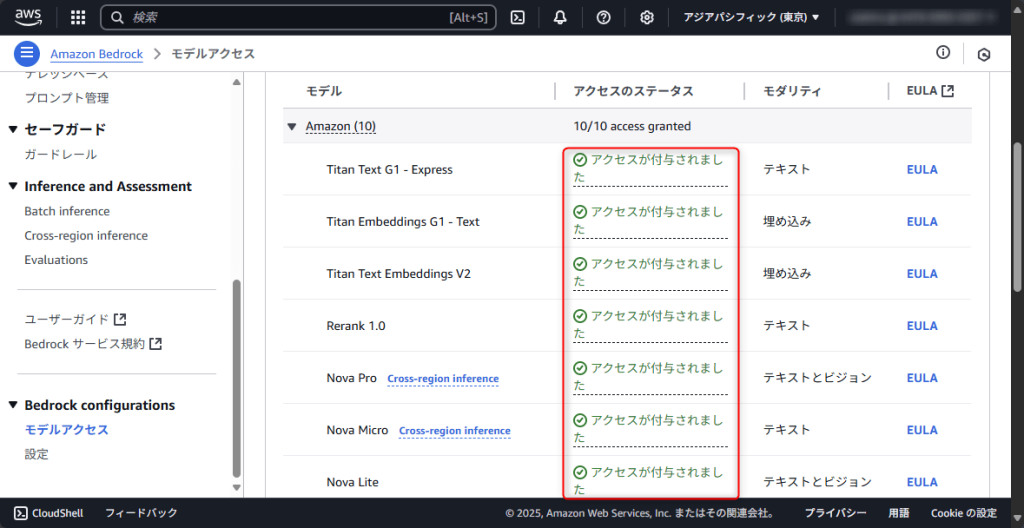
アクセスのステータスが「アクセスが付与されました」と表示されれば完了です。
利用したいモデルが見つからない場合の対処法
モデルが見つからないときは、リージョン設定を確認しましょう。Amazon Bedrockでは、モデルによって提供リージョンが異なるためです。
例えば、次のように東京、バージニア北部、オレゴンでそれぞれリクエストを送信可能なベースモデルには違いがあります。
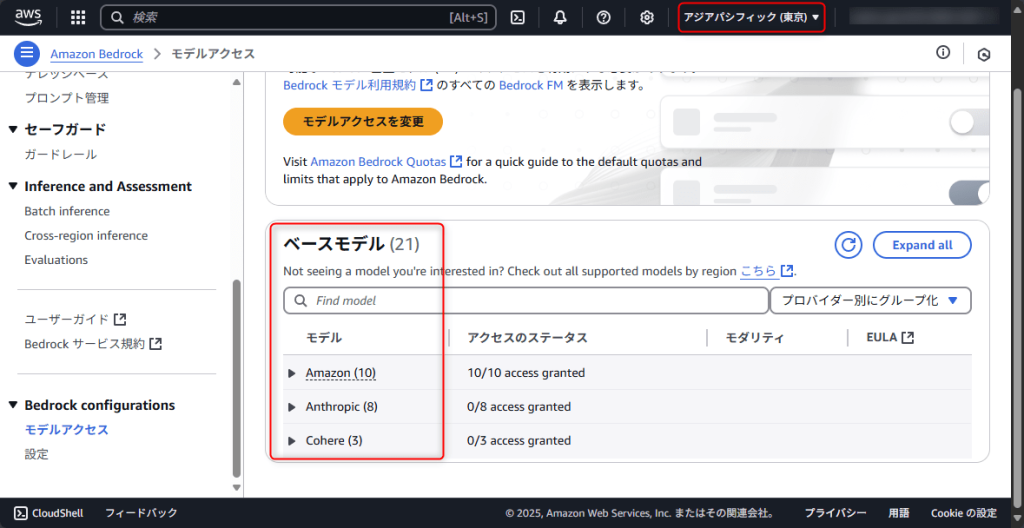
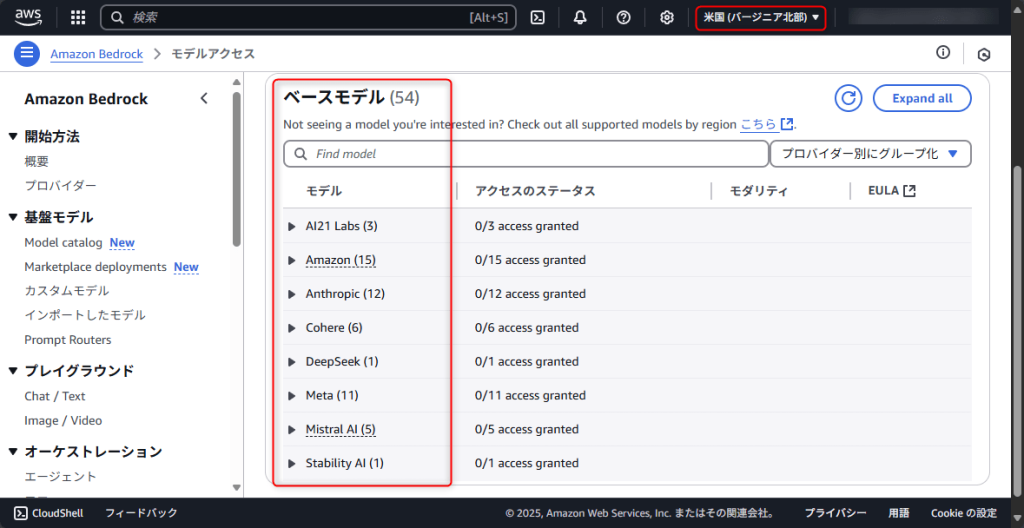
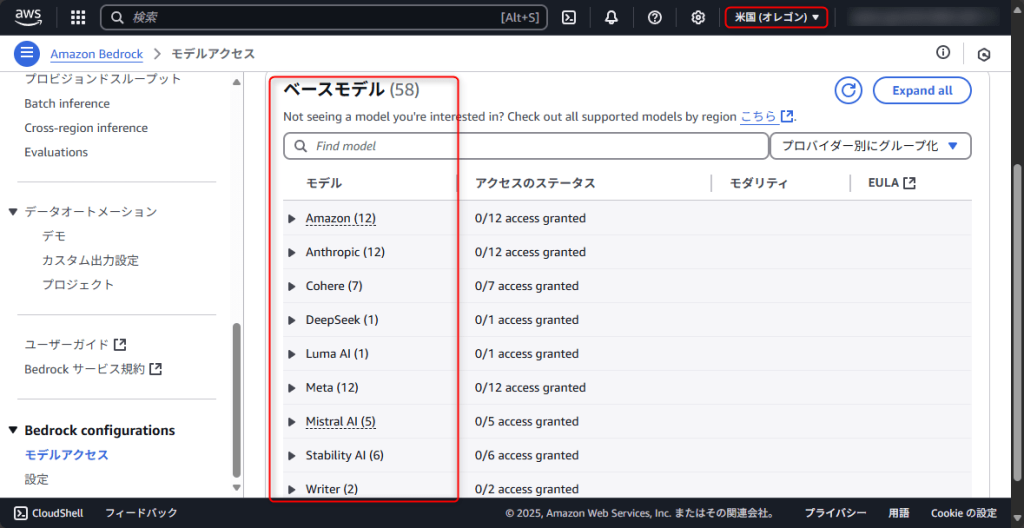
これは2025年6月時点の情報であり、将来的にはリージョンに関係なくさまざまなモデルを利用できるようになると思いますが、モデルが見つからなかった場合には試してみてください。
実際の使用方法
Webコンソールの「プレイグラウンド」から簡単に使用できます。今回は「Chat/Text」を選択して進めてみましょう。
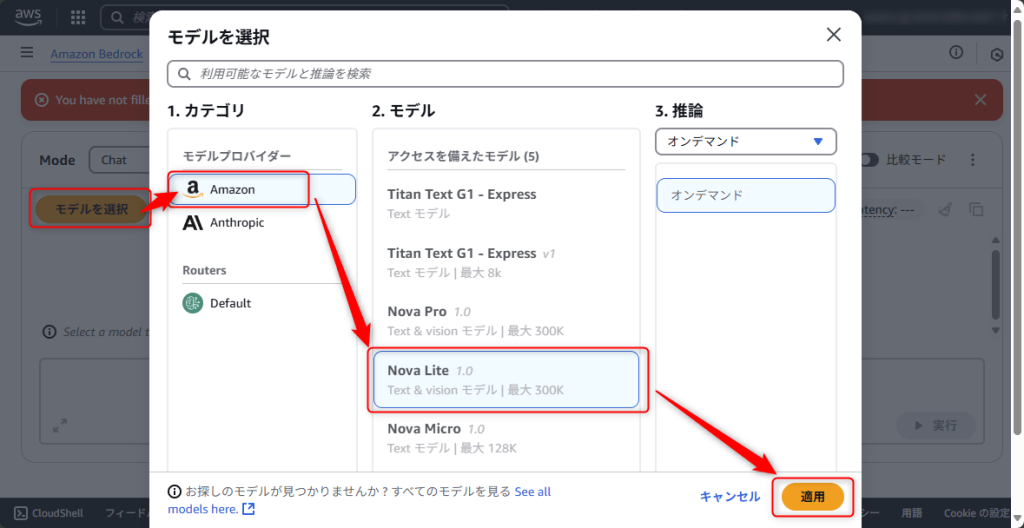
「モデルを選択」からモデルプロバイダー、モデルを選択して「適用」ボタンをクリックします。
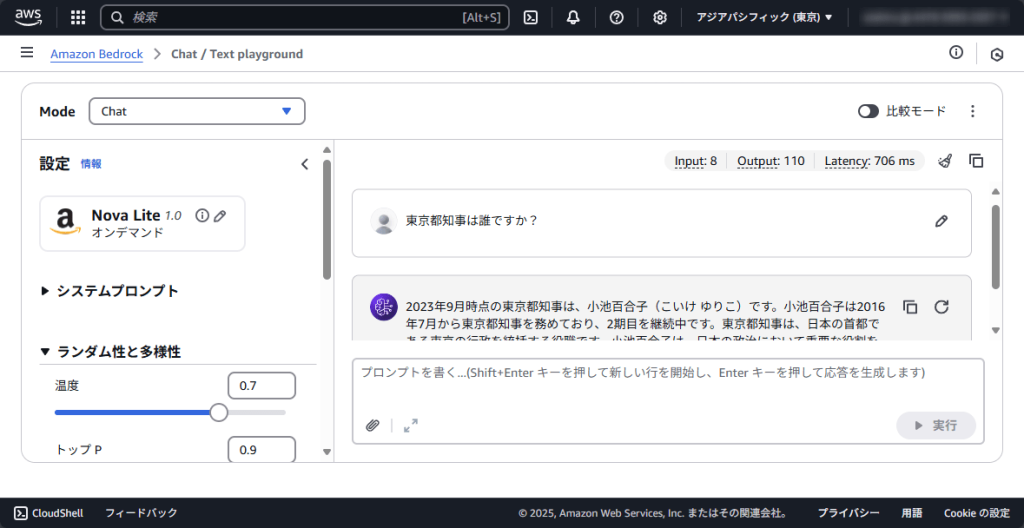
「東京都知事は誰ですか?」の問いに対して「2023年9月時点の東京都知事は、小池百合子です」と返ってきました。非常に手軽に操作可能です。
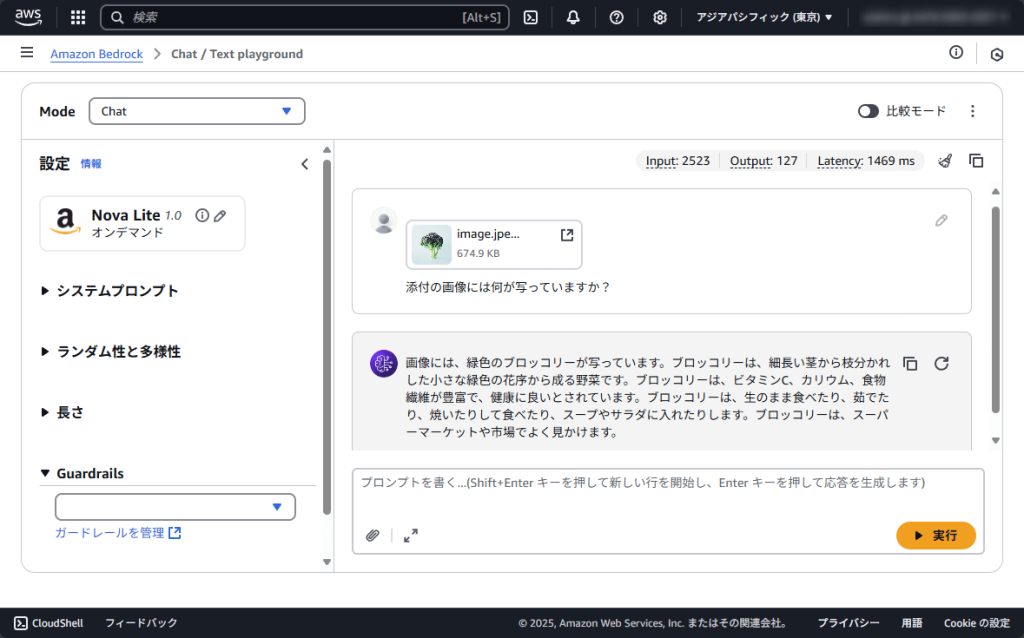
また、Nova Liteはマルチモーダルモデルであるため、画像をアップロードして質問してみました。
しっかりと画像がブロッコリーであることを認識し、回答してくれています。
イメージの生成方法
テキストだけでなく画像の生成も可能です。今回はStable Diffusionを使ってみましょう。Stable Diffusionはオレゴンリージョンで提供されており、事前にモデルアクセスをリクエストしておきました。
リージョンをオレゴンに変更し、プレイグラウンドから「Image/Video」を選択します。
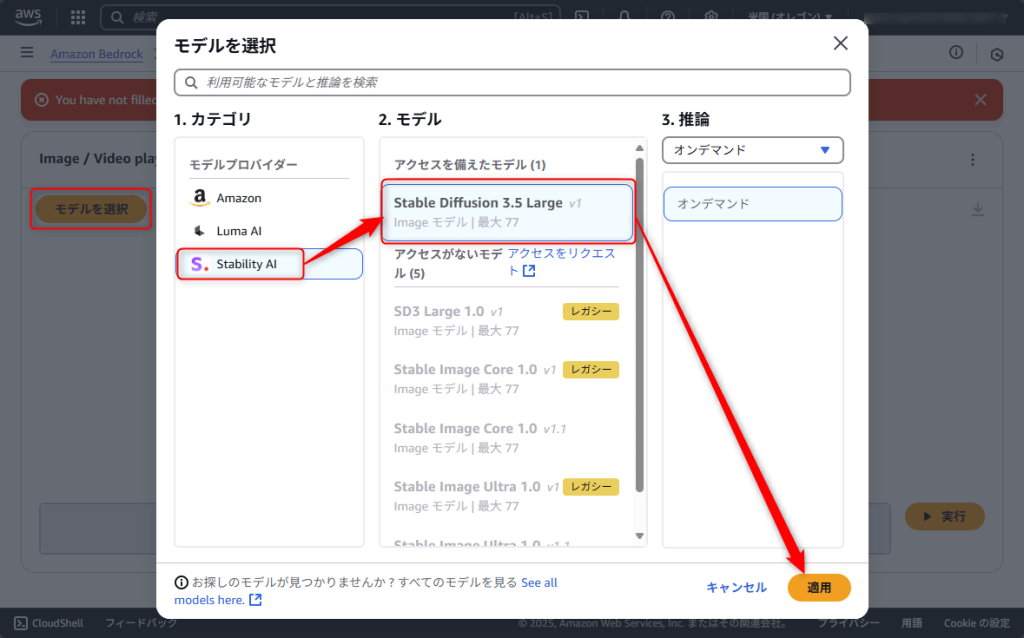
「モデルを選択」からモデルプロバイダー、モデルを選択して「適用」ボタンをクリックします。
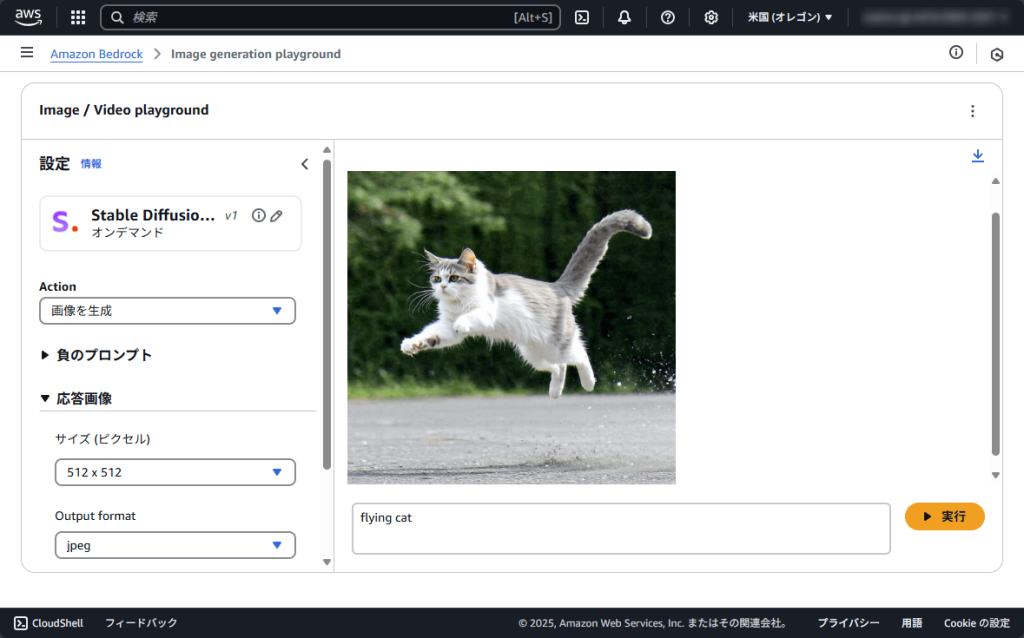
Stable Diffusionでは英語でのプロンプトが適しています。今回は「flying cat」と入力し、数秒で飛んでいる猫の画像が生成されました。
また、画像を選択して「バリエーションを生成」から異なる画像を生成してみましょう。
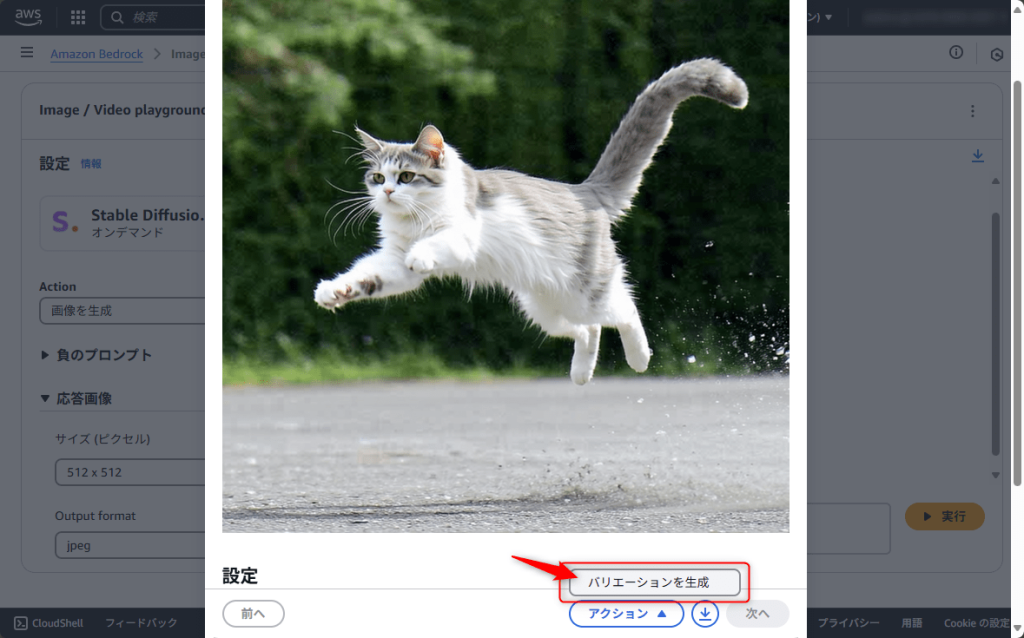
プロンプトに追加で「sleeping cat」を追加しました。
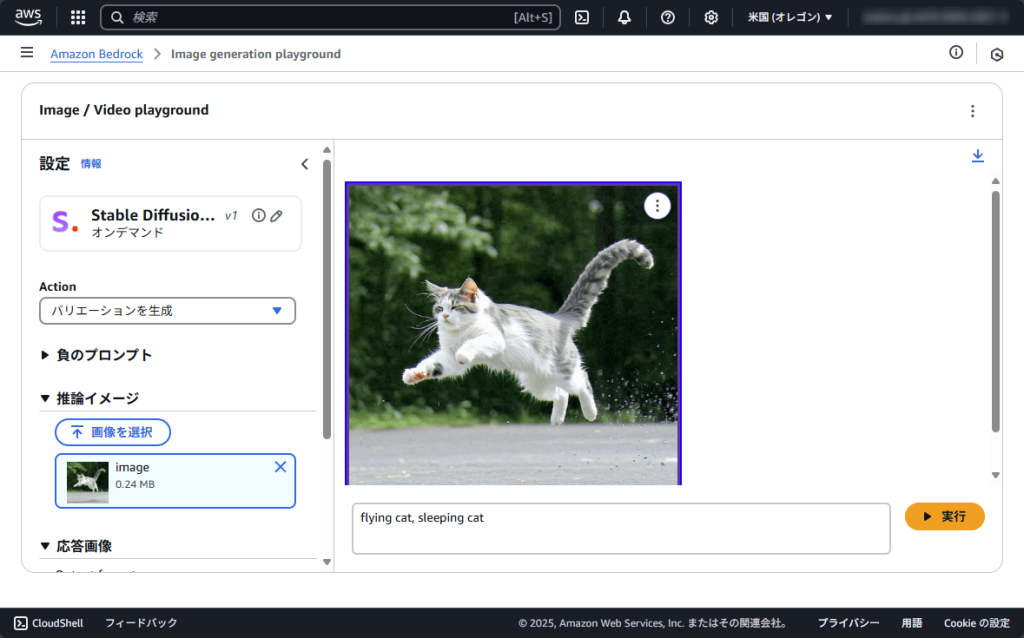
先ほど生成した画像のバリエーションとして、寝ながら飛ぶ猫の画像が生成されました。

このように、画像の生成もテキストの生成同様に簡単に実行できます。
ナレッジベースの作成方法
ナレッジベースを準備し、生成AIのデータソースとして活用する方法を簡単に紹介します。ここでは次の流れで進めていきます。
- S3バケットにデータを保存する
- S3バケットをナレッジベースのデータソースとする
- 生成AIにナレッジベースを参照させる
ナレッジベースで利用できるファイルの形式は、テキストやエクセル、CSV、PDFなどです。
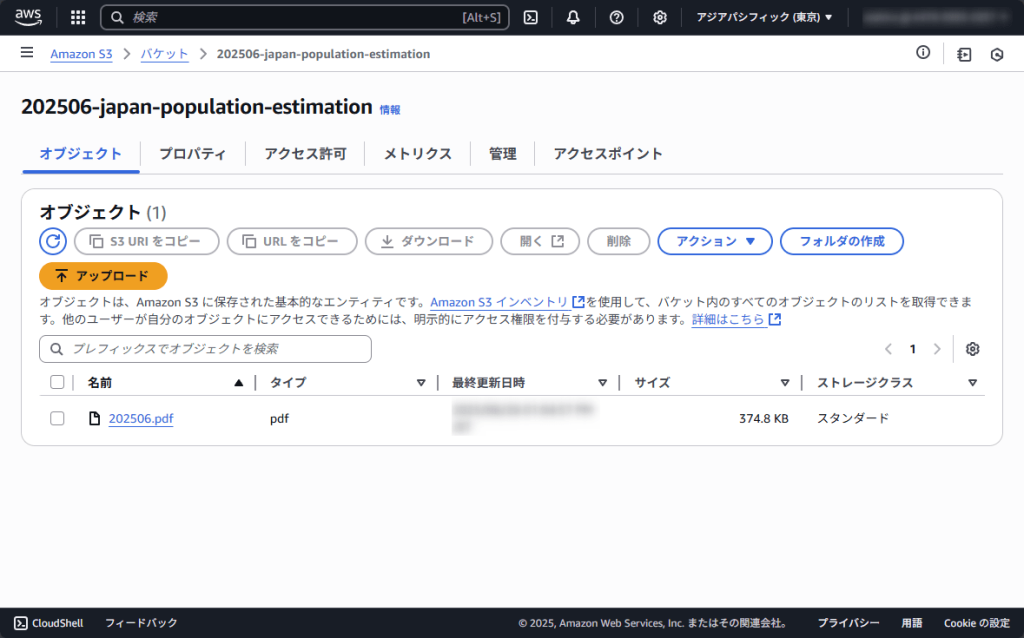
今回使用するデータは、総務省統計局が公表している「人口推計(2025年(令和7年)1月確定値、2025年(令和7年)6月概算値)(2025年6月20日公表)」のPDFファイルを利用します。
まずは、PDFをダウンロードして新規作成したS3バケットに保存します。
Amazon Bedrockに戻り「オーケストレーション」の「ナレッジベース」から「作成」→「ベクトルストアを含むナレッジベース」を選択します。
ナレッジベースの名前や説明などを適宜入力してください。
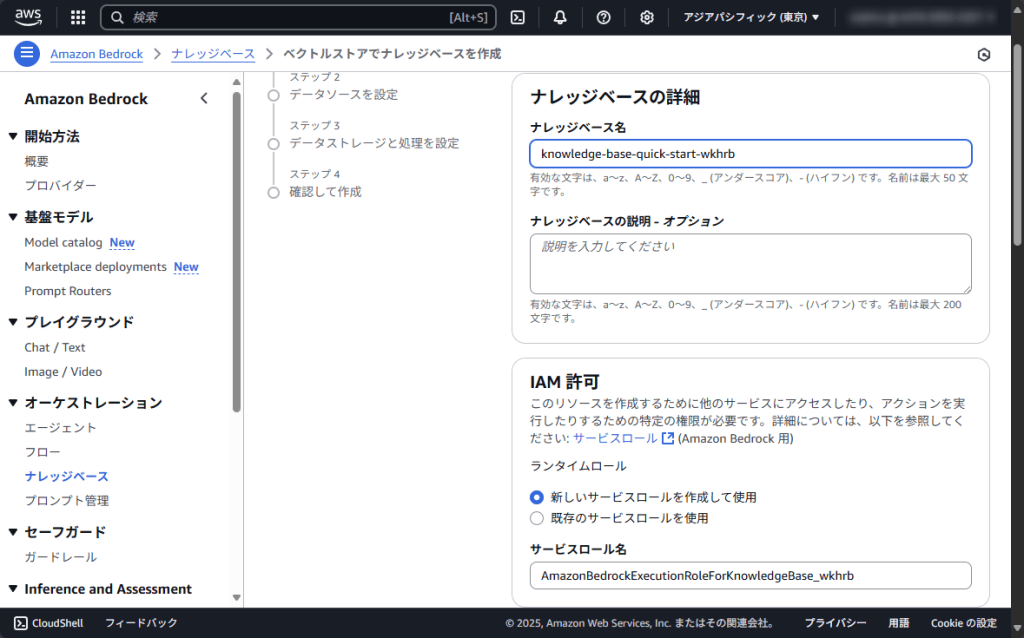
今回はS3バケットを使用するため、Amazon S3が選択されていることを確認します。
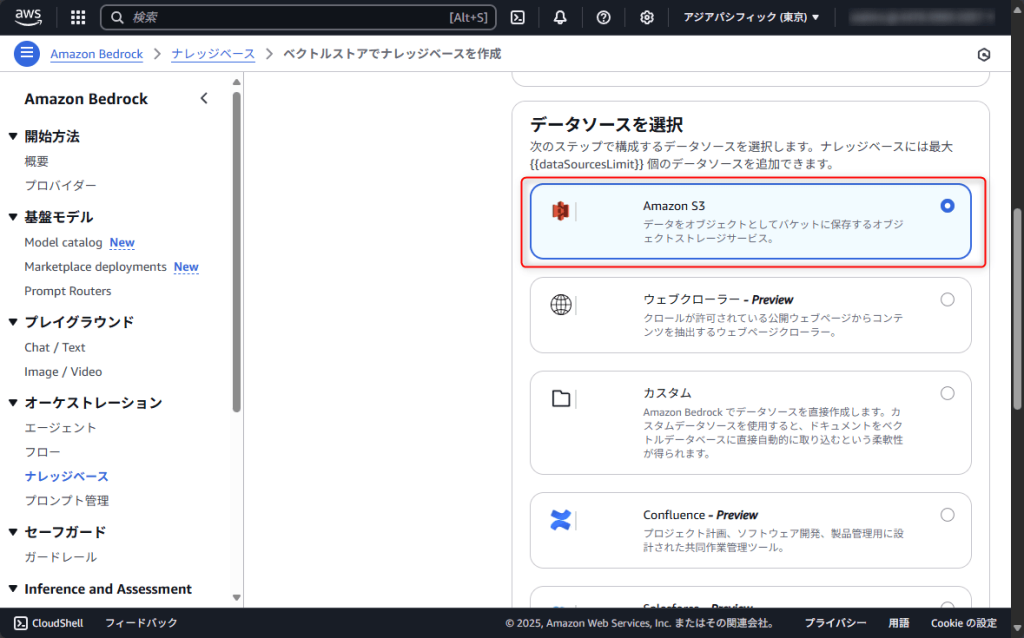
その他はデフォルトのままで進めることとし「次へ」ボタンをクリックします。
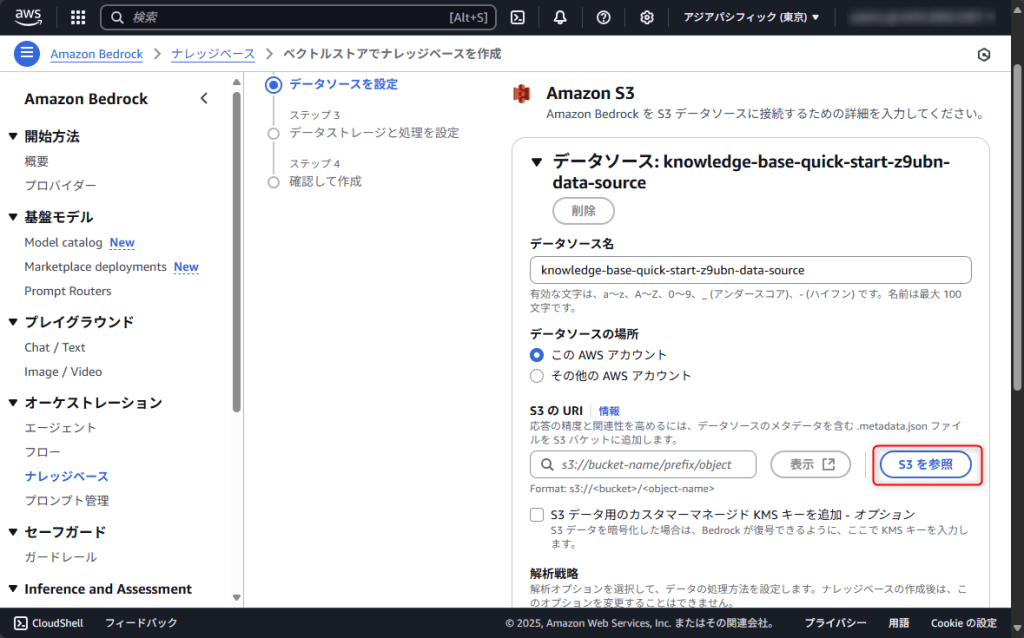
新規作成したS3バケットを選択するため「S3を参照」ボタンをクリックしてください。
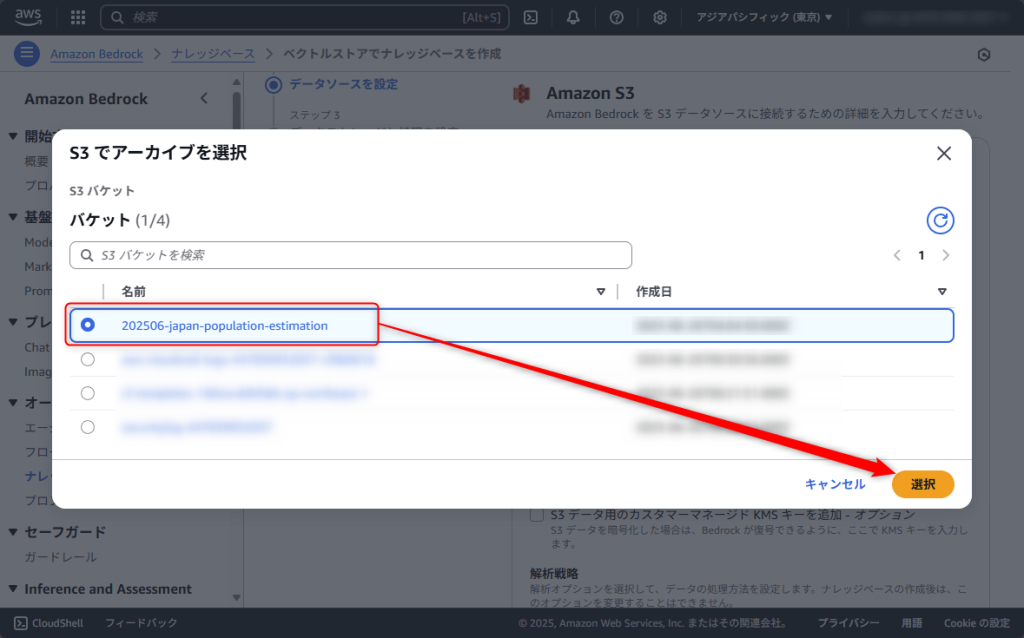
先ほど作成したS3バケットをチェックして「選択」ボタンをクリックします。
その他はデフォルトのままで「次へ」ボタンをクリックします。
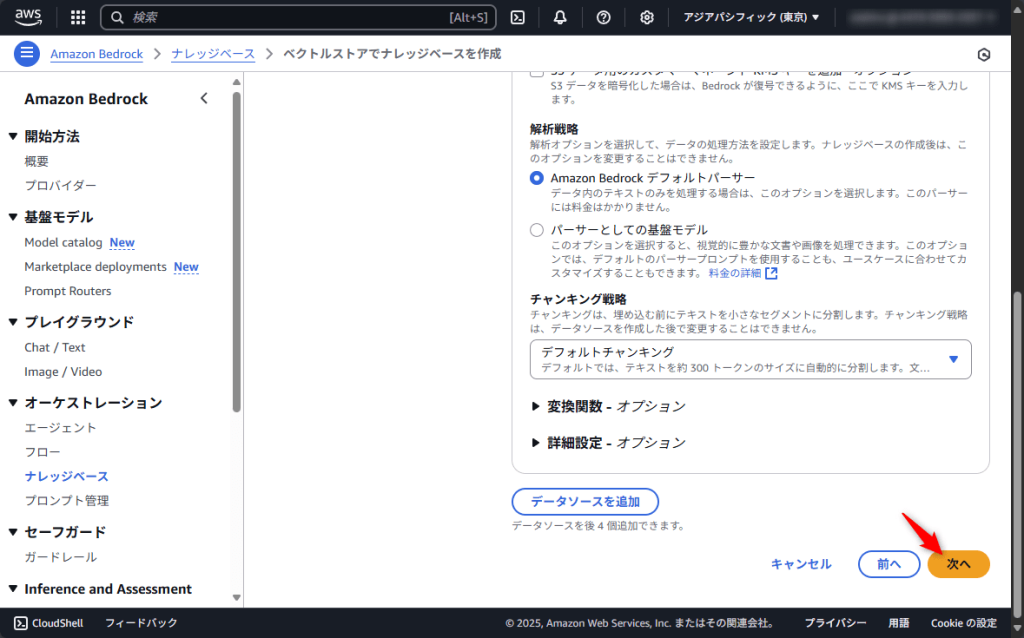
埋め込みモデルを選択するために「モデルを選択」をクリックしてください。
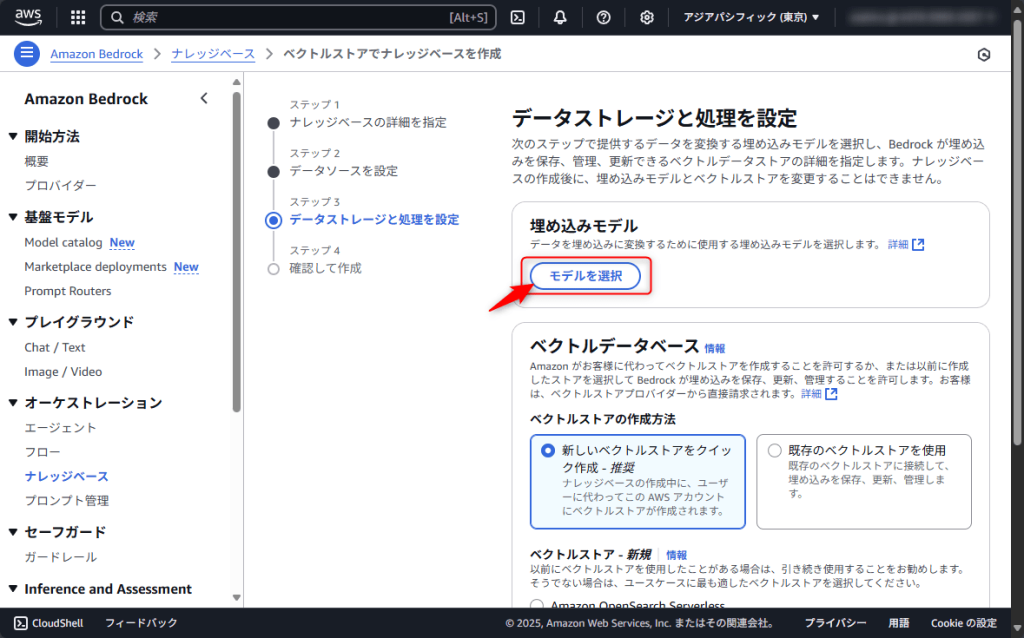
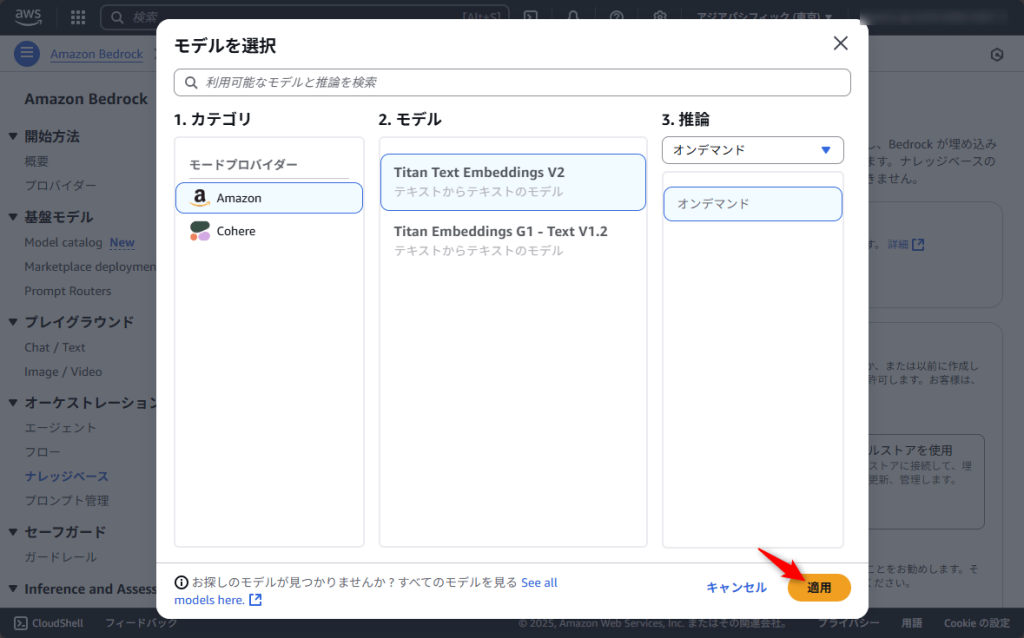
今回は「Titan Text Embeddings V2」を選択しました。
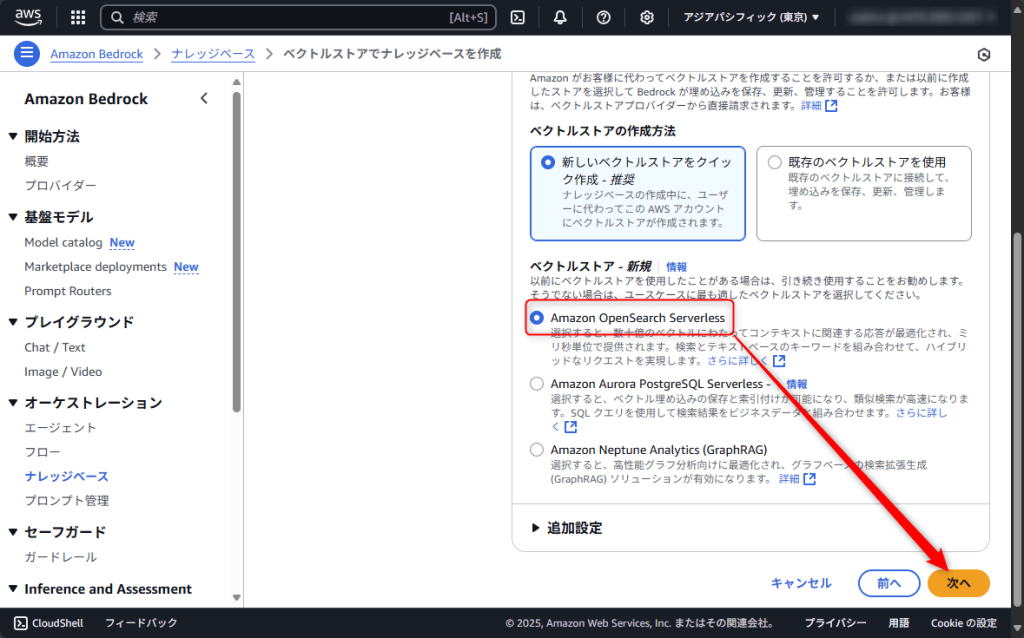
新しいベクトルストアを「Amazon OpenSearch Serverless」で作成します。
最後に入力内容を確認して「ナレッジベースを作成」ボタンをクリックしてください。
ナレッジベースの作成が完了するまでには数分ほどかかります。
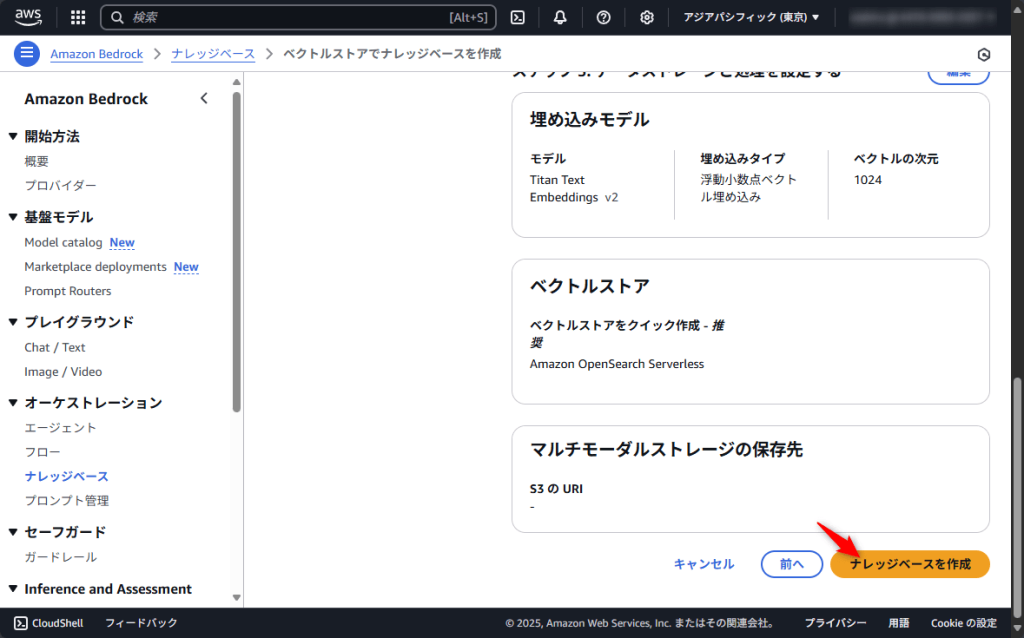
作成が完了したらステータスが「利用可能」となっていることを確認し、名前をクリックします。
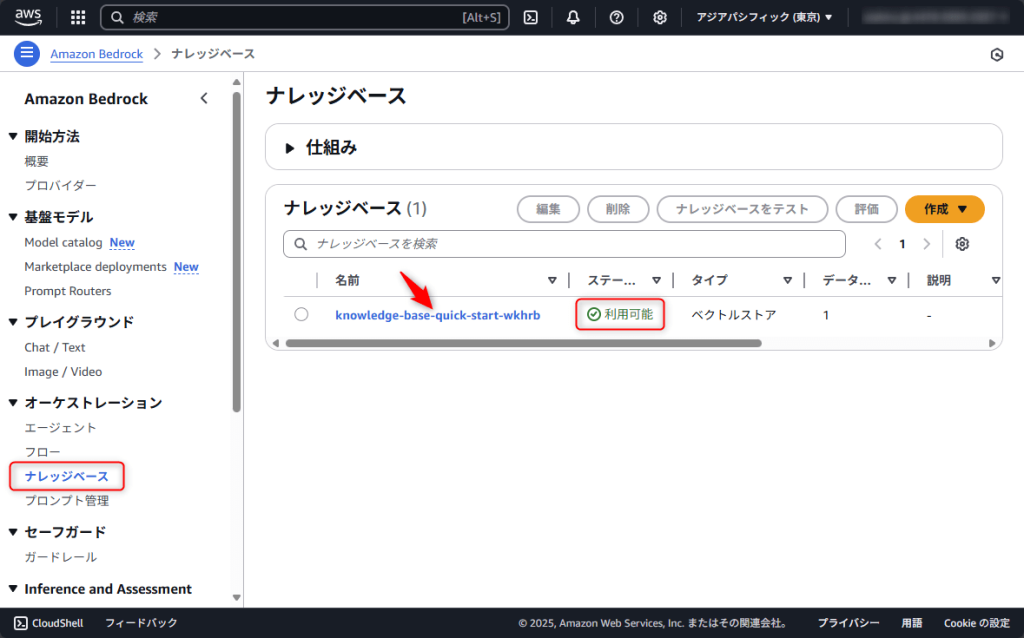
同期しないと利用できないため、データソースにチェックを入れて「同期」ボタンをクリックしてください。
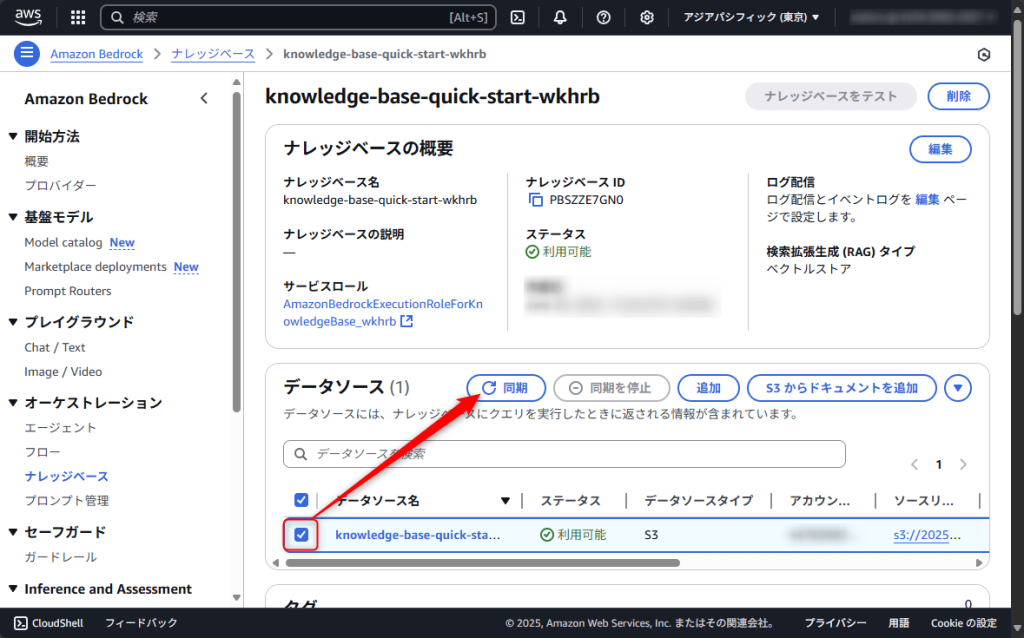
「データソースの同期が完了しました」と表示されるまで待ちます。
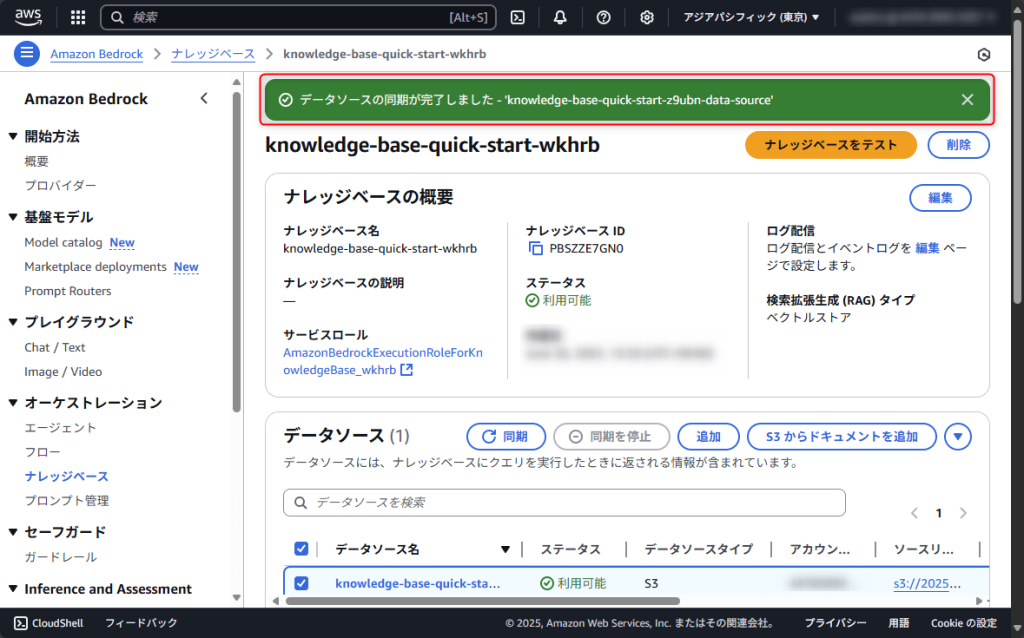
ナレッジベースの準備ができたため、実際にテストしてみましょう。
「ナレッジベースをテスト」ボタンをクリックします。
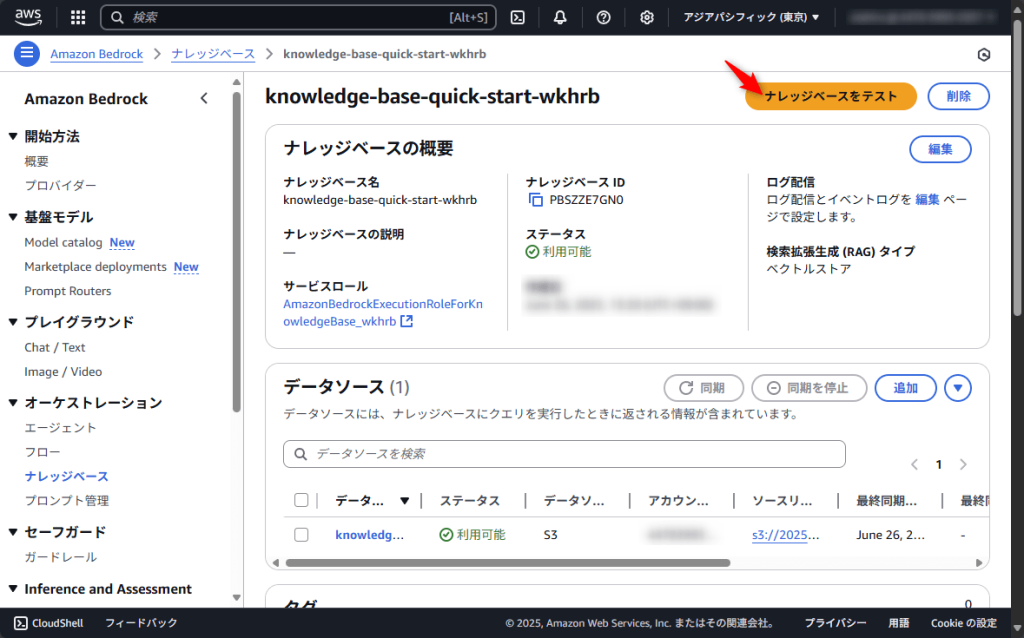
「取得と応答生成:データソースとモデル」を選択します。
今回使用するモデルは「Nova Micro」とし、日本の総人口について質問してみます。
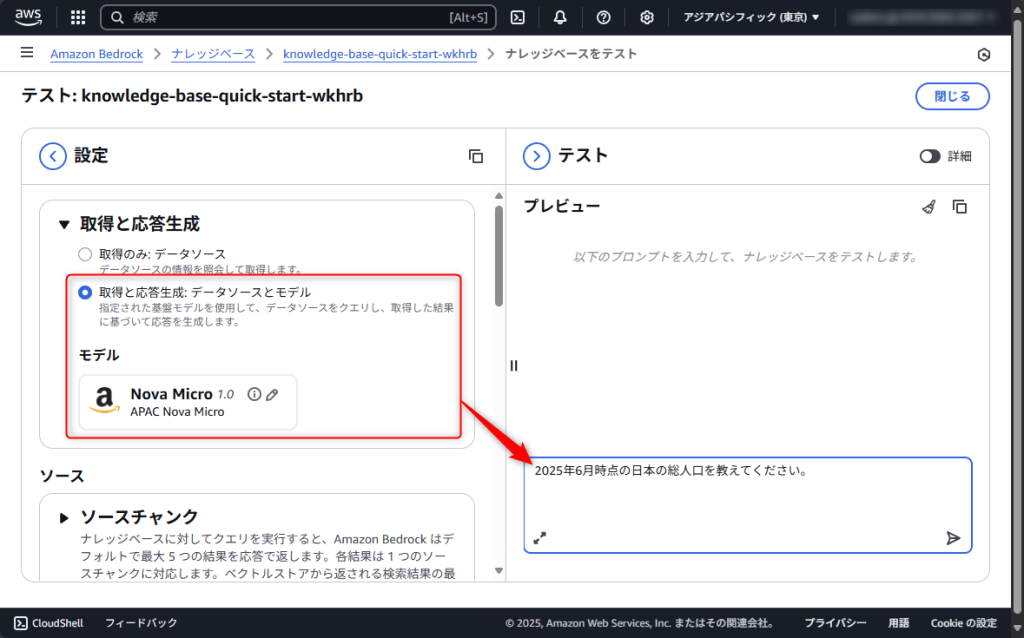
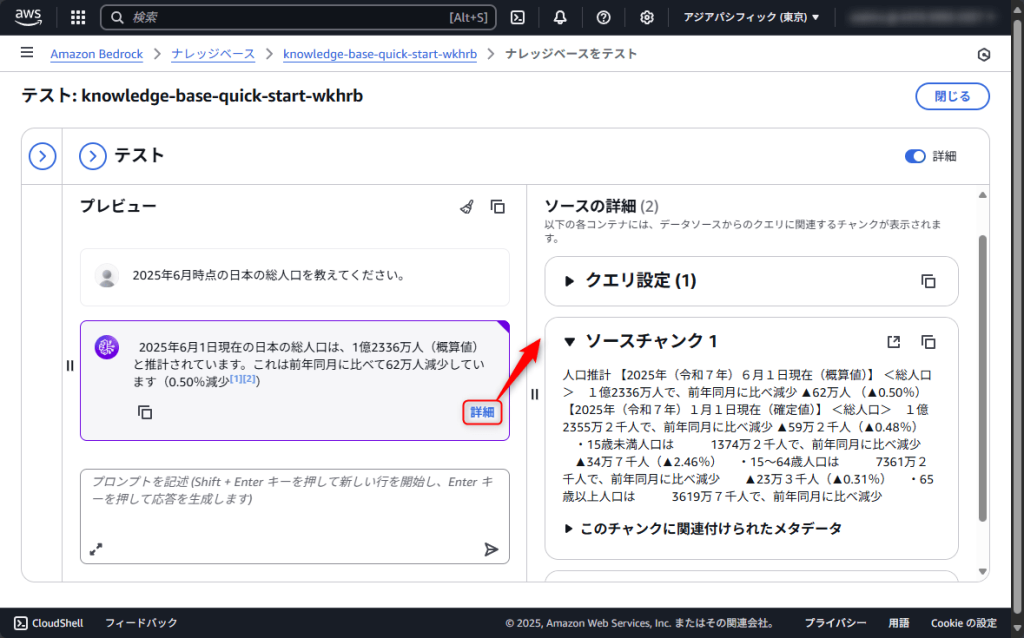
先ほど作成したナレッジベースをもとに回答が生成されていることが確認できます。
回答の「詳細」リンクをクリックすることで、ソースも確認することが可能です。
Amazon Bedrock利用時の注意点
業務で活用する際は、以下のポイントに注意が必要です。
・用途、目的に合わせたモデル選定
・セキュリティとプライバシーの確保
・コスト管理の徹底
それぞれ簡潔に解説していきます。
用途、目的に合わせたモデル選定
Amazon Bedrockは、AmazonをはじめAnthropic、Meta、Mistral AI、Cohereなど多くの業界リーダーによる多様な基盤モデルを選択できます。モデルごとにテキスト生成、画像生成、コード生成、多言語対応など強みや用途が異なり、応答速度、精度などのパフォーマンス要件も異なります。
そのため、用途や予算、将来の拡張性を踏まえて最適なモデルを選ぶことが重要です。モデル評価機能を活用すれば、実際のデータで複数モデルを比較し、最適な選定ができます。
セキュリティとプライバシーの確保
機密情報や個人情報を扱う場合は、IAMによる厳格なアクセス制御を設定し、必要最小限の権限付与を徹底しましょう。また、データの暗号化やCloudTrailなどを活用して監査ログを取得し、不正アクセスや操作履歴を定期的に確認することも重要です。
加えて、GDPRや国内の個人情報保護法など、各種プライバシー規制に準拠した運用を心がけ、企業のリスクを最小限に抑えましょう。
コスト管理の徹底
原則、従量課金制のため利用状況に応じたコスト管理が必要です。無駄なリソース利用を防ぐために、AWS Cost ExplorerやCloudWatchでの定期的なモニタリングや、予算アラートの活用が推奨されます。予算に応じて最適なプランやリソースを選定し、運用コストの最適化を図ることが重要です。
Amazon Bedrockを使って生成AIをビジネスに活かそう
Amazon Bedrockは、AWSが提供するマネージド型生成AIサービスとして、多様な基盤モデルを選択でき、他のAWSサービスと連携しやすい点が大きな魅力です。用途やコスト、精度に応じて最適なモデルを選定できるため、業務効率化や新規サービス開発に役立ちます。
導入する際は、セキュリティやプライバシー、コスト管理などに十分注意しましょう。この記事では、使い方も簡単に解説したため、まずは一度試してみてはいかがでしょうか。
より詳しくAmazon Bedrockについて学びたいという方には、Udemyの動画講座がおすすめです。
◆【AWS】Amazon Bedrockによる生成AIウェブアプリ構築(AIエージェント編)
レビューの一部をご紹介
評価:★★★★★
コメント:説明が図解と共に解説される為理解しやすく、初心者に優しいです。
評価:★★★★★
コメント:自然な話し方で内容もわかりやすく私にとってはとても聞きやすかったです。特にAIエージェントに関する説明は私みたいな初心者にはスッと中身が入ってくる内容でした。コースも2時間なので飽きずに一気に見ることができました。AIエージェントの概要を身に着けるにはちょうど良いコースだと思います。
Amazon BedrockのGenUを利用し、実際にAIエージェントを構築する手法を学びましょう!

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中