

Pythonで株価の分析や予測をしたいものの、
・機械学習の実装方法が分からない…。
・データの取得や可視化の方法が知りたい…。
という方も多いのではないでしょうか。そこでこの記事では、
・株価の分析に必要な専門用語や役立つライブラリ
・Pythonで予測モデルを構築し株価を分析する方法
について解説します。
Pythonによる機械学習の実装が初めての方でも、この記事を読めば、株価の予測方法が学べます。
公開日: 2024年4月9日
\文字より動画で学びたいあなたへ/
Udemyで講座を探す > 監修
監修
専門領域:AI、データサイエンス、デジタルマーケティング、プログラミング
ウマたん (上野佑馬)
「データサイエンスやAIの力でつまらない非効率を減らしおもしろい非効率を増やす」がビジョンのWW inc.の代表取締役社長。日系大手→外資系→AIスタートアップでデータ分析やデジタルマーケティングを経験。多くの人にもっとデータサイエンスを身近に感じてもらうべく月に10万人が訪れる「スタビジ」というメデイアでデータサイエンスの面白さを発信中。著書に「データサイエンス大全」「漫画でわかるデジタルマーケティング×データ分析」など。
…続きを読むPythonを使った株価分析・予測の準備
Pythonには、株価の分析や予測を行うための機能が数多く備わっています。Pythonを使ったデータの加工処理や機械学習の実装方法を学ぶことで、株価の分析や予測が可能です。
ここでは、株価の分析・予測を行うための準備や、押さえておきたい専門用語について解説します。
Pythonの実行環境を準備する
Pythonでプログラミングを行うためには、実行環境を用意する必要があります。Pythonの利用が初めてで、実行環境を構築したことがない方には、「Google Colaboratory」がおすすめです。
「Google Colaboratory」は、サイトにアクセスするだけでインストールなどの作業を行わず、ブラウザ上でPythonのプログラムを作成できます。
PCにPythonの実行環境を構築したい場合は、「Pythonの開発環境の構築方法!最適な統合開発環境(IDE)を解説」を参考にしてください。
必要な専門用語の学習
株価データの取得や分析に取り組む際は、株に関する最低限の専門用語は学んでおきましょう。主な専門用語は次の通りです。
| 用語 | 意味 |
| 銘柄 | 株式を発行する企業の名称 |
| 銘柄コード | 上場企業を区別するための番号 |
| 始値(はじめね) | 取引期間で最初についた株価 |
| 終値(おわりね) | 取引期間で最後についた株価 |
| 高値(たかね) | 取引期間で最も高い株価 |
| 安値(やすね) | 取引期間で最も低い株価 |
| 四本値(よんほんね) | 始値、終値、高値、安値の総称 |
| ローソク足 | 四本値をローソクのような形でチャート上に表したもの |
ライブラリについて知る
Pythonでデータ分析をする際は、データの整理や数値計算を簡単にできるライブラリを使うと便利です。ライブラリは、コードを簡略化や綺麗なグラフの作成にも役立ちます。
データ分析のための代表的なライブラリは、「NumPy」「Pandas」「Matplotlib」などです。
NumPy
数値計算や配列操作を行うためのライブラリで、高度な数学関数が利用できます。NumPyは、機械学習にもよく利用されるプログラミング言語で、大量のデータ処理にかかる時間もNumPyを利用することで短縮できます。
NumPyについて詳しくは、「Pythonの拡張モジュール「NumPy」とは?インストール方法や基本的な使い方を紹介!」をご覧ください。
Pandas
表形式の配列データを扱うライブラリで、データの読み込み切り出し、並び替え、欠損値の保管など様々なデータ処理に役立ちます。Pandasは、データのグラフ化、分析などのコーディングを効率的に行うことができる他、機械学習のプログラミングをする場合にも、学習データの整理に用いられることが多いです。
Pandasについて詳しくは、「【Pandas入門】Pythonのデータ分析ライブラリ「Pandas」を解説!」をご覧ください。
Matplotlib
グラフ描画のためのライブラリで、データを可視化する機能が豊富に備わっています。Matplotlibを利用するれば、簡単なコードで折れ線グラフや棒グラフ・円グラフ・散布図などのさまざまなグラフを描画できます。
Matplotlibについて詳しくは、「Pythonでグラフ描画する方法を解説。Matplotlibを使えば簡単!」をご覧ください。
また、データの予測に役立つ深層学習ライブラリは、「TensorFlow」や「PyTorch」などです。
TensorFlow
Googleが開発した機械学習の高機能なオープンソースライブラリで、分散処理によって大量のデータを学習できます。TensorFlowは、画像認識や音声認識技術に使用されています。
TensorFlowについて詳しくは、「【TENSORFLOW入門】特徴や使い方をわかりやすく解説!」をご覧ください。
PyTorch
PyTorchmも機械学習のオープンソースライブラリで、文法やデータ構造がPythonに似ているため、機械学習の初心者でも扱いやすいライブラリです。
Pytorchについて詳しくは、「【入門編】PyTorchとは何か?インストールから実装までわかりやすく解説」をご覧ください。
\文字より動画で学びたいあなたへ/
Udemyで講座を探す >株価データを取得する方法
株価データは、「Stooq」または「Yahoo!」のサイトから無料でダウンロードできます。CSVデータをダウンロードするか、ライブラリを用いてPythonでデータを取得することも可能です。
ここでは、StooqとYahoo!から株価データを取得する方法を紹介します。
Stooqでの株価取得方法
Stooqから株価データを取得するPythonコードの例は次の通りです。
#ライブラリをインポート
|
1 2 3 4 |
import os import datetime as dt import pandas_datareader.data as web |
#銘柄コードを9783に指定
|
1 2 |
stock_code="9783" stock_code_dr=stock_code + ".JP" |
#2023年9月1日から今日までを指定
|
1 2 |
first='2023-09-01' last = dt.date.today() |
#株価データを取得
|
1 |
df = web.DataReader(stock_code_dr, data_source='stooq', start=first,end=last) |
#csvデータとして保存
|
1 |
df.to_csv('stockdata_stooq.csv') |
コードの冒頭で、データを取得するためのライブラリとして「pandas_datareader」、日付のデータフレームを扱うライブラリとして「datatime」をインポートしています。
「pandas_datareader」で1つ目の引数にターゲットとなる銘柄コードを指定することで、株価データの取得が可能です。今回は「9783」の銘柄コードで、2023年9月1日から2024年3月14日までの時期の株価データをCSVデータとして取得しました。
データ内には「Date(日付)」や「Open(始値)」、「High(高値)」などの情報が含まれます。
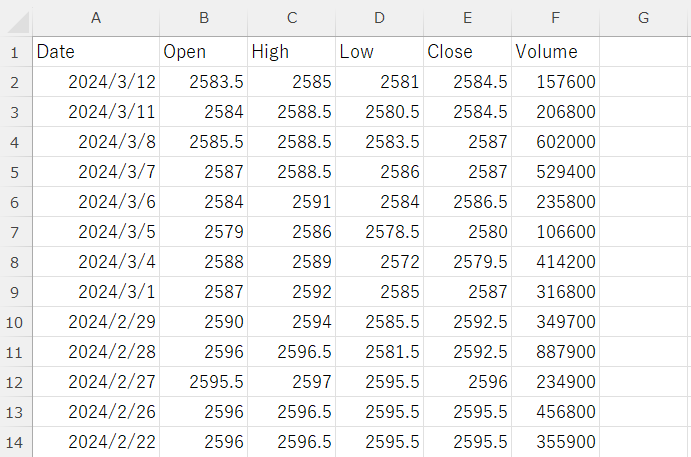
Yahoo!での株価取得方法
Yahoo!から株価データを取得するコードの例は次の通りです。
#ライブラリをインポート
|
1 2 3 4 5 |
import os import datetime as dt import pandas as pd import yfinance as yf |
#銘柄コードを9783に指定
|
1 2 |
stock_code="9783" stock_code_dr=stock_code + ".T" |
#2023年9月1日から今日までを指定
|
1 2 |
first='2023-09-01' last = dt.date.today() |
#株価データを取得
|
1 |
df = yf.download(stock_code_dr, start=first, end=last) |
#csvデータとして保存
|
1 |
df.to_csv('stockdata_yahoo.csv') |
データを取得するためのライブラリとして、Yahoo! Financeから情報を取得できるAPI「yfinance」を使用しています。日付の指定に「datetime」を使用している点は、Stooqからのデータ取得と同様です。
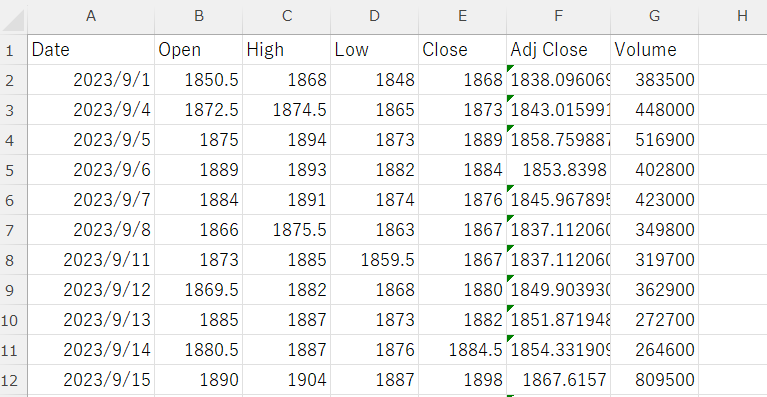
「yf.download」の1つめの引数にターゲット企業の銘柄コードを入力し、次のようなデータを取得できました。
Pythonで株価を分析・予測する方法
次に、取得した株価データを分析し、株価を予測するためのコードを作成しましょう。株価データの可視化や整理、予測モデルの構築を行う流れは次の通りです。
株価データを可視化
StooqやYahoo!から取得した株価データを確認すると、日付や株価などの値が各カラムに設定されたデータフレームであることがわかります。データの変動を視覚的に把握するために、Matplotlibなどのライブラリを用いてグラフ化しましょう。
Matplotlibを利用してグラフを描画する方法は「Pythonでグラフ描画する方法を解説。Matplotlibを使えば簡単!」で詳しく解説しているので、参考にしてみてください。
横軸を日付、縦軸を株価にした折れ線グラフを使うと、株価の変動を時系列で可視化できます。グラフ化のためのコード例は次の通りです。
#ライブラリをインポート
|
1 2 3 4 5 |
import os import datetime as dt import pandas_datareader.data as web import matplotlib.pyplot as plt |
#銘柄コードを9783に指定
|
1 2 |
stock_code="9783" stock_code_dr=stock_code + ".JP" |
#2023年9月1日から今日までを指定
|
1 2 |
first='2023-09-01' last = dt.date.today() |
#株価データを取得
|
1 2 |
df = web.DataReader(stock_code_dr, data_source='stooq', start=first,end=last) |
#データを日付順に並び変え
|
1 |
df.sort_values(by='Date', ascending=True, inplace=True) |
#グラフ化する株価のカラムのみを抽出
|
1 |
df_graph = df[['Open', 'High', 'Low', 'Close']] |
#折れ線グラフを描画
|
1 |
df_graph.plot(kind='line') plt.show() |
コードを実行すると、次のようなグラフが描画されます。
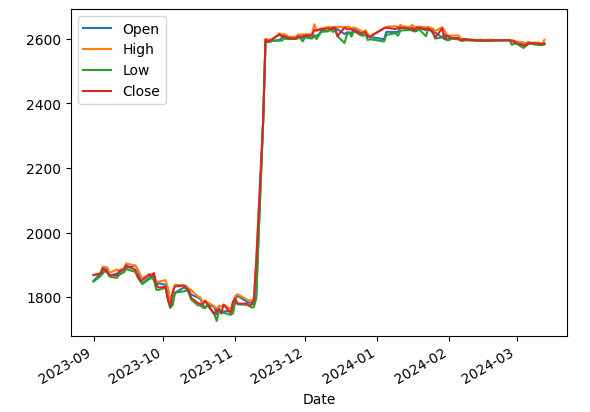
株価を可視化したところ、2023年11月に大きな変動があったことがわかりました。通常と異なる激しい変化は機械学習の精度に影響します。そのため、予測モデルを構築する際は2023年12月以降のデータを用いることにします。
データの整理・特徴量の追加
予測モデルの精度を高めるために、株価のデータを整理します。データの加工はエクセルなどのツールでも可能ですが、情報量が多いためプログラムで処理したほうが効率的です。株価データを取得したプログラムにコードを追加し、予測モデルを構築するための準備を行いましょう。
株価の予測精度を高めるための特徴量として、「翌日と当日の終値の差分」「終値の前日比」「始値と終値の差額」をデータフレームに追加します。下記のコード例のように「shift」というメソッドを使用することでカラムの情報をずらし、前日との差分などの計算が可能です。
#日付のカラムを追加、Volumeのカラムを削除
|
1 2 3 4 |
df['Date'] = df.index df = df.reset_index(drop=True) df = df.drop('Volume', axis=1) |
#月曜を0、日曜を6として曜日情報をデータフレームに追加
|
1 |
df['weekday'] = df['Date'].dt.weekday |
#週番号をデータフレームに追加
|
1 |
df['weeknumber'] = df['Date'].dt.week |
#日付順に並び変え
|
1 |
df.sort_values(by='Date', ascending=True, inplace=True) |
#翌日と当日の終値の差分を計算しデータフレームに追加
|
1 2 |
df_shift = df.shift(-1) df['diff_Close'] = df_shift['Close'] - df['Close'] |
#翌日の終値が当日の終値よりも高ければ1、低ければ0として目的変数のカラムを追加
|
1 2 3 4 |
df['Increase'] = 0 df['Increase'][df['diff_Close'] > 0] = 1 df = df.drop('diff_Close', axis=1) |
#終値の前日比を計算しデータフレームに追加
|
1 2 |
df_shift = df.shift(1) df['Close_rate'] = (df['Close'] - df_shift['Close']) / df_shift['Close'] |
#始値と終値の差額をデータフレームに追加
|
1 |
df['Trunk'] = df['Open'] - df['Close'] |
今回作成するモデルでは、月曜日から木曜日までの終値の変化を学習し、金曜日の終値が上がるかどうかを予測します。しかし、週によっては祝日や年末年始などが含まれ、月曜日から金曜日までの5日分のデータが揃いません。
株取引が行われない日を含む週のデータがあると精度が下がるため、次のようなコードでデータフレームから削除しておきます。
#データフレームから月曜から金曜まで5日分のデータが揃っている週のみを抽出
|
1 2 3 4 5 6 7 |
list_weeknumber = [] list_weeknumber = df['weeknumber'].unique() df['week_count'] = 0 for i in list_weeknumber: df['week_count'][df['weeknumber'] == i] = len(df[df['weeknumber'] == i]) df = df[df['week_count'] == 5] |
また、予測モデルの学習には月曜日から木曜日のデータのみを使用するため、金曜日のデータは削除しておきましょう。同時に、データの整形に利用した不要なカラムも削除します。
#データフレームから予測モデルの学習に使用しない情報を削除
#金曜日のデータを削除(月~木だけを残す)
|
1 |
df = df[df['weekday'] != 4] |
#データの整形に利用したカラムを削除
|
1 |
df = df.drop('weeknumber', axis=1) df = df.drop('week_count', axis=1) |
これらのコードを実行すると、データフレームは次のような状態となります。
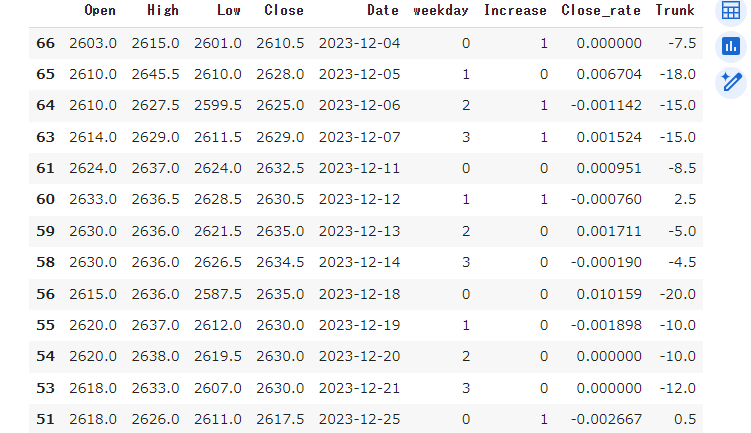
学習データと検証データに分割
次に、準備したデータフレームの中から一定期間のデータを選び出し、予測モデルの構築に使用する学習データと検証データを作成します。
今回は2023年12月1日から2024年2月18日までを学習データ、2024年2月19日から2024年3月14日までを検証データに指定しました。
より多くのデータを学習して精度を高めるため、学習データの日数が多くなるように期間を設定しています。
#2023年12月1日から2024年2月18日までのデータを学習データとして指定
|
1 |
df_learn = df[(df['Date'] >= '2023-12-01') & (df['Date'] <= '2024-02-18')] |
#2024年2月19日から2024年3月14日までのデータを検証データとして指定
|
1 |
df_verify = df[(df['Date'] >= '2024-02-19') & (df['Date'] <= '2024-03-14')] |
続いて、学習データと検証データのそれぞれについて、目的変数と説明変数に分けたデータフレームを作成します。
目的変数とは予測の対象となる変数で、今回の場合は翌日の終値が前日よりも上がるかどうかを示す「Increase」のことです。説明変数とは、目的変数に影響を与える変数で、「Increase」以外のカラムが該当します。
#学習データを目的変数(Increase)と説明変数(Increase以外)に分ける
|
1 2 |
obj_learn = df_learn['Increase'] exp_learn = df_learn[['weekday', 'High', 'Low', 'Open', 'Close', 'Close_rate', 'Trunk']] |
#検証データを目的変数(Increase)と説明変数(Increase以外)に分ける
|
1 |
obj_verify = df_verify['Increase'] exp_verify = df_verify[['weekday', 'High', 'Low', 'Open', 'Close', 'Close_rate', 'Trunk']] |
学習データと検証データが意図した通りに分けられたかどうかを確かめるために、説明変数の「Close(終値)」をグラフ化して確かめてみましょう。
#学習データと検証データの終値のグラフを表示
|
1 2 3 4 5 |
exp_learn['Close'].plot(kind='line') exp_verify['Close'].plot(kind='line') plt.legend(['exp_learn', 'exp_verify']) plt.show() |
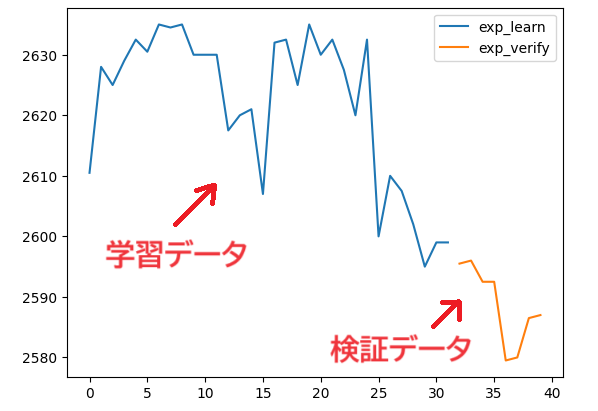
学習データの終値が青色、検証データの終値がオレンジ色のグラフで表示され、データが分けられていることが確認できました。
予測モデルを構築するためには、説明変数と目的変数のデータの大きさや変動幅をある程度揃える必要があります。「sklearn」というライブラリの機能を使うことで、データを標準化し、機械学習の精度を高めることが可能です。次のようなコードを追加し、説明変数と目的変数を揃えましょう。
#標準化のための関数とライブラリをインポート
|
1 2 |
from sklearn.preprocessing import StandardScaler import numpy as np |
#月~木の説明変数をまとめる関数を作成
|
1 2 3 4 5 6 7 8 9 10 |
def std_function(df): df_list = [] df = np.array(df) for i in range(0, len(df) - 3, 4): df_s = df[i:i+4] scl = StandardScaler() df_std = scl.fit_transform(df_s) df_list.append(df_std) return np.array(df_list) |
#説明変数に関数を適用
|
1 2 |
exp_learn_np_array = std_function(exp_learn) exp_verify_np_array = std_function(exp_verify) |
#目的変数の木曜日(週の4日目)のデータだけを含むデータフレームを作成
|
1 2 |
obj_learn_thurs = obj_learn[3::4] obj_verify_thurs = obj_verify[3::4] |
#データフレームを表示
|
1 2 |
print(obj_learn_thurs) print(obj_verify_thurs) |
コードを実行すると、次のようなデータフレームが表示されます。

ここまでの手順で、予測モデルを構築するためのデータの整理は完了です。
予測モデルを構築
Pythonのライブラリには、様々な学習済みのモデルが用意されています。TensorFlowは、予測モデルを構築するための代表的なライブラリです。今回は、TensorFlowの一部である「keras」を用いて、予測モデルを構築しましょう。モデルを構築するコード例は次の通りです。
#予測モデルの構築に必要な機能をインポート
|
1 2 3 4 |
from keras.models import Sequential from keras.layers import Dense, LSTM from keras.layers import Dropout |
#予測モデルの構築とコンパイルするための関数
|
1 2 |
def lstm_comp(df): model = Sequential() |
#入力層を設定
|
1 2 |
model.add(LSTM(256, activation='relu', batch_input_shape=(None, df.shape[1], df.shape[2]))) model.add(Dropout(0.2)) |
#中間層を設定
|
1 2 |
model.add(Dense(256, activation='relu')) model.add(Dropout(0.2)) |
#出力層を設定
|
1 |
model.add(Dense(1, activation='sigmoid')) |
#ネットワークのコンパイル
|
1 2 |
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) return model |
コードの途中にある入力層や中間層、出力層の関数やパラメータを変更することで、予測モデルを編集できます。
構築したモデルを用いて予測
実際の学習データを入力する前に、交差検証と呼ばれる手法で、構築したモデルの精度を確認しましょう。追加するコードの例は次の通りです。
#時系列分割、予測精度算出の機能をインポート
|
1 2 |
from sklearn.model_selection import TimeSeriesSplit from sklearn.metrics import accuracy_score |
#交差検証を繰り返し実行し、結果をリストに格納
|
1 2 3 4 5 6 7 8 9 |
verify_scores = [] tss = TimeSeriesSplit(n_splits=4) for fold, (learn_indices, verify_indices) in enumerate(tss.split(exp_learn_np_array)): exp_learn, exp_verify = exp_learn_np_array[learn_indices], exp_learn_np_array[verify_indices] obj_learn, obj_verify = obj_learn_thurs[learn_indices], obj_learn_thurs[verify_indices] #LSTM構築とコンパイル関数にexp_learnを渡し、変数modelに代入 model = lstm_comp(exp_learn) |
#LSTM構築とコンパイル関数にexp_learnを渡し、変数modelに代入
|
1 |
model = lstm_comp(exp_learn) |
#モデル学習
|
1 |
model.fit(exp_learn, obj_learn, epochs=10, batch_size=64) |
#予測
|
1 |
obj_verify_pred = model.predict(exp_verify) |
#予測結果の値を小数第一位で四捨五入
|
1 |
obj_verify_pred = np.where(obj_verify_pred < 0.5, 0, 1) |
#予測精度の算出と表示
|
1 2 |
score = accuracy_score(obj_verify, obj_verify_pred) print(f'fold {fold} MAE: {score}') |
#予測精度スコアをリストに格納
|
1 |
verify_scores.append(score) |
#交差検証の各回のスコアと平均値を表示
コードを実行すると、次のような形式で、交差検証の各回スコアと平均値が表示されます。
|
1 2 3 4 |
print(f'verify_scores: {verify_scores}') cv_score = np.mean(verify_scores) print(f'CV score: {cv_score}') |
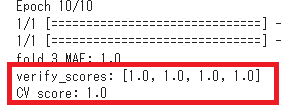
今回はコード内で四捨五入によって0.5(50%)以上のスコアの場合は精度が「1.0」となるように設定しています。4回の交差検証がいずれも「1.0」となり、50%以上の十分な精度で予測できるモデルであることが確認できました。
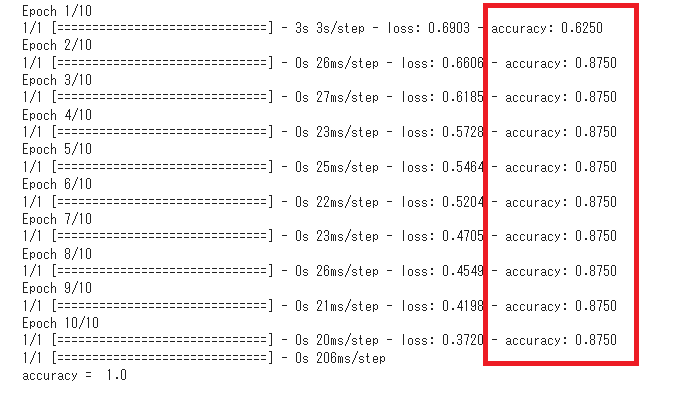
この予測モデルに対して、用意した株価の学習データで学習を実行します。モデルの学習と予測結果の算出を行い、実際の検証データと比較して精度を出力するコード例は次の通りです。
#学習データによる予測モデルの学習を実行
|
1 2 |
model = lstm_comp(exp_learn_np_array) result = model.fit(exp_learn_np_array, obj_learn_thurs, epochs=10, batch_size=64) |
#検証データについて予測し、結果を小数点第一位で四捨五入
|
1 2 |
pred = model.predict(exp_verify_np_array) pred = np.where(pred < 0.5, 0, 1) |
#予測モデルが出力した結果と検証データの目的変数を比較し、精度を算出
|
1 |
print('accuracy = ', accuracy_score(y_true=obj_verify_thurs, y_pred=pred)) |
算出された予測精度の数値が高いほど、予測モデルが参考になるといえます。今回は、コードを実行した結果、0.624~0.875という高い精度で予測できていることがわかりました。
Pythonのライブラリを活用して株価予測をしよう!
Pythonでは、株価データの取得や分析、予測を行うためのプログラムが作成できます。ライブラリを活用すれば、データの処理や学習モデルの構築などを簡単に行うことが可能です。
この記事で紹介したライブラリを活用して、株価予測のためのプログラムを実装しましょう!
Pythonを使った株価データの取得や加工、可視化の方法を詳しく学びたい方には、以下の講座がおすすめです。
【Python×株価分析】株価データを取得・加工・可視化して時系列分析!最終的にAIモデルで株価予測をしていこう!

Pythonの基礎を学んだ後、Pythonによる株価データの取得や加工そして可視化方法を学びます。最終的に株価予測に挑戦いただきLightGBMという機械学習手法で株価を予測していきます!
\無料でプレビューをチェック!/
講座を見てみる講座のレビューを一部紹介
評価:★★★★★
コメント:株価分析のためのライブラリのつかみを理解することができる。各ライブラリについて理解することで、pythonの習得につながると感じました。
評価:★★★★★
コメント:ハンズオンスタイルで受講でき、まさにウマたん先輩が横にいて教えてくれるかのようなリアリティでうなずくことばかりでした。初心者の身としては、非常にハードルが高い内容でしたが前述のハンズオンスタイルで受講できるため、何度も動画を止め、実際に自分で入力して確認するといった手を動かす作業は必須ですが、実りある学習機会となりました。引き続き、ほかの講座も受講し、知見をしっかりと自分の血肉に変えていきたいと思います。
株価分析を楽しみながらPythonやデータ分析力を身につけましょう!

 RANKING
RANKING


 RECOMMENDED COURSE
RECOMMENDED COURSE


最新情報・キャンペーン情報発信中